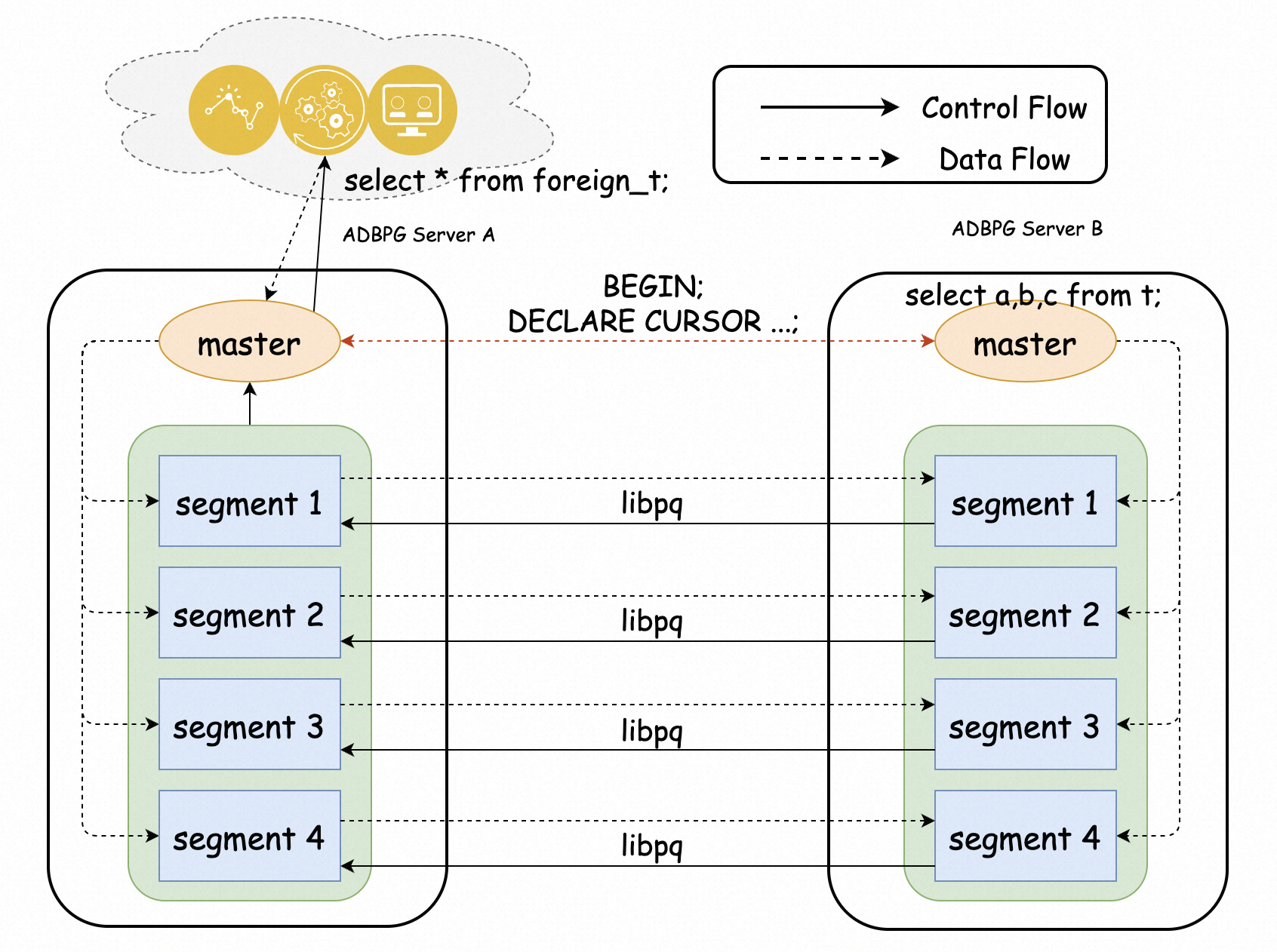
AnalyticDB for PostgreSQL uses a foreign data wrapper (FDW) to query data across instances within the same Alibaba Cloud account, without duplicating data or sacrificing freshness.
When your organization runs multiple AnalyticDB for PostgreSQL instances to support separate business units, getting a unified view across them is difficult. Copying data between instances causes inconsistency and redundancy. Sharing data through Object Storage Service (OSS) delays freshness. The FDW built on the Massively Parallel Processing (MPP) architecture solves this by using direct intercommunication between compute nodes to access remote data in parallel, achieving performance several times higher than the native postgres_fdw extension.
How it works
The FDW exposes tables on a remote instance as foreign tables on the local instance. Queries run on the local instance, and the FDW fetches only the data it needs from the remote instance using parallel compute-node connections. On AnalyticDB for PostgreSQL V7.0 in elastic storage mode, the Orca optimizer can push down joins and aggregates to the remote instance, reducing the amount of data transferred over the network.
