The Oracle output component writes data to an Oracle data source. After configuring the source data, configure the Oracle output component as the synchronization target.
Prerequisites
An Oracle data source is created. Creating an Oracle Data Source.
The account has write-through permissions on the data source. Apply for, Renew, and Return Data Source Permissions.
Procedure
In the top menu bar of the Dataphin home page, choose R&D > Data Integration.
On the integration page, select a Project. In Dev-Prod mode, also select an Environment.
In the left navigation pane, click Offline Integration. In the Offline Integration list, click the target offline pipeline to open its configuration page.
In the upper-right corner, click Component Library to open the Component Library panel.
In the Component Library panel, select Output, find Oracle, and drag it to the canvas.
Click and drag the
 icon of the target input, transform, or flow component to connect it to the Oracle output component.
icon of the target input, transform, or flow component to connect it to the Oracle output component.Click the
 icon on the Oracle output component card to open the Oracle Output Configuration dialog box.
icon on the Oracle output component card to open the Oracle Output Configuration dialog box.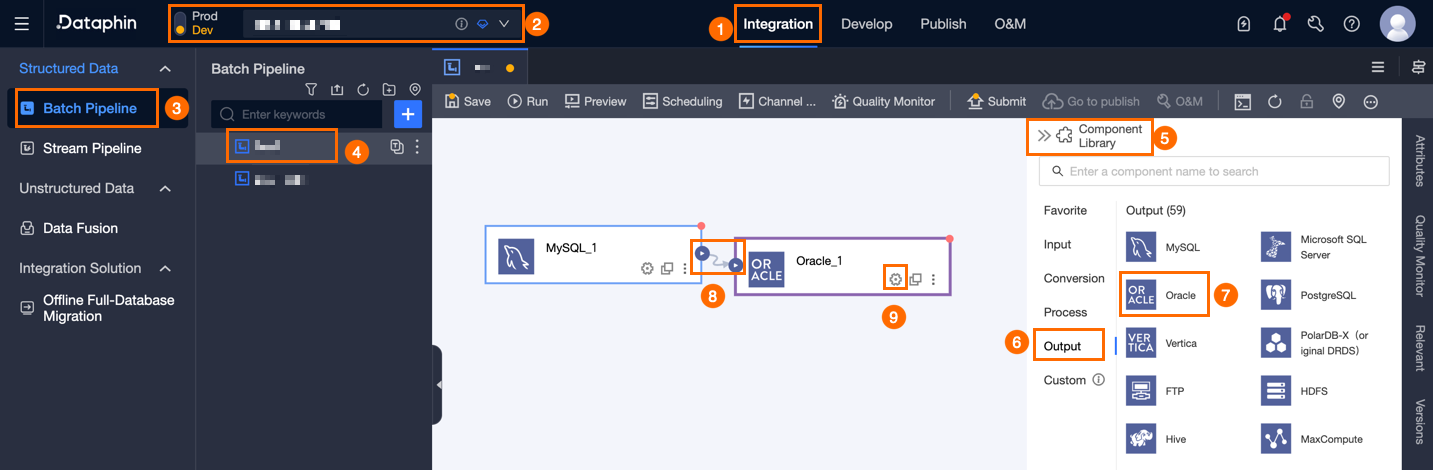
In the Oracle Output Configuration dialog box, configure the following parameters.
Parameter
Description
Basic Settings
Step Name
The component name. Dataphin auto-generates a default name. Naming rules:
Only Chinese characters, letters, underscores (_), and digits are allowed.
It must be no more than 64 characters in length.
Datasource
Select an Oracle data source. The list shows all Oracle data sources regardless of your permissions. Click
 to copy the data source name.
to copy the data source name.If you lack write-through permissions, click Request next to the data source. Apply for, Renew, and Return Data Source Permissions.
To create a data source, click Create Data Source. For more information, see Create an Oracle data source.
Time Zone
Uses the time zone configured in the data source. This setting cannot be changed.
NoteFor nodes created before version 5.1.2, you can select Data Source Default Configuration or Channel Configuration Time Zone. The default is Channel Configuration Time Zone.
