Nova, the next-generation vector engine in AnalyticDB for PostgreSQL V7.0, delivers exceptional query performance and cost-effectiveness. It offers two modes: a cost-effective disk-based (Novad) mode and a high-performance memory-based (Novam) mode. This topic describes how to select and create a Nova vector index.
Benefits
A Nova vector index offers the following key benefits over a traditional HNSW index:
Improved query performance: Enables faster vector queries.
Optimized memory efficiency: The disk-based (Novad) index reduces memory usage and provides superior cost-effectiveness.
Increased write throughput: Decouples data ingestion from index building, improving the efficiency of vector data writes.
Prerequisites
An AnalyticDB for PostgreSQL V7.0 instance with a minor version of 7.4.2.0 or later.
The vector engine optimization feature is enabled.
Capacity evaluation and index selection
A Nova vector index has two modes: disk-based (Novad) and memory-based (Novam).
Disk-based (Novad): It uses a graph and partition-based hybrid index. The HNSW graph resides in memory while the Inverted File (IVF) index is stored on disk. This design is optimized for disk I/O and ensures stable performance even when the index size far exceeds memory capacity. Compared to Novam, Novad has a smaller memory footprint, higher index building performance, and lower disk usage. It is ideal for large-scale, cost-effective retrieval scenarios and provides significant cost advantages for datasets with tens or hundreds of billions of vectors.
Memory-based (Novam): It uses a graph index implementation. Its performance scales with available memory capacity, and it automatically spills to disk when memory is insufficient. With adequate memory, Novam delivers better query performance than Novad for the same resource specifications. It is ideal for high-performance scenarios such as real-time recommendation.
Nova vector indexes run periodic optimization tasks in the background, which may consume resources even without an active workload.
The following tables recommend resource specifications for different vector dimensions and numbers of vectors. These are examples, and you can add more resources to support larger datasets.
Novad
Vector dimension | Number of vectors | Recommended compute resources |
128 | < 320 million | 8 cores |
256 | < 160 million | |
512 | < 80 million | |
768 | < 50 million | |
1024 | < 40 million | |
1536 | < 26 million | |
2048 | < 20 million | |
128 | < 640 million | 16 cores |
256 | < 320 million | |
512 | < 160 million | |
768 | < 100 million | |
1024 | < 80 million | |
1536 | < 60 million | |
2048 | < 40 million | |
128 | < 1.28 billion | 32 cores |
256 | < 640 million | |
512 | < 320 million | |
768 | < 200 million | |
1024 | < 160 million | |
1536 | < 120 million | |
2048 | < 80 million | |
128 | < 5.12 billion | 128 cores |
256 | < 2.56 billion | |
512 | < 1.28 billion | |
768 | < 800 million | |
1024 | < 640 million | |
1536 | < 480 million | |
2048 | < 320 million | |
128 | < 200 billion | 4,096 cores |
256 | < 100 billion | |
512 | < 50 billion | |
768 | < 33 billion | |
1024 | < 25 billion | |
1536 | < 16 billion | |
2048 | < 12 billion | |
128 | < 1.6 trillion | 32,768 cores |
256 | < 800 billion | |
512 | < 400 billion | |
768 | < 260 billion | |
1024 | < 200 billion | |
1536 | < 130 billion | |
2048 | < 100 billion |
Novam
Vector dimension | Number of vectors | Recommended compute resources |
128 | < 32 million | 8 cores |
256 | < 16 million | |
512 | < 8 million | |
768 | < 5 million | |
1024 | < 4 million | |
1536 | < 2.6 million | |
2048 | < 2 million | |
128 | < 64 million | 16 cores |
256 | < 32 million | |
512 | < 16 million | |
768 | < 10 million | |
1024 | < 8 million | |
1536 | < 5 million | |
2048 | < 4 million | |
128 | < 128 million | 32 cores |
256 | < 64 million | |
512 | < 32 million | |
768 | < 20 million | |
1024 | < 16 million | |
1536 | < 10 million | |
2048 | < 8 million |
Syntax
CREATE INDEX [INDEX_NAME]
ON [SCHEMA_NAME].[TABLE_NAME]
USING ANN(COLUMN_NAME)
WITH (DIM=<DIMENSION>,
ALGORITHM=<ALGORITHM>,
DISTANCEMEASURE=<MEASURE>,
...);Parameters:
INDEX_NAME: The name of the index.
SCHEMA_NAME: The name of the schema (namespace).
TABLE_NAME: The name of the table.
