When multiple pipelines share the same SQL logic but operate on different tables, maintaining separate copies of that code creates a maintenance burden: a logic change means updating it in every copy, and copy-paste errors are easy to miss. Script templates solve this by letting you define the SQL logic once and reuse it across pipelines with different input and output tables. This topic describes how to create, reference, and manage script templates in DataWorks.
How it works
A script template works like a function in a programming language: define the logic once, call it repeatedly with different arguments. The template body contains @@{parameter_name} placeholders for variable table names and string values. When an SQL Snippet node references the template and supplies concrete parameter values, DataWorks substitutes the placeholders and generates executable SQL.
For example, a template body might contain:
INSERT OVERWRITE TABLE @@{myoutput} PARTITION (pt='${bizdate}')
SELECT ...
FROM @@{myinputtable}
WHERE r2.rank <= @@{topn};When the SQL Snippet node binds myinputtable to company_sales_record, myoutput to company_sales_top_n, and topn to 10, DataWorks substitutes those values and runs the resulting SQL.
Script templates work exclusively with SQL Snippet nodes. To run a template-based pipeline, create an SQL Snippet node that references the template.
Key concepts
| Concept | Description |
|---|---|
| Script template | A reusable SQL code process with named input and output parameters in @@{parameter_name} format |
| SQL Snippet node | The node type that references a script template and supplies concrete parameter values |
| Input parameter (Table) | Binds a source table to the template. The bound table must have the same number of fields and compatible field types as the parameter definition. |
| Input parameter (String) | Binds a string value or variable to the template, such as a filter threshold or a province name |
| Output parameter | Defines the output table that the SQL code process generates. Must be of type Table. |
| Workspace-level template | Available only to members of the current workspace after deployment |
| Public template | Published to the current tenant so all tenant users can use it |
Parameter definitions are for reference only. DataWorks does not enforce a schema check immediately. Mismatches between the parameter definition and the actual table schema cause a runtime error when the node runs.
Limitations
-
SQL Snippet nodes require DataWorks Standard Edition or a higher edition. For details, see Differences among DataWorks editions.
-
Workspace-level templates appear on the Workspace-Specific tab. Only workspace members can use them.
-
Public templates appear on the Public tab. All users within the tenant can use them.
Prerequisites
Before you begin, ensure that you have:
-
The Development role in the target workspace. To assign roles, see the Add a RAM user to a workspace as a member and assign roles to the member section in "Manage permissions on workspace-level services."
-
DataWorks Standard Edition or a higher edition
Define a script template
Step 1: Open the Snippets pane
-
Log on to the DataWorks console. In the top navigation bar, select the target region. In the left-side navigation pane, choose Data Development and O&M > Data Development. Select the target workspace and click Go to Data Development.
-
In the left-side navigation pane of the DataStudio page, click Snippets.
If Snippets is not visible, click the
 icon in the lower-left corner and follow the instructions in Configure settings in the DataStudio Modules section to add it.
icon in the lower-left corner and follow the instructions in Configure settings in the DataStudio Modules section to add it.
Step 2: Create the template
In the Snippets pane, use the actions shown in the following figure to create and name a script template.
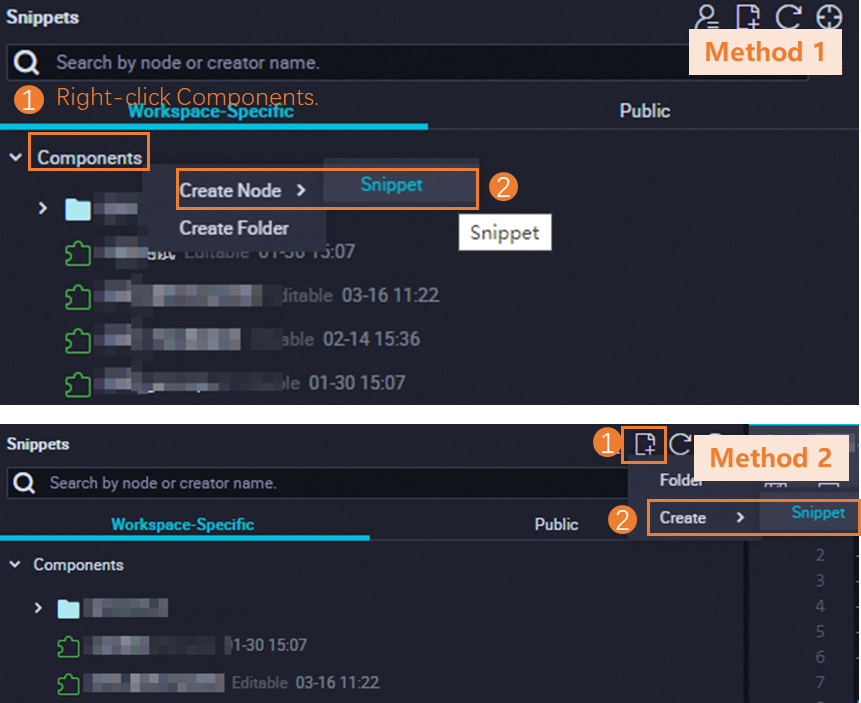
Templates created by member accounts in the current workspace appear on the Workspace-Specific tab. Templates created within the tenant appear on the Public tab.
