Data Integration lets you synchronize entire databases in real time from sources such as MySQL, Oracle, and PolarDB to destinations such as Hologres. This topic provides an example that uses MySQL as the source and Kafka as the destination to describe how to perform a full and incremental synchronization of an entire MySQL database to Kafka.
Prerequisites
Purchase a Serverless resource group or an exclusive resource group for Data Integration.
Create MySQL and Kafka data sources. For more information, see Data Source Configuration.
Establish a network connection between the resource group and the data sources. For more information, see Network Connectivity Solution Overview.
Procedure
1. Select a synchronization task type
Go to the Data Integration page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Integration.
In the left navigation pane, click Synchronization Task. Then, click Create Synchronization Task at the top of the page. Configure the following basic information.
Source:
MySQL.Destination:
Kafka.Task Name: Enter a custom name for the sync task.
Task Type:
Real-time Full Database Synchronization.Sync Procedure:select Full initialization and Incremental synchronization.
2. Configure network and resources
In the Network and Resource Configuration section, select the Resource Group for the sync task. You can allocate CUs under Task Resource Usage.
Set Source to your
MySQLdata source and Destination to yourKafkadata source. Then, click Test Connectivity.
After the connectivity tests for both the source and destination data sources are successful, click Next.
3. Select the databases and tables to synchronize
In the Source Table section, select the source tables that you want to synchronize. Click the ![]() icon to move them to the Selected Tables section on the right.
icon to move them to the Selected Tables section on the right.

4. Map to destination topics
After you select the tables from which you want to synchronize data, the selected tables are automatically displayed in the Mapping Rules for Destination Tables section. The properties of the destination tables are waiting to be mapped. You must manually define mappings between the source tables and destination tables to determine the data reading and writing relationships. Then, you can click Refresh in the Actions column. You can directly refresh mappings between source tables and destination tables. You can also refresh mappings between source tables and destination tables after you configure settings related to destination tables.
Select the tables to synchronize and click Batch Refresh Mapping Results. If a mapping rule is not configured, the default naming rule for destination tables is
${SourceDBName}_${TableName}. If a table with this name does not exist in the destination, a new one is automatically created.In the Custom Mapping Rule for Destination Topic Name column, click the Configure button to set the destination topic naming rule.
You can combine built-in variables and manually entered strings to create the Destination Topic Name. You can also edit the built-in variables. For example, you can create a new topic naming rule that appends a suffix to the source table name to create the Destination Topic Name.
In the Value of Key for Data Write column, click the Configure button to set the write key.
a. Add and assign values to fields for the destination topic
If the status of the destination topic is To Be Created, you can add new fields to it in addition to those from the original table schema. Perform the following steps:
To add fields and assign values for a single table, click the Configure button in the Assign Values To Destination Topic Fields column. On the Additional Fields page, click Add Field to add a field and assign it a value.
To assign values in a batch: Select multiple tables. At the bottom of the list, choose to assign values to the same fields across multiple destination tables.
NoteYou can assign constants and variables. Click the
 icon to switch between assignment modes.
icon to switch between assignment modes.
b. Configure DML processing rules
Data Integration provides default DML processing rules. You can also configure DML processing rules for destination tables based on your business requirements.
Configure DML processing rules for a single destination table: Find the destination table for which you want to configure DML processing rules and click Configure in the Configure DML Rule column to configure DML processing rules for the table.
Configure DML processing rules for multiple destination tables at a time: Select the destination tables for which you want to configure DML processing rules, click Batch Modify in the lower part of the page, and then click Configure DML Rule.
c. Set destination topic properties
Click the  icon in the destination topic name column to set topic properties, such as the Number Of Partitions and Number Of Replicas.
icon in the destination topic name column to set topic properties, such as the Number Of Partitions and Number Of Replicas.
d. Set the source split column
From the drop-down list in the Source Split Column, select a field from the source table or Not Split.
e. Execute full synchronization
If, when you selected the sync task type, you selected the Full Synchronization checkbox in the Synchronization Steps section, you can disable full synchronization for specific tables in this step.
