This document provides the release notes for training-nv-pytorch 25.08.
Main features and bug fixes
Main features
-
Upgraded transformers to 4.53.3+ali.
-
Upgraded vllm to 0.10.0 and ray to 2.48.0.
Bug fixes
No bug fixes in this release.
Contents
|
Use cases |
Training/inference |
|
Framework |
PyTorch |
|
Requirements |
NVIDIA driver version >= 575 |
|
Core Components |
|
Assets
25.08
-
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.08-serverless
VPC image
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}Replace{region-id}with the region where your Alibaba Cloud Container Compute Service (ACS) is activated (for example,cn-beijingorcn-wulanchabu).
Replace {image:tag} with the name and tag of the image.The inference-nv-pytorch:25.03-vllm0.8.2-pytorch2.6-cu124-20250328-serverless and inference-nv-pytorch:25.03-sglang0.4.4.post1-pytorch2.5-cu124-20250327-serverless images are compatible with ACS and Lingjun multi-tenant deployments only. It is not compatible with Lingjun single-tenant deployments.
The egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:25.08-serverless image is designed for use with ACS products and multi-tenant Lingjun environments. This image is not compatible with single-tenant Lingjun deployments and should not be used in these scenarios.
Driver requirements
-
The 25.08 release is based on CUDA 12.8.0 and requires NVIDIA driver version 575 or later. However, if you are running on a data center GPU, such as a T4, you can use NVIDIA driver version 470.57 (or a later R470 release), 525.85 (or a later R525 release), 535.86 (or a later R535 release), or 545.23 (or a later R545 release).
-
The CUDA driver compatibility package only supports specific drivers. Therefore, you must upgrade from any R418, R440, R450, R460, R510, R520, R530, R545, R555, or R560 drivers, as they are not forward-compatible with CUDA 12.8. For a complete list of supported drivers, see the CUDA Application Compatibility topic. For more information, see CUDA Compatibility and Upgrades.
Key features and enhancements
PyTorch compilation optimization
torch.compile(), introduced in PyTorch 2.0, often delivers strong gains for small-scale, single-GPU workloads. But LLM training depends on GPU memory optimization and distributed frameworks such as FSDP or DeepSpeed, so torch.compile() may offer limited benefits or even degrade performance.
-
Control communication granularity in the DeepSpeed framework. This helps the compiler capture a more complete compute graph and apply broader compilation optimizations.
-
Use an optimized PyTorch build:
-
The PyTorch compiler frontend is improved to ensure that compilation succeeds even if a graph break occurs in the compute graph.
-
Pattern matching and dynamic shape support are strengthened to improve post-compilation performance.
-
With these optimizations, 8B-parameter LLM training typically achieves an end-to-end throughput gain of about 20%.
GPU memory optimization for recomputation
A predictive model for GPU memory overhead, built on large-scale performance data—including different models, clusters, and training parameter settings, as well as system metrics such as GPU memory utilization collected during benchmarking—recommends the optimal number of activation recomputation layers. This approach is integrated into PyTorch, allowing you to achieve the performance gains of GPU memory optimization with minimal effort. This feature is now supported in the DeepSpeed framework.
ACCL
ACCL is Alibaba Cloud’s high-performance communication library built for Lingjun. ACCL-N is the GPU-focused version. ACCL-N is a high-performance communication library customized from NVIDIA NCCL. It is fully compatible with NCCL, fixes issues in the upstream NCCL release, and includes performance and stability improvements.