Step 3: Configure the template
The configuration tab has three parts: the SQL code process, input parameters, and output parameters.
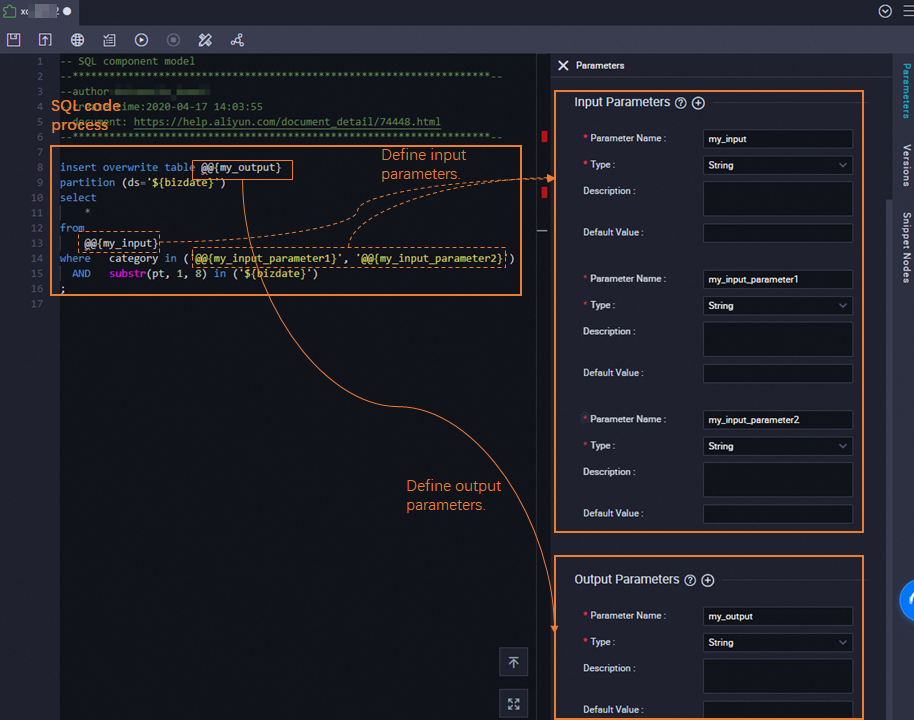
SQL code process
Write the SQL logic in the code editor. Replace variable table names and string values with @@{parameter_name} placeholders. DataWorks substitutes these placeholders with the actual values when an SQL Snippet node runs.
Input parameters
Add one or more input parameters. Each parameter has one of the following types:
-
Table: Binds a source table. Define the expected schema as a text block so that users know what schema to supply. Define the schema in the following format:
Name of Field 1 Type of Field 1 Description of Field 1 Name of Field 2 Type of Field 2 Description of Field 2 ... Name of Field n Type of Field n Description of Field nExample:
area_id string 'Region ID' city_id string 'City ID' order_amt double 'Order amount' -
String: Binds a string value, such as a numeric threshold or a filter condition. Optionally set a default value that is used when no value is supplied at reference time. Use cases:
-
Export the top N cities by sales: use a String parameter to pass the value of N.
-
Filter by province: use a String parameter to pass the province name.
-
Output parameters
Add one or more output parameters of type Table. Define the expected output schema for reference.
Example:
area_id string 'Region ID'
city_id string 'City ID'
order_amt double 'Order amount'
rank bigint 'Ranking'A template can contain multiple input and output parameters.