Data Source Default Configuration: The default time zone of the selected data source.
Channel Configuration Time Zone: The time zone configured for the current integration node in Properties > Channel Configuration.
Schema (Optional)
Select the schema of the target table. Defaults to the schema configured in the data source.
Table
Select the target table. Search by keyword or use Exact Search for an exact match. Click
 to copy the table name.
to copy the table name.If the target table does not exist, create it with the following steps:
Click One-Click Table Creation. Dataphin generates the DDL with the source table name as default and field types based on initial type conversion.
Edit the SQL script as needed and click Create.
ImportantIf you do not change the table name after
CREATE TABLE, the system generates an uppercase table name by default.If you enclose the table name after
CREATE TABLEin double quotation marks, the table name is case-sensitive.
Dataphin automatically selects the new table as the output target.
NoteIf a same-named table exists in the development environment, an error is reported.
Policy for missing production table
Action when the production table does not exist. Options: Do Nothing or Automatic Creation. Default: Automatic Creation.
Do Nothing: A warning appears on submission, but you can still publish. Create the table manually in production before running the node.
Automatic Creation: You must edit the table creation statement. The default statement uses the selected table's DDL. The table name placeholder
${table_name}is replaced with the actual name during execution.If the target table does not exist, it is created using this statement. If creation fails, publishing is blocked. If the table already exists, the statement is skipped.
NoteThis parameter is available only in Dev-Prod mode.
Loading Policy
Select how data is written to the target table.
Append data (insert into): If a primary key or constraint violation occurs, a dirty data error is reported.
Update on primary key conflict (merge into): On primary key or constraint conflict, updates mapped fields on existing records.
Write-through
Oracle primary key updates are non-atomic. Enable write-through when data contains duplicate primary keys. Write-through has lower performance than parallel writing.
NoteThis parameter is available only when Loading Policy is set to Update on primary key conflict.
Batch write data volume (Optional)
Maximum data size per batch write. The system flushes when this or Batch write count is reached. Default: 32 MB.
Batch write count (Optional)
Maximum records per batch write. Default: 2048. The system uses both Batch write count and Batch write data volume as thresholds.
The system writes a batch when either limit is reached.
Set batch write data volume to 32 MB and adjust batch write count based on record size. Example: for 1 KB records with 16 MB volume, set count above 16,384 (16 MB / 1 KB). Setting it to 20,000 records means a batch is written each time the data volume reaches 16 MB.
Preparation statements (Optional)
The SQL script to execute on the database before data import.
Example: create table Target_A, write data to it, then swap with the service table for zero-downtime updates.
End statements (Optional)
The SQL script to execute on the database after data import.
Advanced Configuration
Logon timeout
Maximum logon wait time before disconnection. Unit: seconds (s). Default: 600 s.
Query timeout
Maximum query wait time before disconnection. Unit: seconds (s). Default: 1800 s.
Field Mapping
Input Fields
Shows input fields from the upstream component.
Output Fields
Shows the output fields. Available operations:
Manage Fields: Click Manage Fields to select fields.