5. Configure alert rules
To prevent the failure of the synchronization task from causing latency on business data synchronization, you can configure different alert rules for the synchronization task.
In the upper-right corner of the page, click Configure Alert Rule to go to the Alert Rule Configurations for Real-time Synchronization Subnode panel.
In the Configure Alert Rule panel, click Add Alert Rule. In the Add Alert Rule dialog box, configure the parameters to configure an alert rule.
NoteThe alert rules that you configure in this step take effect for the real-time synchronization subtask that will be generated by the synchronization task. After the configuration of the synchronization task is complete, you can refer to Run and manage real-time synchronization tasks to go to the Real-time Synchronization Task page and modify alert rules configured for the real-time synchronization subtask.
Manage alert rules.
You can enable or disable alert rules that are created. You can also specify different alert recipients based on the severity levels of alerts.
6. Configure advanced parameters
You can change the values of specific parameters configured for the synchronization task based on your business requirements. For example, you can specify an appropriate value for the Maximum read connections parameter to prevent the current synchronization task from imposing excessive pressure on the source database and data production from being affected.
To prevent unexpected errors or data quality issues, we recommend that you understand the meanings of the parameters before you change the values of the parameters.
In the upper-right corner of the configuration page, click Configure Advanced Parameters.
In the Configure Advanced Parameters panel, change the values of the desired parameters.
7. Configure DDL processing rules
DDL operations may be performed on the source. You can click Configure DDL Capability in the upper-right corner of the page to configure rules to process DDL messages from the source based on your business requirements.
For more information, see Configure rules to process DDL messages.
8. View and change resource groups
You can click Configure Resource Group in the upper-right corner of the page to view and change the resource groups that are used to run the current synchronization task.
9. Run the synchronization task
After the configuration of the synchronization task is complete, click Complete in the lower part of the page.
In the Synchronization Task section of the Data Integration page, find the created synchronization task and click Start in the Operation column.
Click the Name/ID of the synchronization task in the Tasks section and view the detailed running process of the synchronization task.
Sync task O&M
View the task running status
After you create a sync task, you can view a list of your sync tasks and their basic information on the Sync Task page.