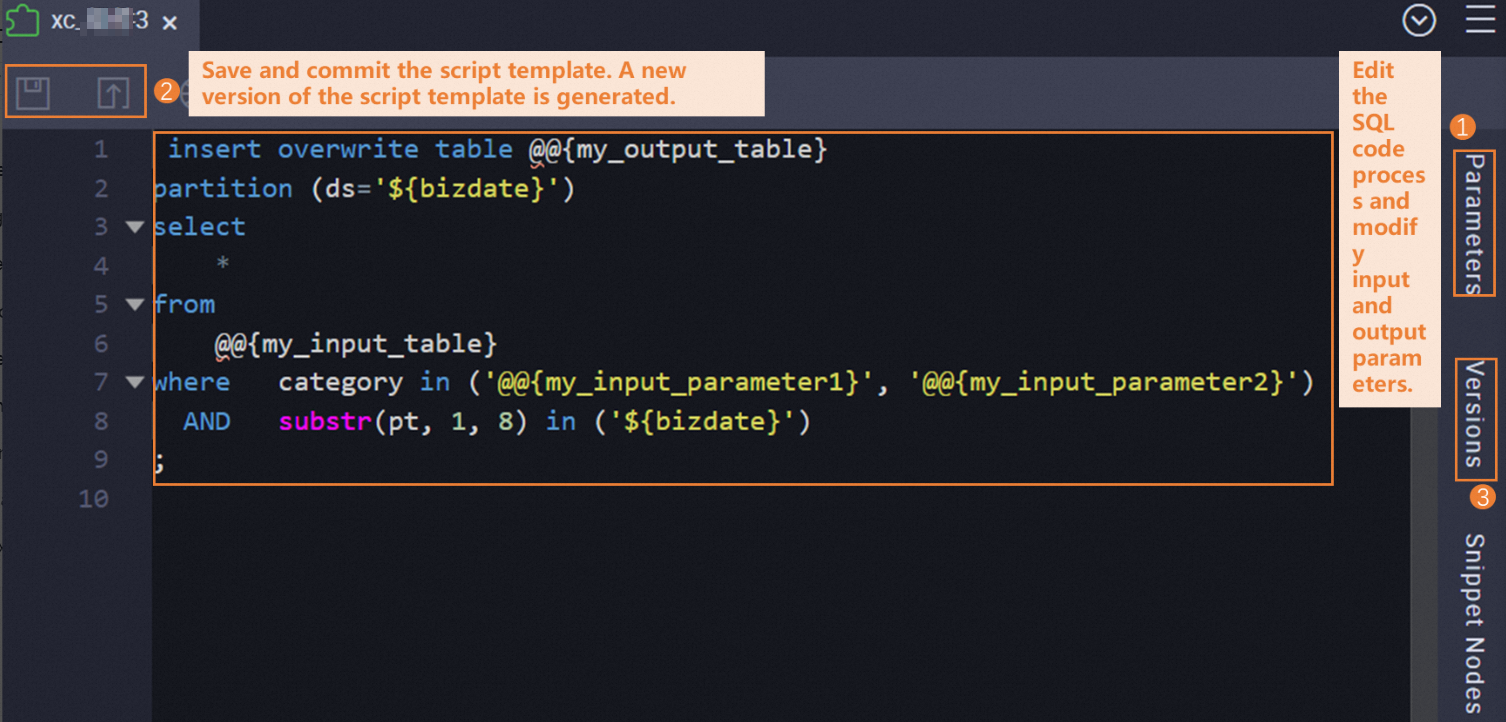
Step 4: Save and commit the template
In the toolbar on the configuration tab, click the ![]() icon to save, then click the
icon to save, then click the ![]() icon to commit. After the template is committed, it is available for SQL Snippet nodes to reference.
icon to commit. After the template is committed, it is available for SQL Snippet nodes to reference.
Reference a script template
Prerequisites
Before you begin, ensure that you have:
-
A created script template. See Define a script template.
-
An SQL Snippet node. See Create and manage ODPS nodes.
