To improve the high availability and security of a Dify application, you can use an AI gateway to proxy its ingress and egress traffic. This topic describes the procedure and demonstrates some of the gateway's features.
AI gateway capabilities
An AI gateway acts as a bridge between the external environment and enterprise AI applications, and between enterprise AI applications and large language model (LLM) services or MCP services. It solves problems such as complex model integration, high security and compliance requirements, and inefficient management. It provides a unified entry point for traffic governance and control. Its core features include the following:
Protocol standardization: Converts heterogeneous APIs from different models into a standardized, OpenAI compatible interface format.
Observability: Supports token-level metric monitoring for metrics such as queries per second (QPS), success rate, and response time. It also provides full-link request tracing.
Security protection: Provides automatic API key rotation, JWT identity authentication, and real-time detection and interception of sensitive content.
Stability engine: Integrates multi-level fallback policies, AI cache acceleration, token-level throttling, and other traffic governance features.
For high availability (HA), the AI gateway provides a complete set of HA mechanisms optimized for AI applications and models. These mechanisms ensure service continuity, stability, and reliability.
Multi-dimensional request throttling: Provides fine-grained control over request traffic based on dimensions such as application and model. It supports time granularities such as seconds, minutes, and hours. This feature effectively handles traffic bursts and high-concurrency scenarios, prevents service overload, and ensures system stability.
Token-level resource throttling: In addition to request volume control, it provides throttling based on token consumption. This allows for precise control over LLM resource usage, prevents individual high-consumption requests from exhausting the resource pool, and improves the fairness of resource allocation.
Model fallback mechanism: When the primary model service fails or responds abnormally, the gateway can automatically and transparently route requests to a pre-configured backup model. This ensures business continuity and achieves second-level failover and disaster recovery.
Model load balancing: For self-built model clusters, it supports intelligent load balancing policies such as GPU-aware scheduling and prefix matching. This improves system throughput, reduces response latency, and maximizes GPU resource utilization without additional hardware investment.
AI caching mechanism: Caches the response results of frequent and repeated requests. The gateway returns the cached content directly, which significantly reduces the number of calls to the underlying LLM. This feature improves response speed and lowers invocation costs.
Proxy Dify application ingress and egress traffic with an AI gateway
To use an AI gateway to improve the high availability, security, and observability of a Dify application, you must integrate the AI gateway with the Dify system. The integration plan is as follows:
In the original architecture, Dify uses a built-in Nginx as a reverse proxy to handle ingress traffic. Dify directly calls backend services such as large language models, retrieval-augmented generation (RAG) services, and Mcp Server.
In the new architecture, the AI gateway replaces the built-in Nginx to uniformly proxy all ingress and egress traffic for the Dify application.
When proxying ingress traffic, directly replace Nginx with the AI gateway instead of routing traffic to the AI gateway as an upstream for Nginx. The main reasons are as follows:
1. Full capability coverage: The AI gateway covers all the reverse proxy features of Nginx and provides more than 20 governance policies specifically for AI services. The default buffering mechanism in Nginx interrupts Server-Sent Events (SSE) stream responses. You must manually tune multiple parameters to support streaming, which makes the configuration complex and lacks in-depth observability support.
2. Simplified architecture: Directly proxying traffic to the Dify service with the AI gateway eliminates an extra proxy layer. A dual-gateway architecture (AI Gateway > Nginx > Dify) introduces unnecessary network hops, which increases latency and affects performance. Troubleshooting must also cover the Nginx layer, which prolongs the problem-locating period and reduces O&M efficiency.
3. Optimized O&M costs: Nginx requires separate deployment and consumes additional computing and memory resources. Scaling relies on manual intervention. Traffic routing changes must be synchronized between two systems, which can easily lead to configuration inconsistencies. In contrast, the AI gateway uses a managed deployment mode and provides an enterprise-level Service-Level Agreement (SLA). It natively integrates monitoring, logging, and alerting capabilities, which significantly reduces O&M complexity and the total cost of ownership.
Procedure
Proxy ingress traffic for a Dify application
The AI gateway lets you create an Agent API to proxy access to AI applications. It provides observability, security, and high availability governance for the traffic to these applications.
