Answers to common questions when using Elastic Container Instance (ECI) in Container Service for Kubernetes (ACK).
ECI pods
How do I create a GPU-accelerated elastic container instance?
Specify a GPU-accelerated Elastic Compute Service (ECS) instance type when creating the pod. See Create a GPU-accelerated elastic container instance for the full procedure.
How do I find the ID of an elastic container instance?
In ACK, each pod maps to one elastic container instance. Use either of the following methods.
Method 1: kubectl
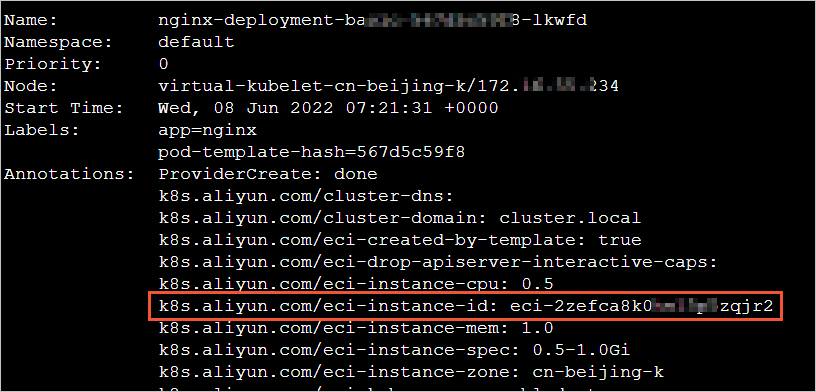
Run the following command and look in the Annotations section of the output:
kubectl describe pod <pod-name>The annotation k8s.aliyun.com/eci-instance-id holds the instance ID in the format eci-xxxx.
Method 2: ECI console
Go to the Elastic Container Instance console and open the Container Group page. Search by pod name — the container group ID is the instance ID, in the format eci-xxxx.

My pod was created with an image cache, but startup still takes more than 10 seconds. Is this expected?
Yes. On a standard node, the scheduler places a pod on an existing node without provisioning new resources, so startup completes in 2–3 seconds. ECI works differently: each pod requires dedicated resource provisioning. If you specify multiple zones, ECI tries each zone in order until it finds one with sufficient capacity, which adds time.
To reduce startup time, list the zone with the most available capacity first in your multi-zone configuration.
My ECI pod has been in the Pending state for hours. What do I do?
Run the following command to check pod events:
kubectl describe pod <pod-name>If the events show an API server connection timeout when mounting a volume, the instance cannot reach the API server. Do one of the following:
Check VPC connectivity — Confirm the pod and the cluster API server are in the same virtual private cloud (VPC).
Update SLB access control — If the cluster's Server Load Balancer (SLB) instance has access control enabled, add the pod's CIDR block to the access control list (ACL).
Scheduling
A pod is scheduled to the virtual-kubelet node but never runs. What do I do?
If the pod events show no updates after scheduling, query the Virtual Kubelet component logs to find the root cause.
kube-proxy and CoreDNS are scheduled to a VNode and fail to start. What do I do?
Kubernetes ignores node taints when scheduling kube-proxy and CoreDNS, so they can land on a VNode. To prevent this, add a nodeAffinity rule to the YAML for both components so they are never scheduled to virtual-kubelet nodes:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: NotIn
values:
- virtual-kubeletNetworking
How do I change the ClusterDomain of an ECI pod?
Add the CLUSTER_DOMAIN environment variable to the container in the Virtual Kubelet component's Deployment. This updates ClusterDomain for all ECI pods created by that component. Submit a ticket to Alibaba Cloud technical support for assistance.
The nginx.ingress.kubernetes.io/auth-url annotation on my ACK Serverless ingress has no effect. Why?
ACK Serverless clusters use SLB-based ingress controllers, which provide load balancing but do not support URL authentication. The nginx.ingress.kubernetes.io/auth-url annotation has no effect in this cluster type.
If you need URL authentication, use a standard ACK cluster instead.
After upgrading my cluster, the service IP address can no longer be pinged. Why?
Before October 2020, service IP addresses were bound to virtual network interface controllers and could be pinged. Starting from October 2020, service IP addresses exist only in IP Virtual Server (IPVS) rules to support high concurrency. IPVS routes traffic by IP address and port number and does not process ICMP packets, so ping no longer works against service IPs.
Logging
I set the aliyun_logs_ environment variable, but no logs appear in Simple Log Service. Why?
Two common causes:
Short container runtime — If the application container finishes within 20 seconds of ECI startup, the container may exit and unmount the log volume before Simple Log Service (SLS) has a chance to collect the logs.
Incorrect log path — When you first configure the aliyun_logs_{Logstore name} environment variable on a pod, ECI automatically creates a Logstore and registers the log path in SLS. All subsequent pods must use the same path. If you use a different path, SLS cannot collect logs from those pods. To use a different path, change the Logstore name at the same time — ECI will create a new Logstore with the new path automatically.
Monitoring
Does Prometheus automatically collect metrics from ECI pods on virtual nodes?
Yes. Virtual nodes are compatible with real nodes, so both ARMS Prometheus and self-managed open source Prometheus automatically collect basic monitoring metrics from ECI pods on virtual nodes. No additional configuration is required.
For setup instructions, see Enable Prometheus Service or Use Prometheus to monitor an ACK cluster.