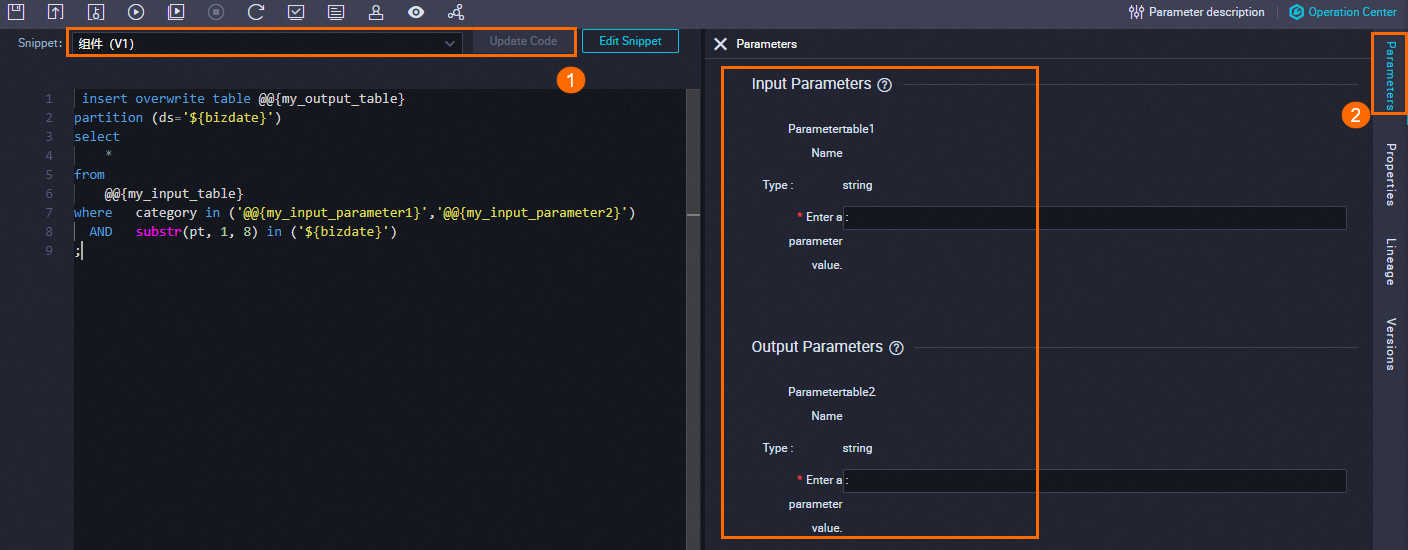
Reference the template
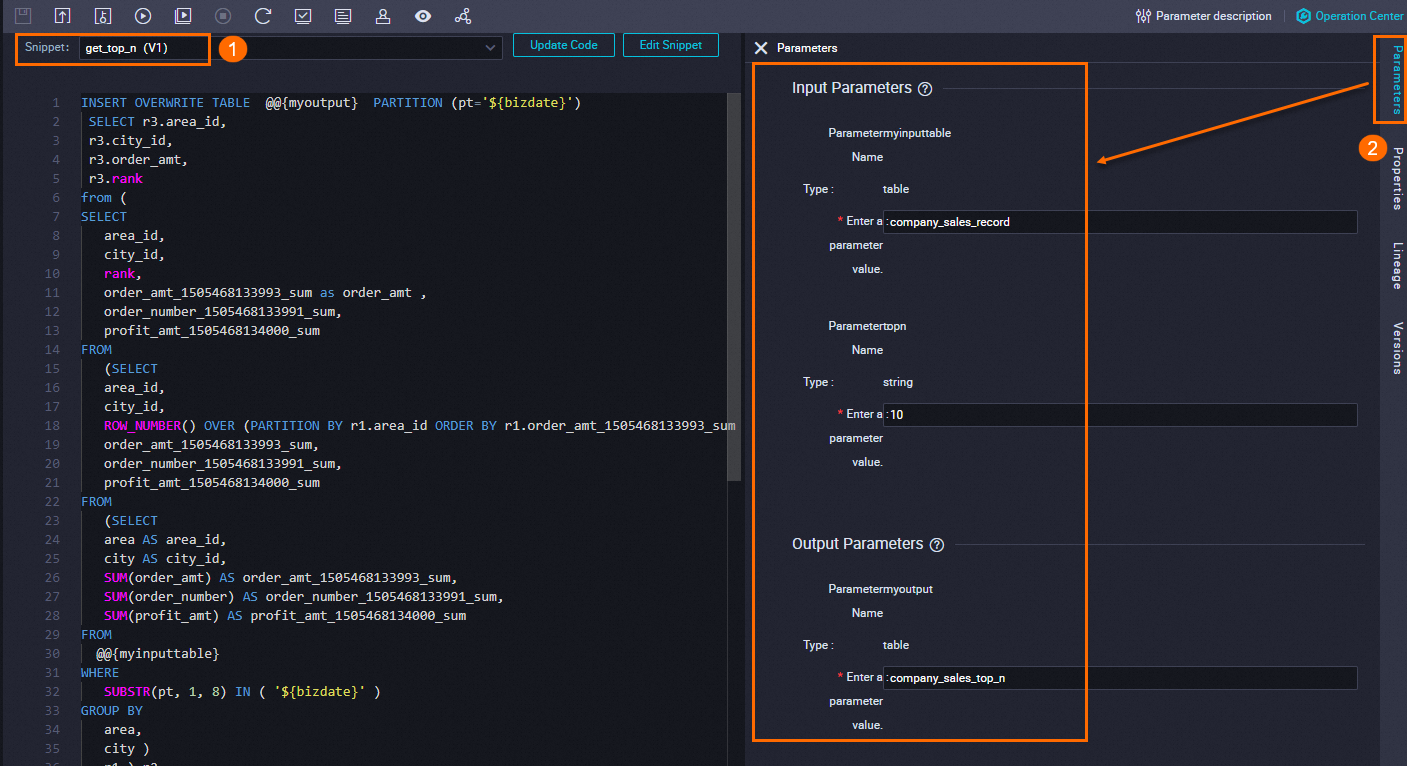
On the configuration tab of the SQL Snippet node, follow the steps in the figure below to select and configure a script template.