In the Operation column, you can Start or Stop a sync task. In the More menu, you can perform other operations, such as Edit and View.
For a running task, you can view its basic status in the Execution Overview section and click an area in the overview to view the execution details.
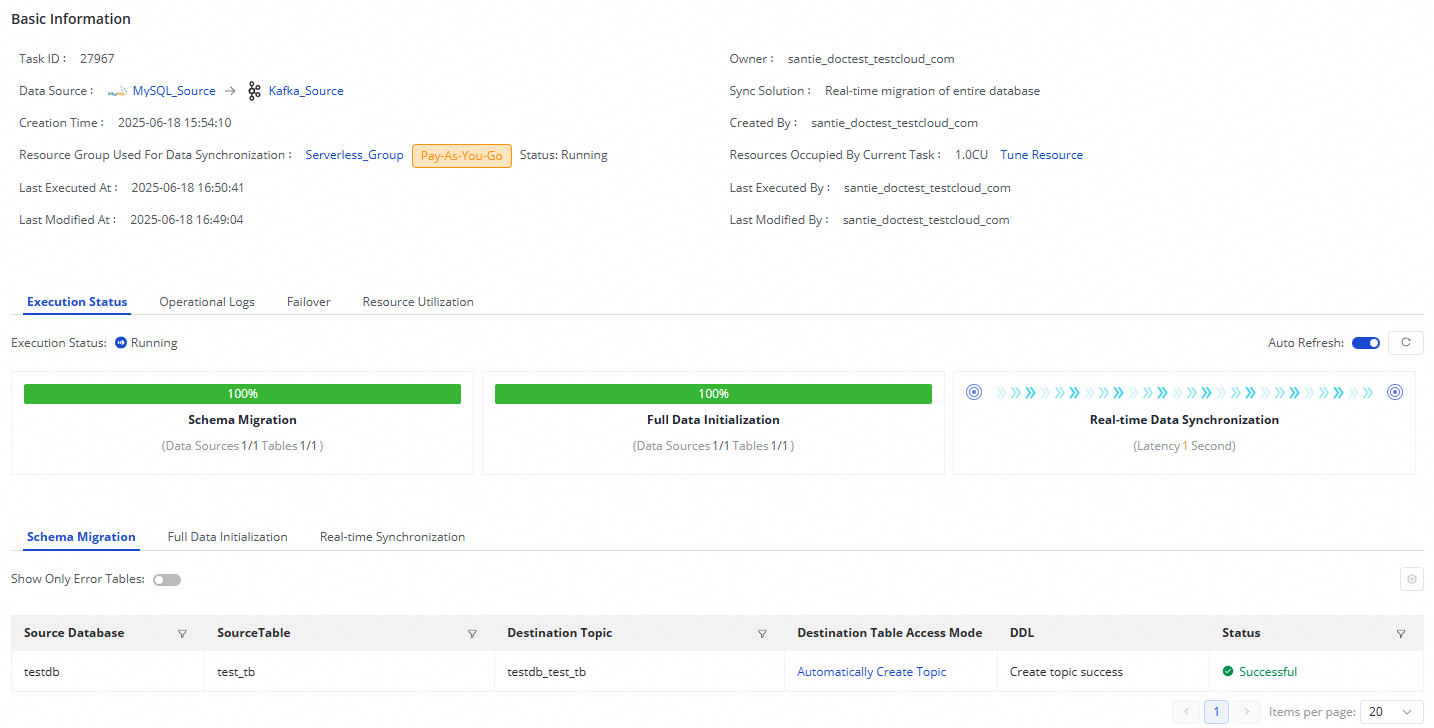
A real-time synchronization task for an entire MySQL database to Kafka consists of three steps:
Schema Migration: Shows how the destination topic is created, either using an existing topic or by automatically creating a new one. If a topic is created automatically, its Data Definition Language (DDL) statement is displayed.
Full Data Initialization: Shows information about the tables synchronized offline, the synchronization progress, and the number of records written.
Real-time Data Synchronization: Shows real-time synchronization statistics, such as real-time progress, DDL records, Data Manipulation Language (DML) records, and alert information.
Rerun the synchronization task
In some special cases, if you add tables to or remove tables from the source, or change the schema or name of a destination table, you can click More in the Operation column of the synchronization task and then click Rerun to rerun the task after the change. During the rerun process, the synchronization task synchronizes data only from the newly added tables to the destination or only from the mapped source table to the destination table whose schema or name is changed.
If you want to rerun the synchronization task without modifying the configuration of the task, click More in the Actions column and then click Rerun to rerun the task to perform full synchronization and incremental synchronization again.
If you want to rerun the synchronization task after you add tables to or remove tables from the task, click Complete after the change. In this case, Apply Updates is displayed in the Actions column of the synchronization task. Click Apply Updates to trigger the system to rerun the synchronization task. During the rerun process, the synchronization task synchronizes data from the newly added tables to the destination. Data in the original tables is not synchronized again.
Appendix: Kafka message format
After you configure and run the real-time sync task, data from the source database is written to Kafka topics in JSON format. The task first writes all existing data from the specified source tables to the corresponding Kafka topics. Then, it starts a real-time process to continuously write incremental data to the topics. Incremental DDL changes from the source tables are also written to the topics in JSON format. For more information about the message format, see Appendix: Message format.
For data written to Kafka by a full synchronization task, the payload.sequenceId, payload.timestamp.eventTime, and payload.timestamp.checkpointTime fields in the JSON structure are all set to -1.