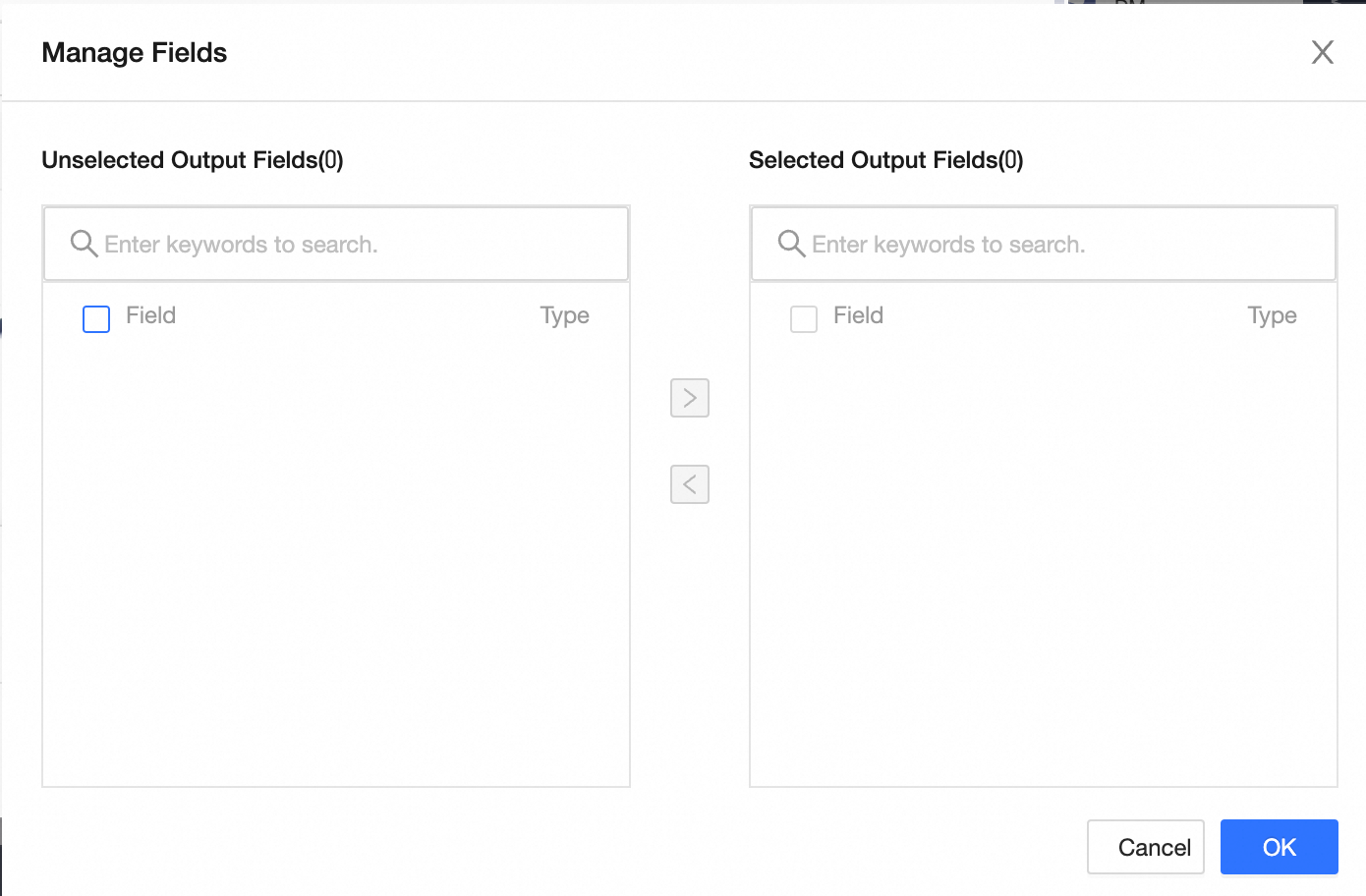
Click
 to move a field from Selected Input Fields to Unselected Input Fields.
to move a field from Selected Input Fields to Unselected Input Fields.Click
 to move a field from Unselected Input Fields to Selected Input Fields.
to move a field from Unselected Input Fields to Selected Input Fields.
Batch Add: Click Batch Add to configure fields in JSON, TEXT, or DDL format.
JSON format example:
// Example: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]Note"name":"user_id","type":"String"imports the field user_id with type String.TEXT format example:
// Example: user_id,String user_name,StringRow delimiter separates fields. Default: line feed (\n). Semicolons (;) and periods (.) are also supported.
Column delimiter separates the field name from the type. Default: comma (,).
DDL format example:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
Create Output Field: Click + Create Output Field, enter a Column name, select a Type, and click
 to save.
to save.
Mapping
Map fields between the upstream input and target table. Quick Mapping supports Map by Row and Map by Name.
Map by Name: Maps fields with identical names.
Map by Row: Maps fields in the same row. Use this when source and target field names differ but row positions correspond.
Click Confirm to complete the configuration of the Oracle output component.