-
Select the script template to reference.
-
If a newer version of the template is available, click Update Code to pull it in.
-
To inspect the template definition, click Edit Snippet.
-
-
Configure the input and output parameter values based on your pipeline's tables and requirements.
Manage script templates
Publish a template to all tenant users
After deployment, a template is workspace-level by default. To make it available to all users in the tenant, click the Publish Snippet icon (marked 1 in the figure) in the toolbar on the template's configuration tab.
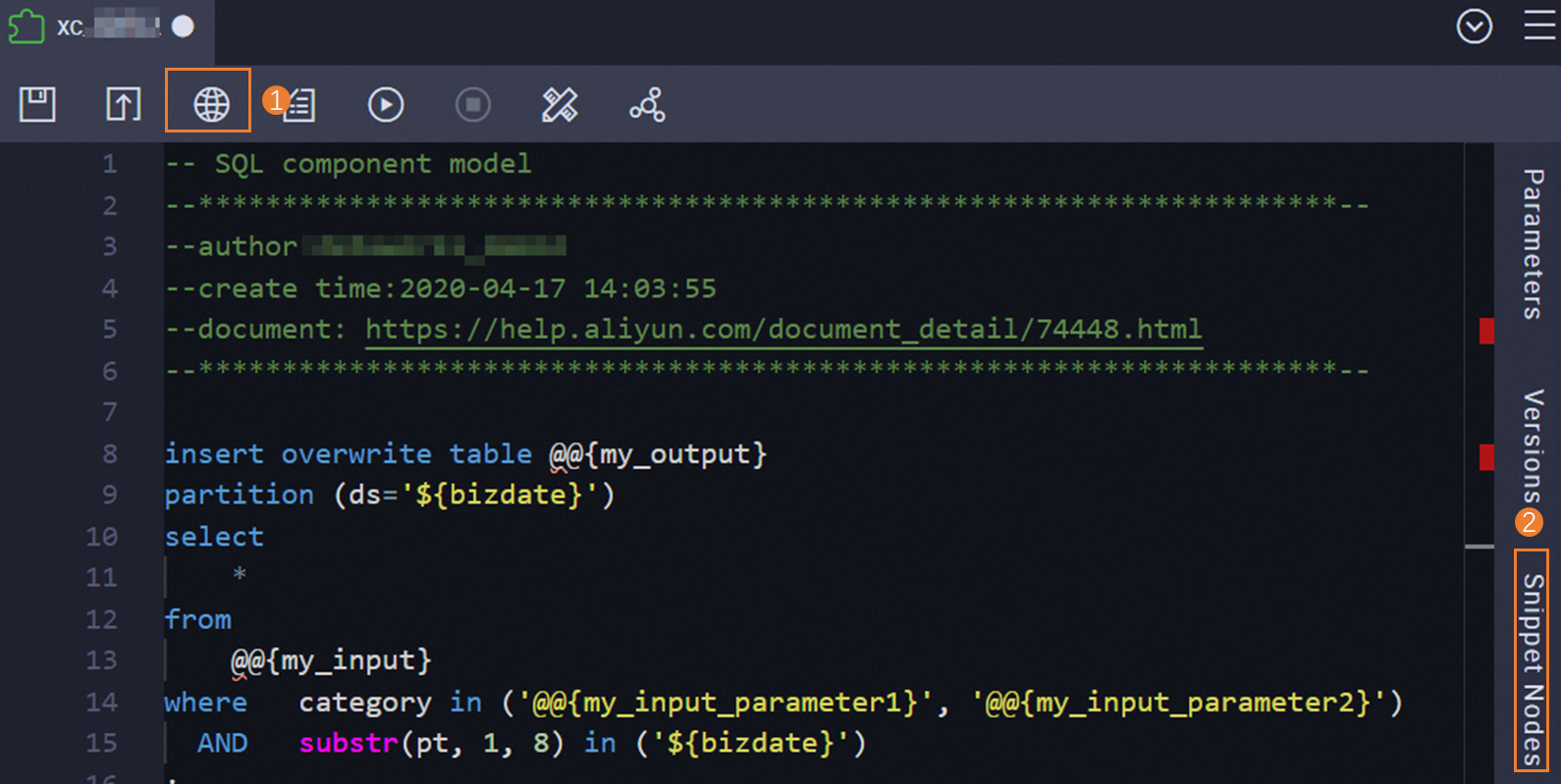
View reference records
On the Snippet Nodes tab (marked 2 in the figure), see all nodes that reference the current template. Review this list before modifying a template to understand the downstream impact.