Step 1: Create a service source
When you create a service source in the AI gateway for Dify's API component, if Dify is deployed in an SAE or ACK environment, configure service discovery as follows:
SAE (deployed through SAE or Dify Community Edition-Serverless on CP)
Log on to the AI Gateway console.
In the navigation pane on the left, choose Instance. In the top menu bar, select a region.
On the Instance page, click the target instance ID.
In the navigation pane on the left, select Service, click Create Service, set Service Source to SAE Kubernetes Service, select the namespace where the Dify application resides for Namespace, and select the
dify-api-{namespace}application from the Service List.Click OK to complete the service configuration.
ACK (deployed through ACK Helm or Dify Community Edition-High-availability Edition on CP)
Create a container source. Then, add the `ack-dify-api` service from the `dify-system` namespace.
Log on to the AI Gateway console.
In the navigation pane on the left, choose Instance. In the top menu bar, select a region.
On the Instance page, click the target instance ID.
In the navigation pane on the left, select Service, click Create Service, set Service Source to Container Service, select the namespace where the Dify application is deployed for Namespace, and select the following services from the Service List:
ack-dify-api
Click OK to complete the service configuration.
Step 2: Configure routing
You can use an Agent API in the AI gateway to configure routing for the Dify service. The procedure is as follows:
In the navigation pane on the left of the instance details page, select Agent API.
Click Create Agent API and configure the parameters.
Configure the Domain Name and Base Path based on your requirements. This lets you access Dify using the domain name and avoid path conflicts with other services.
Select Remove When Forwarding To Backend Service.
For Protocol, select Dify.
Click the name of the Agent API that you created, and then click Create Route. Configure the Path parameter based on your scenario and select the service that you created in Step 1 for Agent Service.
NoteTo map a route to a Dify application, you can configure request header or request parameter matching conditions in the More Matching Rules section. For example, you can set
header-key=app-id. When you access the Dify application through the AI Gateway, you must include the corresponding matching fields in your request.If the Dify application is a workflow application, set Path to
/v1/workflows/run.If the Dify application is an agent application, set Path to
/v1/chat-messages.
After the route is published, access the Dify application using the configured domain name and path to verify the configuration. If the request is invoked successfully, the ingress traffic proxy is configured correctly.
Proxy egress traffic for a Dify application
The AI gateway lets you create an LLM API to proxy access to large language models, create an Mcp Server to proxy MCP traffic, and use an RAG plugin to proxy RAG retrieval. It provides observability, security control, and high availability governance for different types of traffic.
In Dify applications, the main scenarios are accessing large language models and external knowledge bases. This section focuses on how to configure the AI gateway to proxy traffic for large language models and external knowledge bases.
Proxy model traffic
In the AI Gateway console, create a Model API to access self-built or third-party large language models. For more information, see Manage Model APIs.
Go to the Dify application marketplace and install the higress plugin.
Go to the Dify console. In the upper-right corner, click Settings > Model Providers. Add a model for Higress. The following example uses an LLM:
Set Model Type to LLM.
Enter custom values for Model Name and Credential Name.
Select a Use Case and Model Protocol based on the actual scenario and protocol of the AI Gateway Model API, such as text generation or image generation, and OpenAI compatible or Alibaba Cloud Model Studio protocols.
For Higress AI Gateway Route, enter the domain name and prefix of the Model API that you created in the AI gateway.
Configure other parameters such as Consumer Authentication Policy, Function Invocation Type, and Thinking Mode Support as required.
In the application, at the node where you need to select a model, choose the model that you created in the previous step.
Run the workflow or agent in Dify. Verify that accessing the LLM through the AI gateway proxy returns a result. This indicates that the egress traffic proxy for the large language model is configured correctly.
Proxy for external knowledge bases
Some Dify users want to connect to and access external knowledge bases, such as Alibaba Cloud Model Studio and RAGFlow, to improve RAG performance while using Dify's efficient building and orchestration capabilities.
The AI gateway provides an RAG proxy plugin designed for Dify. This plugin helps Dify connect to external knowledge bases easily and efficiently, which reduces the technical difficulty and development costs for users.
