Data backfill lets you rerun scheduled nodes for a historical or future time range. DataWorks automatically replaces the node's scheduling parameters with values that match the selected business time.
The following diagram shows an example of using data backfill to write incremental data from a MySQL data source to a time-based partition in MaxCompute.
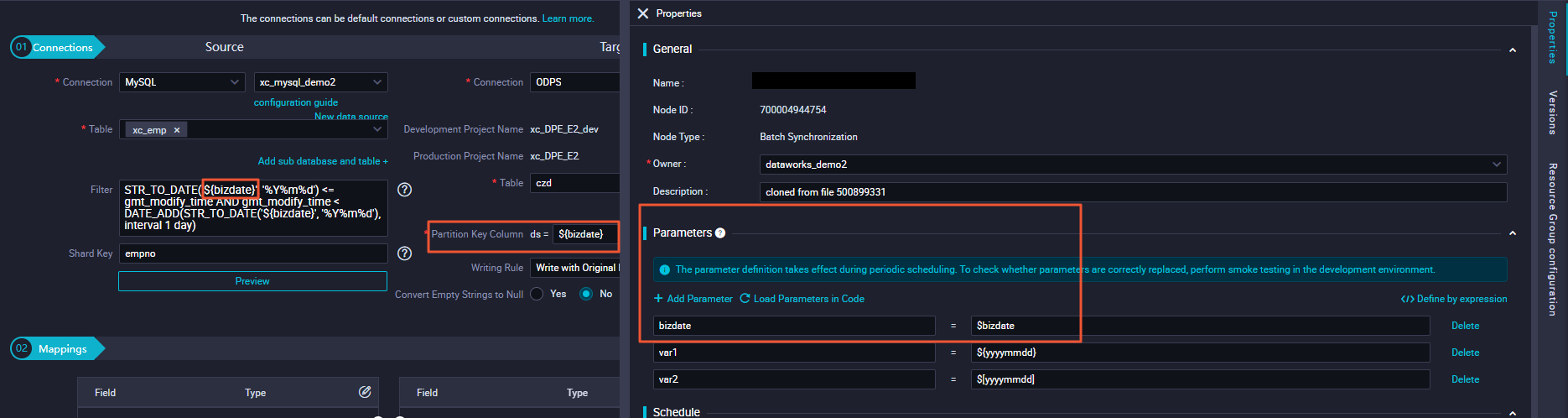
For step-by-step instructions on monitoring and managing backfill instances, see Data Backfill Instance O&M.
Group execution behavior
Group execution controls how many days of backfill instances run in parallel — it does not control concurrency within a single day.
| Mode | Behavior | Best for |
|---|---|---|
| No group execution (default) | Instances for different business dates run one day at a time, sequentially | Nodes with strict data dependencies across dates |
| Group execution (2–5 groups) | Instances for multiple business dates run in parallel groups | Independent daily pipelines where catching up quickly matters more than strict ordering |
For hourly and minutely nodes, intra-day concurrency is controlled separately by self-dependency:
-
With self-dependency: All instances within the same day run sequentially, in chronological order.
-
Without self-dependency: All instances within the same day run concurrently.
Example: If you backfill one week of hourly data with self-dependency and set group execution to 3, DataWorks runs up to 3 business dates in parallel — but within each date, instances still run one after another.
For more information about self-dependency, see Scenario 2: Configure scheduling dependencies when a node depends on the result of the previous cycle.
FAQ
Why do backfill instances show a "Waiting for time" status?
When the scheduled time you selected is in the future, DataWorks queues those instances for their configured run time rather than running them immediately.
To run those instances right away, select the option to ignore the scheduled time when you submit the backfill job.