Upgrade a template
Edit the SQL code or parameter settings in the template, then save and recommit. Each recommit creates a new version. View the version history on the Versions tab (marked 3 in the figure) in the right-side navigation pane.
Impact on referencing nodes
When a template is upgraded, you can determine whether to use the latest version of the template in your SQL Snippet node. To adopt the new version, open the SQL Snippet node, click Update Code, verify that the new parameter settings work for your pipeline, and then commit and deploy the node.
Example scenario
Developer C creates version V1.0 of a template. User A references V1.0. Developer C later upgrades to V2.0. User A sees that a newer version is available, reviews the V2.0 details, and decides whether to update their node to use V2.0.
Configuration tab reference

| Feature | Description |
|---|---|
| Save | Saves the current template settings |
| Steal Lock | Takes over the edit lock from another user so you can edit the template, if you are not the owner of the script template |
| Submit | Commits the template to the development environment |
| Publish Snippet | Makes the template available to all users in the current tenant |
| Parse I/O Parameters | Parses input and output parameters from the SQL code |
| Run | Runs the template in the development environment |
| Stop | Stops a running template |
| Format Code | Formats the SQL code by keyword |
| Parameters | View basic information and configure input and output parameters |
| Versions | View all deployed versions of the template |
| Snippet Nodes | View all nodes that reference the template |
Best practices: top-N sales ranking
This example walks through creating a get_top_n script template that returns the top N cities by total sales in each region, then referencing it from an SQL Snippet node.
Prerequisites
Before you begin, ensure that you have:
-
An SQL Snippet node. See Create and manage ODPS nodes.