For a detailed description and the procedure of the RAG proxy plugin, see AI RAG retrieval proxy.
Demonstration of high availability capabilities
After you complete the preceding steps to configure the AI gateway to proxy ingress and egress traffic for the Dify application, you can enable the capabilities of the AI gateway as needed to observe and govern the AI traffic of the Dify application. This section uses high availability governance as an example to demonstrate some of its features. For more information about AI gateway capabilities, see AI Gateway.
Govern ingress traffic for a Dify application
Using the AI gateway as the traffic entry point for a Dify application, you can configure cluster throttling policies on the AI gateway to implement multi-dimensional traffic control at the global and application levels. This section uses application-level throttling as an example.
To support global and application-level throttling, you must introduce a Redis instance for counting. Because Redis is a necessary component in the Dify system's storage architecture, you can reuse the existing Redis instance of the Dify system.
After you connect the Redis instance in the AI gateway, you can enable the cluster-key-rate-limit plugin from the plugin marketplace and configure rules to implement independent throttling policies for different Dify applications. For more information about the configuration of this plugin, see cluster-key-rate-limit plugin.
The following example configuration allows only one request to pass through a Dify application per minute.
rule_name: dify_higress_demo_rule
rule_items:
- Limit_by_header: x-app-id
limit_keys:
- key: 9a342******************3e1250b5
query_per_minute: 1
redis:
service_name: dify-redis.dns
show_limit_quota_header: trueAfter the plugin is enabled, if you send a second request to the application within one minute, the throttling rule of the AI gateway is triggered, and the request fails. Other applications that do not have throttling rules can still be called without limits.
Govern egress traffic for a Dify application
Request throttling and token throttling
Using the AI gateway to proxy calls from a Dify application to a model service, you can implement request throttling at different time granularities. The configuration method and effect are the same as described earlier. The only difference is the location where the throttling policy is applied. This section does not repeat the details.
In addition, when a Dify application calls a model service, you can also control traffic based on token consumption. For more information, see Throttling.
The following example configuration limits the Model API to 500 tokens per minute.

After the configuration takes effect, if the total token consumption of the model service exceeds 500 tokens within one minute, the AI gateway directly rejects requests to access the model.
Model fallback