Limits
| Limit | Detail |
|---|---|
| Account and network | Source and destination instances must belong to the same Alibaba Cloud account and reside in the same region and virtual private cloud (VPC). |
| Supported DML | Foreign tables support SELECT and INSERT only. UPDATE and DELETE are not supported. |
| Serverless scaling | If a Serverless mode instance is in the scaling state, its data cannot be accessed. |
| Join and aggregate pushdown | Supported only on V7.0 in elastic storage mode. |
| Execution plan optimizer | V7.0 (elastic storage mode) uses the Orca optimizer. V6.0 (elastic storage mode) and Serverless mode use the native optimizer. |
| Cross-version access | V7.0 uses a different password verification method. To access a V7.0 instance from a V6.0 or Serverless mode instance, Submit a ticket. |
Supported versions
| Deployment mode | Minimum version |
|---|---|
| V7.0 in elastic storage mode | V7.0.1.x |
| V6.0 in elastic storage mode | V6.3.11.2 |
| Serverless mode | V1.0.6.x |
Prerequisites
Before you begin, ensure that you have:
-
Two AnalyticDB for PostgreSQL instances in the same Alibaba Cloud account, region, and VPC
-
The
psqlclient installed and configured -
A database account with read permissions on the source instance (write permissions are also required for INSERT operations)
Set up cross-instance query
The following steps configure cross-instance querying between Instance A (the querying instance) and Instance B (the data source). After setup, queries run on the db01 database on Instance A can read tables from the db02 database on Instance B.
Step 1: Connect to both instances
Connect to Instance A and Instance B using psql. See Client connection for instructions.
Step 2: Create databases
Create a database on each instance and switch to it.
On Instance A:
CREATE DATABASE db01;
\c db01On Instance B:
CREATE DATABASE db02;
\c db02Step 3: Install required extensions
Install the greenplum_fdw and gp_parallel_retrieve_cursor extensions on both instances — in the db01 database on Instance A and in the db02 database on Instance B. Both instances must have the same extensions installed for cross-instance queries to work. See Install, update, and uninstall extensions for instructions.
Step 4: Add Instance A's IP address to Instance B's whitelist
Run the following statement on Instance A to get its internal IP address:
SELECT dbid, address FROM gp_segment_configuration;Add the returned IP address to a whitelist on Instance B. See Configure an IP address whitelist for instructions.
Step 5: Prepare test data on Instance B
Run the following statements on the db02 database of Instance B:
CREATE SCHEMA s01;
CREATE TABLE s01.t1(a int, b int, c text);
CREATE TABLE s01.t2(a int, b int, c text);
CREATE TABLE s01.t3(a int, b int, c text);
INSERT INTO s01.t1 VALUES(generate_series(1,10),generate_series(11,20),'t1');
INSERT INTO s01.t2 VALUES(generate_series(11,20),generate_series(11,20),'t2');
INSERT INTO s01.t3 VALUES(generate_series(21,30),generate_series(11,20),'t3');Step 6: Create a server and user mapping on Instance A
Run the following statements on the db01 database of Instance A.
Create a server — defines the connection to Instance B:
CREATE SERVER remote_adbpg FOREIGN DATA WRAPPER greenplum_fdw
OPTIONS (host 'gp-xxxxxxxx-master.gpdb.zhangbei.rds.aliyuncs.com',
port '5432',
dbname 'db02');| Parameter | Description |
|---|---|
host |
Internal endpoint of Instance B. Find it on the Basic Information page of Instance B in the AnalyticDB for PostgreSQL console, under Database Connection Information > Internal endpoint. |
port |
Internal port of Instance B. Default: 5432. |
dbname |
Name of the source database. In this example: db02. |
Create a user mapping — sets the credentials used to access Instance B. See CREATE USER MAPPING for the full syntax.
CREATE USER MAPPING FOR PUBLIC SERVER remote_adbpg
OPTIONS (user 'report', password '******');| Parameter | Description |
|---|---|
user |
Database account on Instance B. The account must have read access to db02. For INSERT operations, write access is also required. See Create a database account for instructions. |
password |
Password for the database account. |
Step 7: Import foreign tables
Choose one of the following methods to expose Instance B's tables in Instance A.
| Method | When to use |
|---|---|
| CREATE FOREIGN TABLE | Import specific tables; customize which columns to expose |
| IMPORT FOREIGN SCHEMA | Quickly import all tables from a schema; column names and types must match the source exactly |
Option 1: CREATE FOREIGN TABLE — import individual tables with custom column selection
CREATE SCHEMA s01;
CREATE FOREIGN TABLE s01.t1(a int, b int)
server remote_adbpg options(schema_name 's01', table_name 't1');This lets you expose only a subset of columns. In the example above, t1 has three columns on Instance B (a, b, c), but only a and b are imported. Each table requires a separate DDL statement.