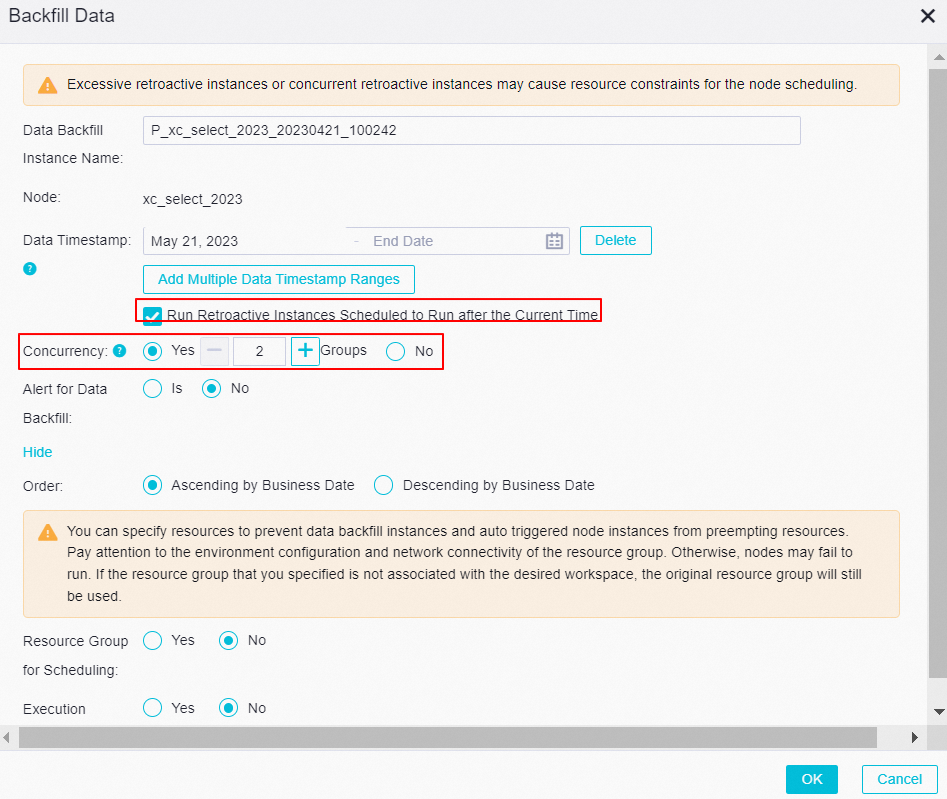
The "Waiting for time" status (shown in yellow) appears only when the business time you selected corresponds to a future scheduled time and you did not select the checkbox to run instances immediately.
Why do instances for yesterday and today both show a "Waiting for time" status?
This is expected. From DataWorks's perspective, data with yesterday's business time is scheduled to run today. Backfilling for a specific business time is equivalent to rerunning the recurring instance for that business time, so its scheduled time is today — which may not have been reached yet.
To confirm this, open the recurring instance panel and filter by yesterday's business time. Those instances have a scheduled time of today.
Why are multiple instances generated when I backfill data from 00:00 to 01:00?
The number of instances depends on how many scheduled run times fall within the selected range, including both endpoints.
-
An hourly node scheduled every hour from 00:00 to 23:59 generates 2 instances for the 00:00–01:00 range (scheduled at 00:00 and 01:00).
-
A minutely node scheduled every 30 minutes from 00:00 to 23:59 generates 3 instances for the 00:00–01:00 range (scheduled at 00:00, 00:30, and 01:00).
Why do instances show a "Waiting for resources" status during large-scale backfills?
Each resource group has a maximum concurrency limit. When backfill instances exceed that limit, the excess instances queue up and show a "Waiting for resources" status (yellow).
Wait until earlier instances complete and free up capacity. For information on monitoring resource usage, see Waiting for Resources.
Why does a backfill job report that the node runtime is outside the selected business time range?
For hourly and minutely nodes, the selected time range must include at least one of the node's configured scheduled run times. If the range contains no valid scheduled time, no instances are generated and the backfill fails.
Select a time range that contains at least one of the node's configured scheduled times.
Why are no instances generated for the node I selected?
Instances are not generated for nodes that are outside their effective period. Check the node's scheduling configuration to confirm that the backfill date falls within its effective period.
How do I backfill data for weekly or monthly nodes?
Select the day before the actual scheduled run date as the business time. This is because business date and scheduled date have a one-day offset:
Business date = Scheduled date − 1 dayOn days other than the scheduled run date, DataWorks generates dry-run instances with the status "Dry-run for weekly/monthly instance" — the task does not execute on those days.
Example: Monthly node
For a node scheduled to run at 00:00 on the first of every month, select the last day of the previous month as the business time.

For more information about the relationship between scheduling parameters, business date, scheduled time, and actual runtime, see Relationships between scheduling parameters, business date, scheduled time, and actual runtime. For more information about dry-run cycles, see Scenario 1: Dry-run cycles for weekly and monthly instances.