You can configure a fallback mechanism for model access. When the default model service responds abnormally, it automatically switches to a backup model service. This ensures the continuity and high availability of model calls, which improves the overall service availability of the Dify application. For the specific configuration steps and usage instructions, see AI Fallback.
To verify the effect of the fallback mechanism, this example configures the primary model service of the Model API accessed by the Dify application to an unreachable address. It also configures an Alibaba Cloud Model Studio service as an accessible backup model service.
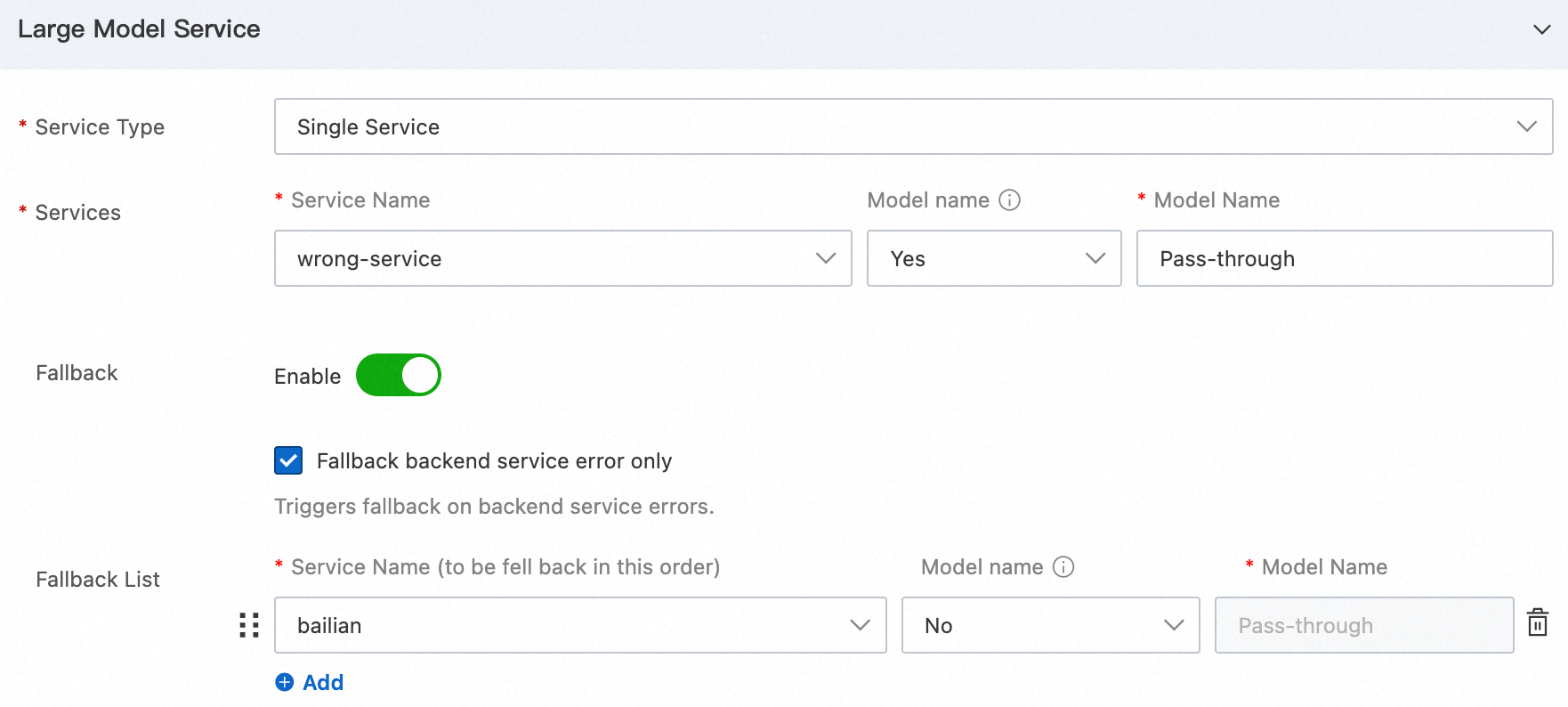
After the configuration takes effect, if you run the Dify application, you can see that the LLM node still returns a result, and the workflow runs normally.
The gateway logs show that the AI gateway encountered a 503 error when it accessed the primary model service. It then automatically fell back to the Alibaba Cloud Model Studio service for the call and returned a normal result. This process ensures that the Dify application runs correctly.
Advanced load balancing
For scenarios where Dify accesses self-built models, such as models deployed on Alibaba Cloud PAI, the AI gateway provides multiple load balancing policies for LLM services. These policies include global least requests load balancing, prefix matching load balancing, and GPU-aware load balancing. These policies can improve system throughput, reduce response latency, and achieve fairer and more efficient task scheduling without increasing hardware costs.
Take prefix matching load balancing as an example. Use NVIDIA GenAI-Perf as a stress testing tool. Configure an average of 200 input tokens and 800 output tokens per round, with a concurrency of 20. Each session contains 5 rounds of dialogue, for a total of 60 sessions. The performance test results show that after this load balancing policy is enabled, the time to first token (TTFT) is significantly reduced. This indicates that a reasonable load balancing policy can significantly optimize response performance.
Metric | No load balancing | Prefix matching load balancing |
TTFT (time to first token) | 240 ms | 120 ms |
Average RT | 14934.85 ms | 14402.36 ms |
P99 RT | 35345.65 ms | 30215.01 ms |
Token throughput | 367.48 (token/s) | 418.96 (token/s) |
Prefix Cache hit rate | 40% + | 80% + |
Take prefix matching load balancing as an example. For the Model API accessed by the Dify application, you can easily configure a load balancing policy using a plugin. The configuration is as follows. After the plugin takes effect, the Dify application calls the LLM service through the AI gateway to implement load balancing for the self-built LLM service instances.
lb_policy: prefix_cache
lb_config:
serviceFQDN: redis.dns
servicePort: 6379
username: default
password: xxxxxxxxxxxx
redisKeyTTL: 60