-
An input table and an output table created in an ODPS SQL node.
Step 1: Define the get_top_n template
Create a script template named get_top_n. See Define a script template for the full procedure. Use the following configuration.
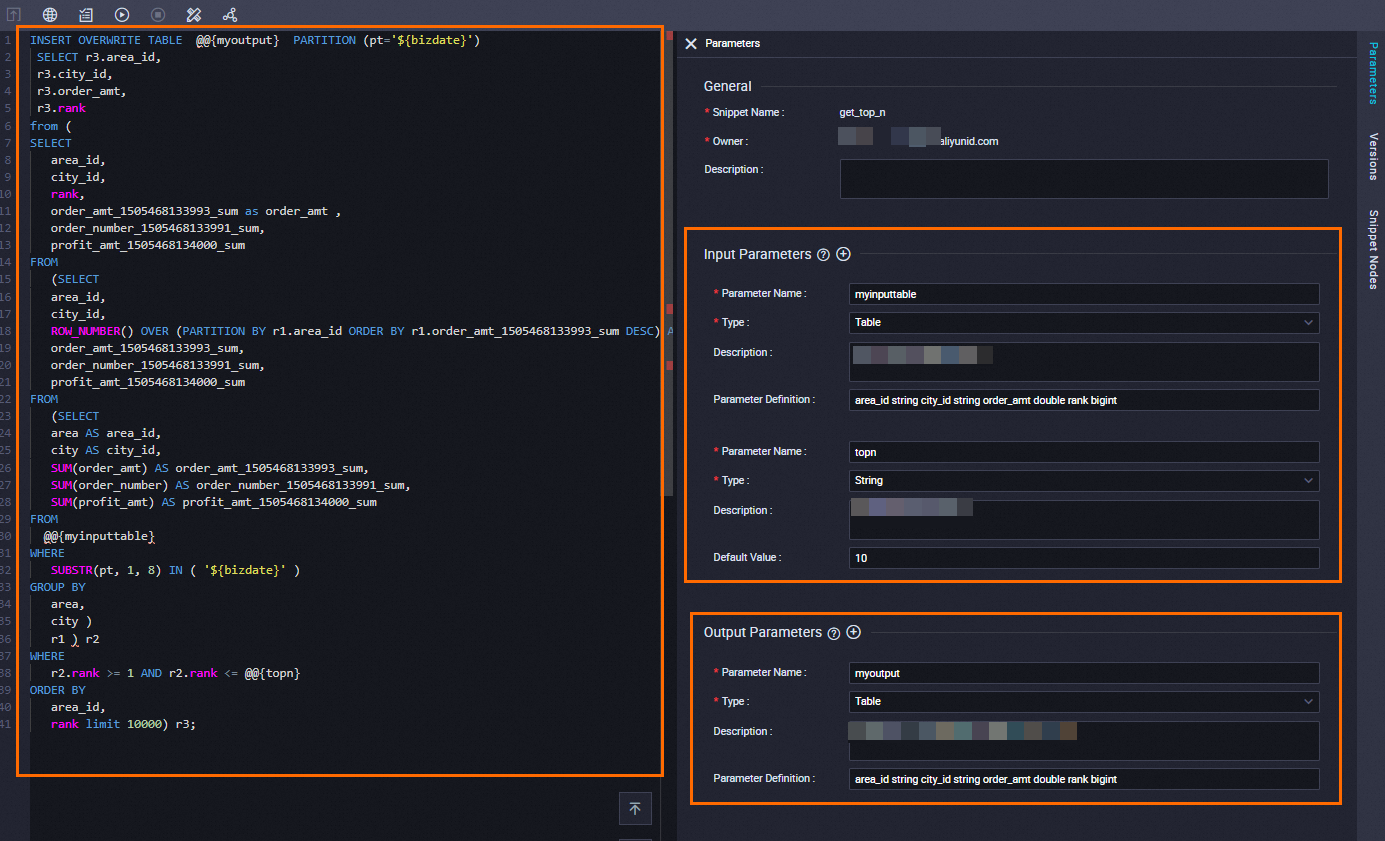
Parameter settings
| Category | Parameter | Type | Description | Parameter definition |
|---|---|---|---|---|
| Input parameter | myinputtable |
Table | Sales data table | area_id string, city_id string, order_amt double, rank bigint |
| Input parameter | topn |
String | Number of top cities to return | N/A |
| Output parameter | myoutput |
Table | Rankings of the top cities per region | area_id string, city_id string, order_amt double, rank bigint |
SQL code process
The template uses @@{myinputtable}, @@{myoutput}, and @@{topn} as placeholders. DataWorks substitutes them with the bound values when the node runs.
INSERT OVERWRITE TABLE @@{myoutput} PARTITION (pt='${bizdate}')
SELECT r3.area_id,
r3.city_id,
r3.order_amt,
r3.rank
from (
SELECT
area_id,
city_id,
rank,
order_amt_1505468133993_sum as order_amt ,
order_number_1505468133991_sum,
profit_amt_1505468134000_sum
FROM
(SELECT
area_id,
city_id,
ROW_NUMBER() OVER (PARTITION BY r1.area_id ORDER BY r1.order_amt_1505468133993_sum DESC) AS rank,
order_amt_1505468133993_sum,
order_number_1505468133991_sum,
profit_amt_1505468134000_sum
FROM
(SELECT
area AS area_id,
city AS city_id,
SUM(order_amt) AS order_amt_1505468133993_sum,
SUM(order_number) AS order_number_1505468133991_sum,
SUM(profit_amt) AS profit_amt_1505468134000_sum
FROM
@@{myinputtable}
WHERE
SUBSTR(pt, 1, 8) IN ( '${bizdate}' )
GROUP BY
area,
city )
r1 ) r2
WHERE
r2.rank >= 1 AND r2.rank <= @@{topn}
ORDER BY
area_id,
rank limit 10000) r3;Step 2: Reference the template from an SQL Snippet node
Create an SQL Snippet node named xc_Referenced script template_get_top_n, select the get_top_n template, and configure parameters as shown below.