COLUMN_NAME: The name of the vector column.
Other vector index parameters:
Parameter
Description
Default
Value
dim
The vector dimension.
None (Required)
[1, 8192]
algorithm
The indexing algorithm. Valid values:
novam: A graph-based index without quantization.
novad: A partition-based index with rabitq quantization.
hnswflat: An HNSW index without quantization.
hnswflat
(novam, novad, hnswflat)
distancemeasure
The distance measure for similarity search. Valid values:
L2: Builds the index using the squared Euclidean distance function. This is typically used for image similarity search. Formula:
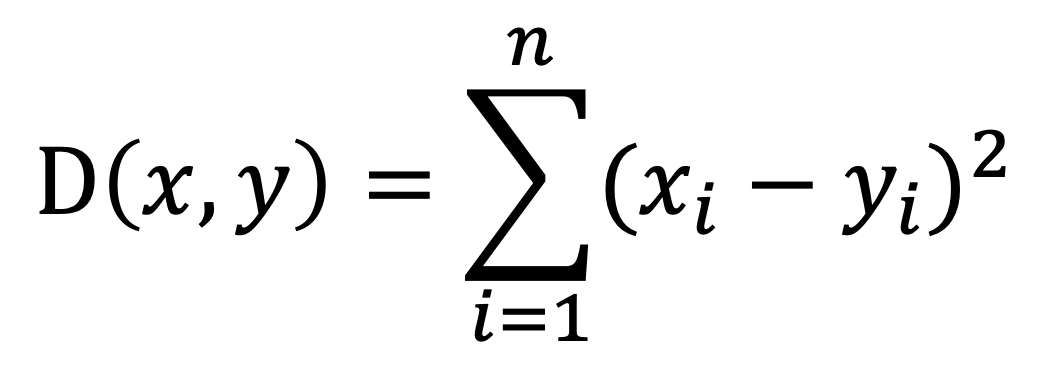
IP: Builds the index using the inverse inner product distance function. This is often used as a substitute for cosine similarity after vectors are normalized. Formula:
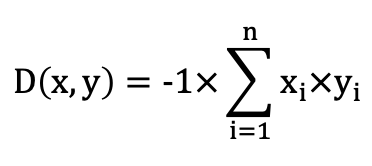
COSINE: Builds the index using the cosine distance function. This is typically used for text similarity search. Formula:
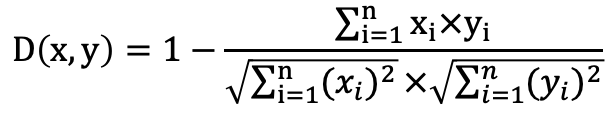
l2
(L2, IP, COSINE)
max_delta_vecs
The maximum number of vectors to batch for a single write operation.
1048576
[1024, 1073741824]
hnsw_m
For Novam, this specifies the number of neighbors for each node in the graph. A larger value generally improves graph quality but increases the build time.
16
[10, 1000]
hnsw_ef_construction
For Novam, this defines the search candidate set size during index construction. A larger value improves graph quality but increases the build time.
64
[40, 4000]
base_slice_log2_size
For Novam, this is the base-2 logarithm of the file slice size.
24
[10, 30]
nlist
For Novad, this specifies the number of lists in the partition-based index.
1024
[2, 1073741824]
accel_m
For Novad, this specifies the number of neighbors in the acceleration layer.
16
[8, 1024]
accel_efc
For Novad, this defines the search candidate set size for building the acceleration layer.
128
[1, 32768]
rabitq_bits
The number of bits used for rabitq compression.
1
[1, 8]
max_cluster_vecs
For Novad, this is the maximum number of vectors for a centroid in a single file.
65536
[1, 10000000]
Examples
Create a sample table.
CREATE TABLE chunks ( id SERIAL PRIMARY KEY, chunk VARCHAR(1024), intime TIMESTAMP, url VARCHAR(1024), feature REAL[] ) DISTRIBUTED BY (id);Create a Nova vector index on the vector column.
Create a Novad vector index that uses cosine distance.
CREATE INDEX idx_feature_novad_cosine ON chunks USING ann(feature) WITH ( dim=1536, algorithm=novad, distancemeasure=cosine, nlist=4096, rabitq_bits=1 );Create a Novam vector index that uses Euclidean distance.
CREATE INDEX idx_feature_novam_l2 ON chunks USING ann(feature) WITH ( dim=1536, algorithm=novam, distancemeasure=l2, hnsw_m=32, hnsw_ef_construction=200 );