Option 2: IMPORT FOREIGN SCHEMA — import all tables from a schema at once
CREATE SCHEMA s01;
IMPORT FOREIGN SCHEMA s01 LIMIT TO (t1, t2, t3)
FROM SERVER remote_adbpg INTO s01;This imports multiple tables in one statement without writing DDL for each. Foreign table columns must match the source tables exactly. See IMPORT FOREIGN SCHEMA for the full syntax.
Step 8: Query remote data
Run a query on Instance A to read data from Instance B:
SELECT * FROM s01.t1;Expected output:
a | b | c
----+----+----
2 | 12 | t1
3 | 13 | t1
4 | 14 | t1
7 | 17 | t1
8 | 18 | t1
1 | 11 | t1
5 | 15 | t1
6 | 16 | t1
9 | 19 | t1
10 | 20 | t1
(10 rows)Performance considerations
The following figure shows TPC-H benchmark results comparing a local query against a cross-instance query on a 1 TB dataset.
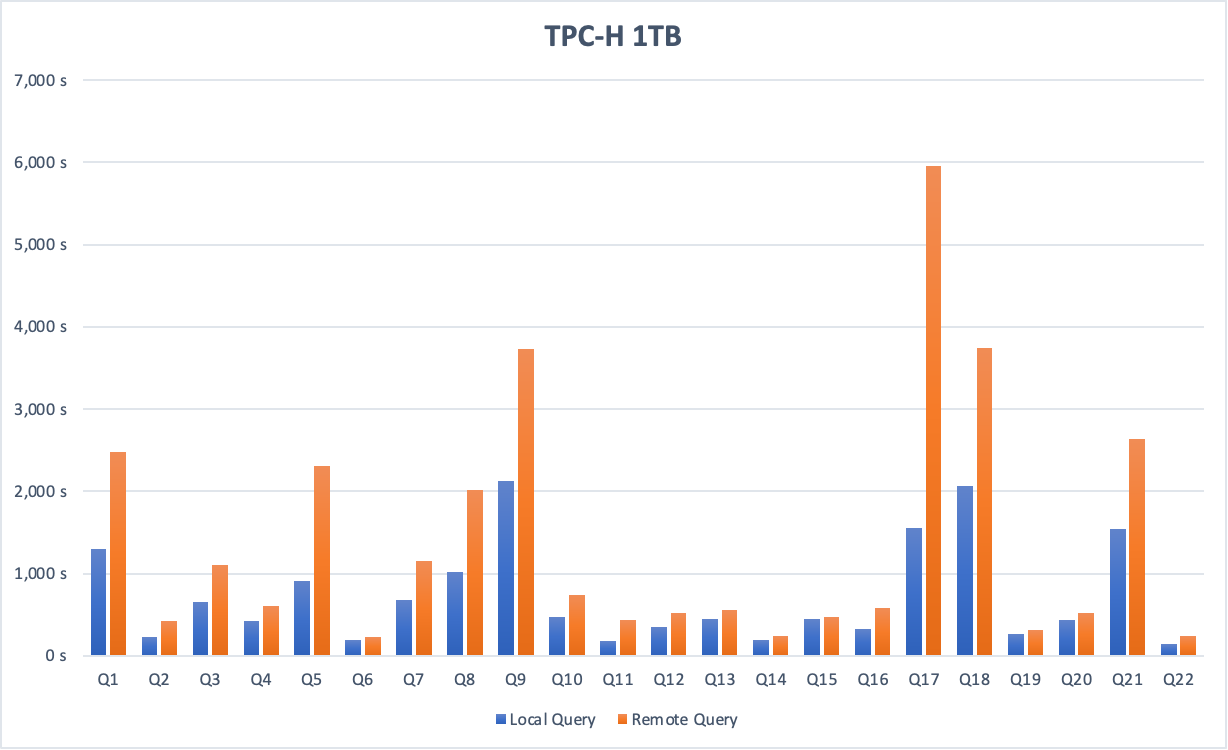
On a 1 TB dataset, cross-instance query performance is approximately half that of an equivalent local query, because data must be transmitted over the network.
To reduce network I/O:
-
Add WHERE clause filters on foreign tables. The FDW pushes filter conditions to the remote instance before data is transmitted, so only matching rows travel over the network.
-
Use V7.0 in elastic storage mode for join and aggregate pushdown. The Orca optimizer can push entire joins and aggregates to the remote instance, significantly reducing the volume of data transferred.
What's next
AnalyticDB for PostgreSQL also supports cross-database queries within the same instance. See Query data across databases.