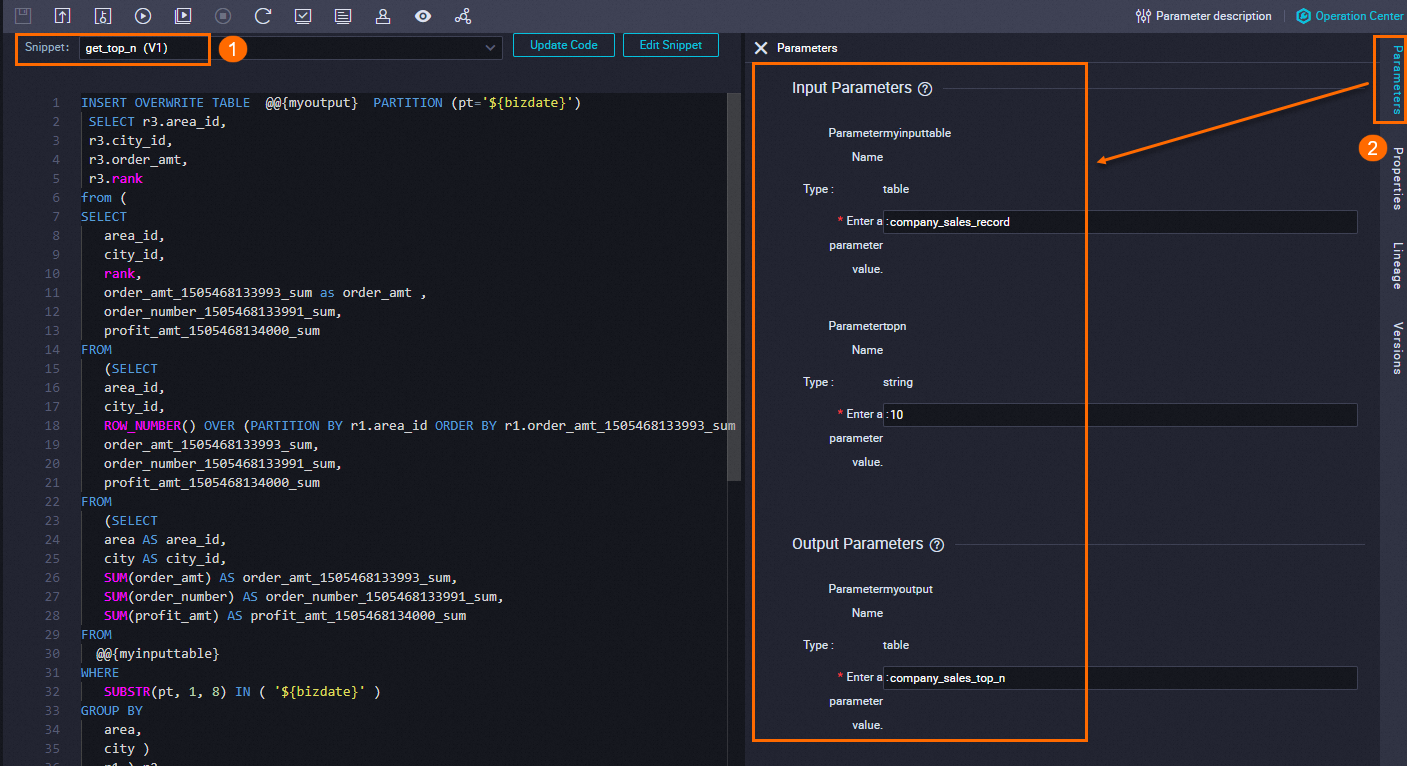
Parameter configuration
-
myinputtable: bind tocompany_sales_record, a partitioned table with a 365-day lifecycle.CREATE TABLE IF NOT EXISTS company_sales_record ( order_id STRING COMMENT 'Order ID (PK)', report_date STRING COMMENT 'Order generation date', customer_name STRING COMMENT 'Customer name', order_level STRING COMMENT 'Order level', order_number DOUBLE COMMENT 'Number of orders', order_amt DOUBLE COMMENT 'Order amount', back_point DOUBLE COMMENT 'Discount', shipping_type STRING COMMENT 'Transportation method', profit_amt DOUBLE COMMENT 'Amount of profit', price DOUBLE COMMENT 'Unit price', shipping_cost DOUBLE COMMENT 'Cost of transportation', area STRING COMMENT 'Region', province STRING COMMENT 'Province', city STRING COMMENT 'City', product_type STRING COMMENT 'Product type', product_sub_type STRING COMMENT 'Product subtype', product_name STRING COMMENT 'Product name', product_box STRING COMMENT 'Product packaging', shipping_date STRING COMMENT 'Date of transportation' ) COMMENT 'Detailed sales data' PARTITIONED BY ( pt STRING ) LIFECYCLE 365; -
topn: set to10to return the top 10 cities by total sales in each region. -
myoutput: bind tocompany_sales_top_n.CREATE TABLE IF NOT EXISTS company_sales_top_n ( area STRING COMMENT 'Region', city STRING COMMENT 'City', sales_amount DOUBLE COMMENT 'Sales amount', rank BIGINT COMMENT 'Ranking' ) COMMENT 'Company sales rankings' PARTITIONED BY (pt STRING COMMENT '') LIFECYCLE 365;
What's next
After completing development, configure the node for production:
-
Configure scheduling properties: Set up periodic scheduling, rerun settings, and scheduling dependencies. See Overview.
-
Debug the node: Test the code logic before deployment. See Debugging procedure.
-
Deploy the node: Deploy to activate periodic scheduling. See Deploy nodes.