E2E performance gain assessment
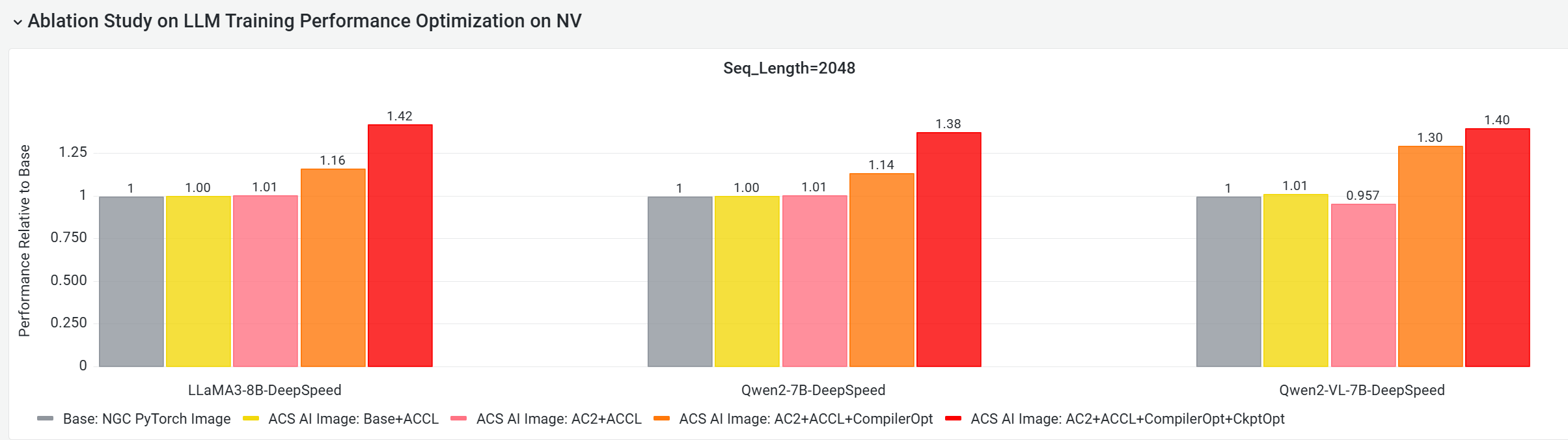
We used the CNP cloud-native AI performance analysis tool to compare the end-to-end performance of this image against standard base images using mainstream open-source models and framework configurations. Through ablation studies, we further assessed the contribution of each optimization component to the overall model training performance.
E2E performance contribution analysis of core GPU components
The following tests, conducted on a multi-node GPU cluster, compare the E2E training performance of these configurations:
-
Base: NGC PyTorch Image.
-
ACS AI Image: Base+ACCL: The image uses the ACCL communication library.
-
ACS AI Image: AC2+ACCL: The image on AC2 BaseOS with ACCL and no other optimizations.
-
ACS AI Image: AC2+ACCL+CompilerOpt: The image on AC2 BaseOS with only the
torch.compile()optimization enabled. -
ACS AI Image: AC2+ACCL+CompilerOpt+CkptOpt: The image on AC2 BaseOS with both
torch.compile()and selective gradient checkpointing optimization enabled.
Quick start
The following shows how to pull the training-nv-pytorch image by using Docker.
To use the training-nv-pytorch image in ACS, select it from the container registry page when you create a workload in the console, or specify it in a YAML file.
1. Pull the image
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]2. Enable optimizations
-
Enable compilation optimization
In the transformers Trainer API:
training_args = TrainingArguments( bf16=True, gradient_checkpointing=True, torch_compile=True ) -
Enable selective gradient checkpointing optimization
export CHECKPOINT_OPTIMIZATION=true
3. Start the container
The following example uses the included ljperf tool to start a container and run a training job.
For LLMs
# Start the container and enter it
docker run --rm -it --ipc=host --net=host --privileged egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-nv-pytorch:[tag]
# Run the training demo
ljperf benchmark --model deepspeed/llama3-8b 4. Recommendations
-
The image contains modified versions of libraries such as PyTorch and DeepSpeed. Do not reinstall them.
-
In the DeepSpeed configuration, leave
zero_optimization.stage3_prefetch_bucket_sizeempty or set it toauto. -
The image includes the built-in environment variable
NCCL_SOCKET_IFNAME. Set it based on your scenario:-
When a single Pod requests only 1, 2, 4, or 8 GPUs for training or inference tasks, you need to set
NCCL_SOCKET_IFNAME=eth0(this is the default configuration in this image). -
When a single Pod requests all 16 GPUs on an entire machine for training or inference tasks, set
NCCL_SOCKET_IFNAME=hpn0to use the HPN high-performance network.
-
Known issues
None at this time.