Search for vTPM-based trusted instances, verify their trusted status in Security Center, and handle trust exceptions or unmeasured states.
View the trusted status of an instance
An integrity measurement benchmark is generated when an instance is created. On subsequent boots, the collected measurements are compared with this benchmark. The comparison result indicates the trusted status and is displayed in the Security Center console.
Go to ECS console - Instances.
In the upper-left corner of the page, select a region and resource group.

-
On the Instances page, click Filter by Tag and select acs:ecs:supportVtpm to filter trusted instances.
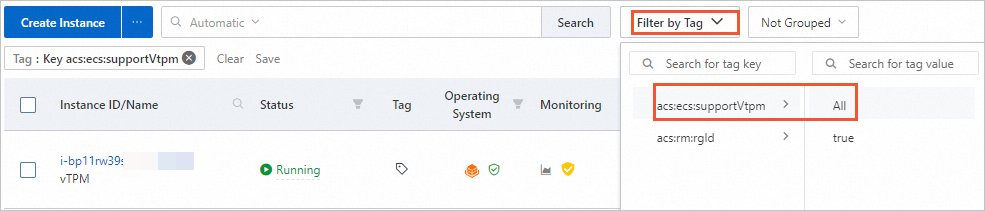
-
Find the target trusted instance and click the
 icon in the Operating System column.
icon in the Operating System column. You are redirected to the Host page in the Security Center console.
-
Click the Trusted information tab to view the trusted status.
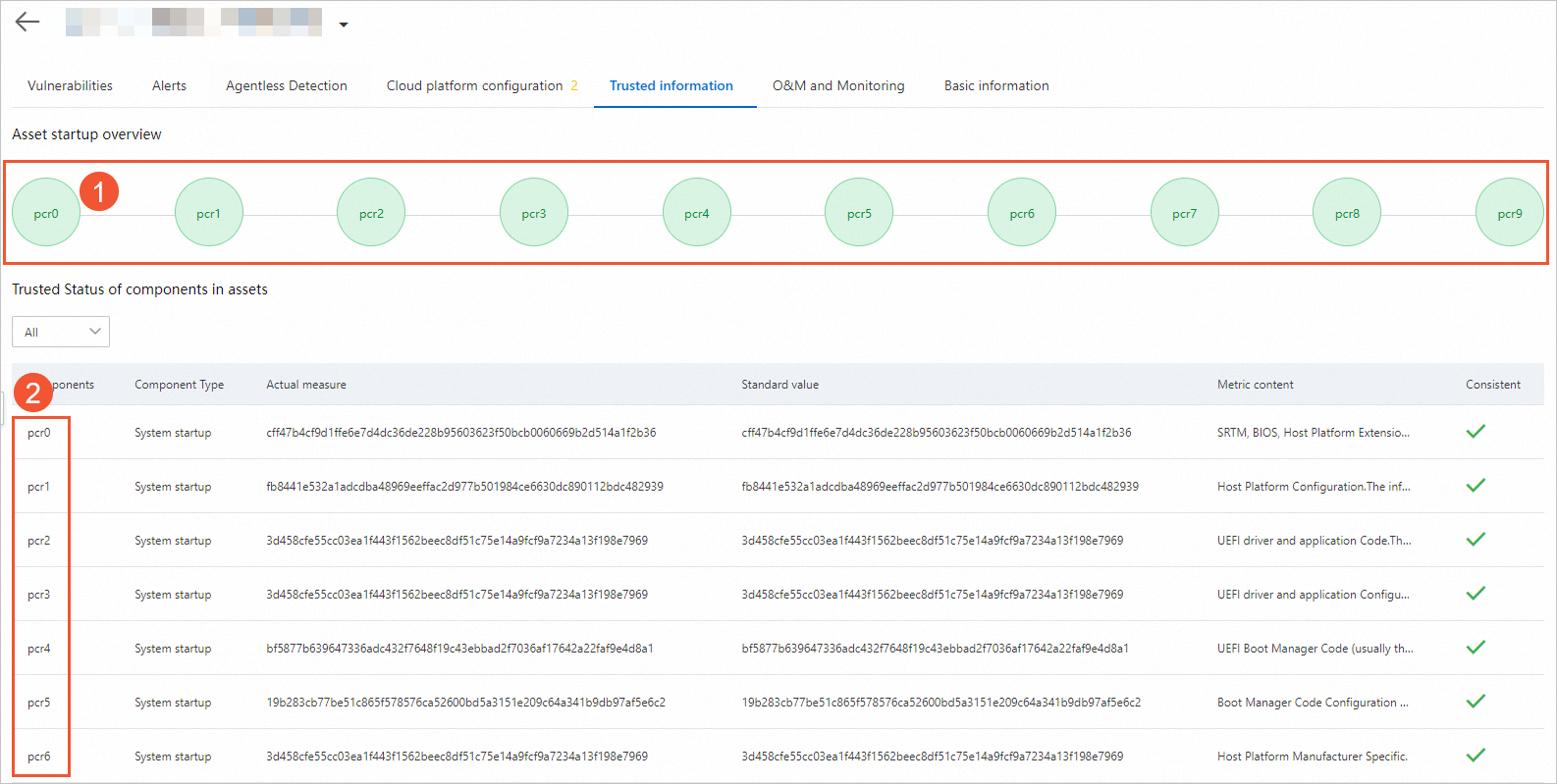
The circles in the ① Asset startup overview section correspond to the components in the ② Trusted Status of components in assets section. Each circle color in the ① Asset startup overview section indicates whether the stage is normal:
-
All green: the boot process is normal. The Actual measure values match the Standard value values.
