Standard built-in detection rules cover common data patterns, but they cannot recognize data formats that are unique to your organization — for example, employee IDs, internal project codes, or proprietary account numbers. Data Security Guard can train a machine learning model on your sample data fields to learn their content patterns, then use that learned model to detect similar data across your data assets.
This topic describes how to create and train a custom data identification model and publish it as a detection rule.
Prerequisites
Before you begin, ensure that you have:
-
Access to Data Security Guard. If your Alibaba Cloud account is granted the required permissions, you can directly access the homepage of Data Security Guard. If your Alibaba Cloud account lacks the required permissions, you are redirected to the authorization page of Data Security Guard.
-
Sample data fields that represent the data pattern you want to detect. Each field must contain at least 10 entries. Each entry must be 4–40 characters long and contain only numbers, English letters, or special characters. Chinese characters and Chinese punctuation are not supported.
Create and train a model
-
Go to Data Security Guard.
-
Log on to the DataWorks console. In the top navigation bar, select the region. In the left-side navigation pane, choose Data Development and O&M > Data Development. Select the workspace from the drop-down list and click Go to Data Development.
-
Click the
 icon in the upper-left corner, then choose All Products > Data Governance > Data Security Guard. On the page that appears, click Try Now.
icon in the upper-left corner, then choose All Products > Data Governance > Data Security Guard. On the page that appears, click Try Now.
-
-
In the left-side navigation pane, choose Rule Configuration > Sensitive Data Identification.
-
On the Self-generated Data Identification Models tab, click Create Model.
-
In the Create Model dialog box, configure the model:
-
Model Name: Enter a name for the model.
-
Positive Sample Field: Select one or more fields whose data represents what you want the model to detect. Data Security Guard analyzes the content patterns of these fields to generate a rule model.
NoteThe total sample size across all selected positive sample fields must be between 10 and 10,000 entries. If the total exceeds 10,000 entries, the system randomly selects 10,000 entries for training. If the total sample size is less than 10,000 entries, the system uses all available entries.
-
Negative Sample Field (optional): Select fields whose data should not match the model. This helps improve detection accuracy. If left blank, the system automatically generates negative samples based on the patterns and volume of your positive samples.
-
-
Click Next.
-
Select I accept that Data Security Guard will use samples for model training, then click Start Training. The system randomly extracts up to 100 entries from each selected sample field. Training runs in the background — you can close the dialog box and continue other work while training completes.
Evaluate and publish the model
After training completes, evaluate the model's accuracy before publishing it.
-
On the Self-generated Data Identification Models page, check the training status of your model:
Status Meaning Remaining hh:mm:ss Training is in progress Training Completed Training is done; ready to evaluate Draft Model created but not yet trained; cannot be used for data detection 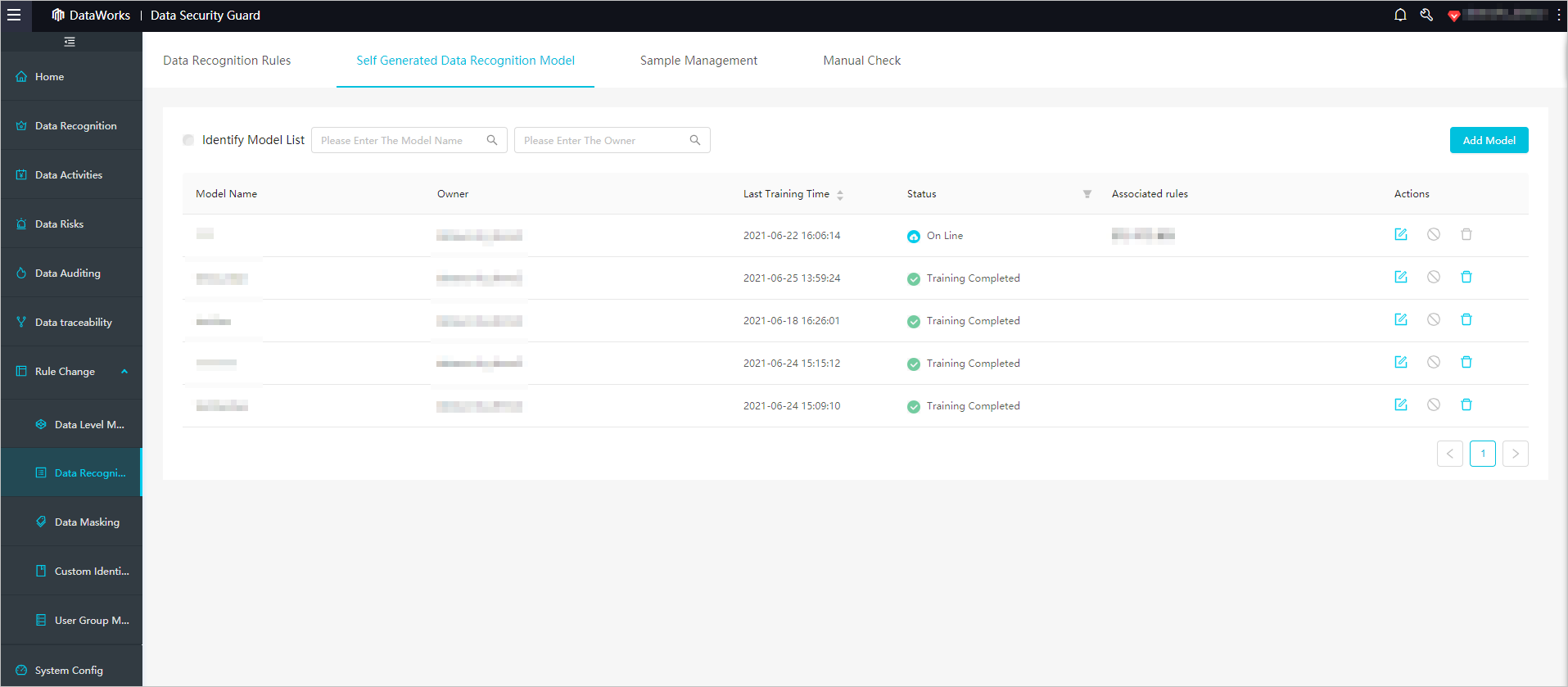
-
After the status shows Training Completed, click the
 icon in the Actions column to view the model's accuracy. Publish the model only when its accuracy reaches 100%. If accuracy is below 100%, detection results may contain significant errors. Add more sample data and retrain the model before publishing.
icon in the Actions column to view the model's accuracy. Publish the model only when its accuracy reaches 100%. If accuracy is below 100%, detection results may contain significant errors. Add more sample data and retrain the model before publishing.
-
Click Create to create the rule model.
Next steps
Go to the Data Identification Rules page to publish the model and run detection tasks. For details, see Configure sensitive data detection rules and run detection tasks.