-
Red at a stage: an error occurred at that stage. Subsequent circles turn gray. View details on the Alerts tab and fix the exception. See Handle trust exceptions.
NoteIf "your device is in the unmeasured state" appears on the Trusted information tab, the instance has not reported valid measurements for a long time and no detailed trust information is displayed. See Handle the unmeasured state.
Platform Configuration Registers (PCRs) are storage units in trusted security devices that store status information collected during the boot process. Each PCR corresponds to a boot stage, and its value represents the measured object's status. If the actual PCR value matches the expected standard value, the stage is considered normal. The following objects are measured at each boot stage:
-
pcr0: the SRTM, BIOS, embedded option ROM, and PI driver.
-
pcr1: host platform configurations.
-
pcr2: UEFI driver and application code.
-
pcr3: UEFI driver, application configurations, and application data.
-
pcr4: UEFI boot management code (typically MBR).
-
pcr5: UEFI boot management code (typically MBR), boot-related data (used by UEFI boot management code), and GPT partition table.
-
pcr6: platform manufacturer-specific UEFI firmware.
-
pcr7: secure boot policy.
-
pcr8: critical commands from configuration files such as grub.cfg and command line information passed to the Linux kernel. Non-critical commands, such as boot menu title definitions, are not measured.
-
pcr9: GRUB module, Linux kernel, and initramfs.
NoteFor detailed definitions, see ISO/IEC 11889:2015 Trusted Platform Module Library.
-
Handle trust exceptions
If a boot stage fails, its circle on the Trusted information tab turns red. Go to the Alerts tab to view the alert details and fix the exception.
-
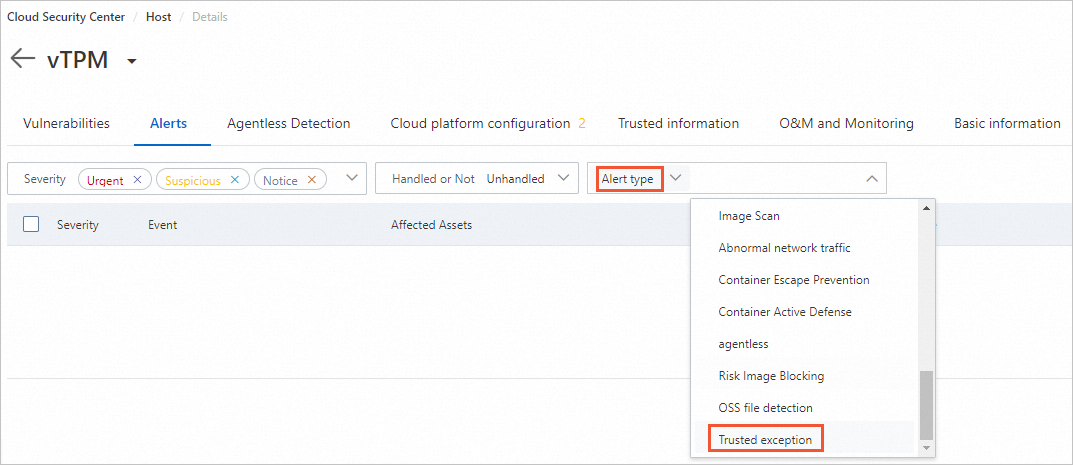
Click the Alerts tab and set Alert type to Trusted exception.
-
Click Details on the right side of the alert to view the error details.
NoteUnhandled alerts are periodically raised, but no new alerts are generated for the same exception. Only the last occurrence time is shown in the Last Occurred At column.
-
Contact the system administrator to check whether recent system upgrade or maintenance operations were performed, such as upgrading the OS kernel, changing boot parameters, or modifying initramfs. Then take one of the following actions based on the result.
-
Scenario 1: No recent system upgrade or maintenance — ignore the alert after checking.
A security event may have occurred on the instance, such as rootkit or bootkit malware. Contact the system administrator to perform an in-depth check, fix the exceptions, and then ignore the alert:
-
Enable the Anti-Virus and Vulnerabilities features in the Security Center console. Upgrade the virus library, scan for malware, and fix any vulnerabilities found.
-
On the Alerts tab, click Process.
-
Select Ignore and click Handle.
To handle the same alert on multiple instances at once, select Handle the same alarms at the same time.
ImportantIgnore alerts remain on the Trusted information tab. Security Center continues to generate alerts periodically until the instance is restarted and passes verification.
-
-
Scenario 2: Recent system upgrade or maintenance — add a whitelist after checking.
After a system upgrade or maintenance, the post-upgrade status becomes the new benchmark. The PCR values at each boot stage also become the new benchmark values. Select Add whitelist.
The whitelisted actual measurement values become the new benchmark values.
-
Handle the unmeasured state
If the Trusted information tab displays "your device is in the unmeasured state", the trusted instance has not reported valid measurements for a long time. This typically occurs because the trust client cannot access the Trusted System service. Troubleshoot as follows:
-
Check the instance RAM role.
-
If no instance RAM role is attached, attach the required one.
-
If an instance RAM role is attached, verify it has access to the Trusted System service. See Create trusted instance.
-
-
Check network connectivity.
Check network connectivity on the trusted instance:
ping trusted-server-vpc.<region-id>.aliyuncs.comReplace <region-id> with the region ID of the trusted instance. A response indicates normal connectivity.
-
Check the security group settings.
Verify the security groups associated with the trusted instance do not deny access to
trusted-server-vpc.[region-id].aliyuncs.com. -
Check the status of the client.
Run
systemctl status t-trustclientto check the client status. If the client is not in therunningstate, runsystemctl restart t-trustclientto restart it.