Vector indexes accelerate approximate nearest neighbor (ANN) searches on large datasets. AnalyticDB for PostgreSQL uses the FastANN vector search engine, which implements the Hierarchical Navigable Small World (HNSW) algorithm on top of PostgreSQL's segmented page storage. FastANN stores only pointers to vector columns in the index, keeping storage overhead low. It also supports product quantization (PQ) to compress high-dimensional vectors and minimize table lookups during inserts and queries.
Prerequisites
Before you begin, ensure that you have:
An AnalyticDB for PostgreSQL instance with Vector Search Engine Optimization enabled. When this feature is enabled, the FastANN plugin is automatically installed.
A table with a vector column of type
real[],float4[],float2[], orsmallint[]
If you get the error You must specify an operator class or define a default operator class for the data type, Vector Search Engine Optimization is not enabled. Enable it and retry. For more information, see Enable or disable vector search engine optimization.Syntax
CREATE INDEX [INDEX_NAME]
ON [SCHEMA_NAME].[TABLE_NAME]
USING ANN(COLUMN_NAME)
WITH (DIM=<DIMENSION>,
DISTANCEMEASURE=<MEASURE>,
HNSW_M=<M>,
HNSW_EF_CONSTRUCTION=<EF_CONSTRUCTION>,
PQ_ENABLE=<PQ_ENABLE>,
PQ_SEGMENTS=<PQ_SEGMENTS>,
PQ_CENTERS=<PQ_CENTERS>,
EXTERNAL_STORAGE=<EXTERNAL_STORAGE>);Where:
INDEX_NAME: The index name.SCHEMA_NAME: The schema (namespace) name.TABLE_NAME: The table name.COLUMN_NAME: The vector column to index.
The following table describes the index parameters.
| Parameter | Required | Default | Range | Description |
|---|---|---|---|---|
DIM | Yes | 0 | [1, 8192] | Vector dimensionality. Inserts that don't match this dimension return an error. |
DISTANCEMEASURE | No | L2 | L2, IP, COSINE | Distance measure for the index. See Choose a distance measure. |
HNSW_M | No | 32 | [10, 1000] | Maximum number of neighbors per node. A higher value improves recall at the cost of more memory and slower index builds. |
HNSW_EF_CONSTRUCTION | No | 600 | [40, 4000] | Candidate set size during index construction. A higher value improves index quality at the cost of build time. |
PQ_ENABLE | No | 0 | 0, 1 | Enables product quantization (PQ) for dimension reduction. Don't enable PQ if the table has fewer than 500,000 rows. |
PQ_SEGMENTS | No | 0 | [1, 256] | Number of k-means segments for PQ. Required only when PQ_ENABLE=1 and DIM is not divisible by 8. DIM must be divisible by PQ_SEGMENTS. |
PQ_CENTERS | No | 2048 | [256, 8192] | Number of k-means centroids for PQ. Takes effect only when PQ_ENABLE=1. |
EXTERNAL_STORAGE | No | 0 | 0, 1 | Storage mode for the index: 0 uses segmented page storage (supports PostgreSQL shared_buffers caching, and full delete/update support); 1 uses mmap (from v6.6.2.3, supports mark-for-delete for limited deletes and updates). Supported only in version 6.0; not supported in version 7.0. |
Choose a distance measure
Pick the distance measure that matches your data and use case. The query operator you use must match the index's distance measure — mismatches cause the query to fall back to an exact (brute-force) search.
| Distance measure | Parameter value | Query operator | Use case |
|---|---|---|---|
| Euclidean (L2) | L2 | <-> | Image similarity search |
| Inner product | IP | <#> | Substitute for cosine similarity after vector normalization |
| Cosine | COSINE | <=> | Text similarity search |
IP and COSINE require engine version 6.3.10.18 or later. For version requirements, see Upgrade versions.
Best performance tip: Normalize your vectors before import, then use IP as the distance measure. An IP index lets queries also return Euclidean distance and cosine similarity directly. For details, see Vector search.
Create a vector index
The following example uses a text knowledge base: articles are split into chunks, converted to embedding vectors, and stored in a chunks table.
Step 1: Create the table
CREATE TABLE chunks (
id SERIAL PRIMARY KEY,
chunk VARCHAR(1024),
intime TIMESTAMP,
url VARCHAR(1024),
feature REAL[]
) DISTRIBUTED BY (id);| Column | Type | Description |
|---|---|---|
id | serial | Row ID |
chunk | varchar(1024) | Text chunk |
intime | timestamp | Import timestamp |
url | varchar(1024) | Source article URL |
feature | real[] | Embedding vector |
Step 2: Set the vector column storage to PLAIN
ALTER TABLE chunks ALTER COLUMN feature SET STORAGE PLAIN;Setting the storage mode to PLAIN avoids column decompression on each row scan, which reduces overhead and improves query performance.
Step 3: Create the vector index
Create an index that matches the distance measure you plan to use in queries. The index type must match the query operator — a mismatch causes the query to fall back to an exact (brute-force) search.
L2 (Euclidean) distance — use <-> in queries:
CREATE INDEX idx_chunks_feature_l2
ON chunks USING ann(feature)
WITH (dim=1536, distancemeasure=l2, hnsw_m=64, pq_enable=1);Inner product distance — use <#> in queries:
CREATE INDEX idx_chunks_feature_ip
ON chunks USING ann(feature)
WITH (dim=1536, distancemeasure=ip, hnsw_m=64, pq_enable=1);Cosine distance — use <=> in queries:
CREATE INDEX idx_chunks_feature_cosine
ON chunks USING ann(feature)
WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);Create vector indexes only as needed. Multiple vector columns per table and multiple indexes per column are supported, but unused indexes add overhead.
Step 4: Index structured columns for hybrid queries
CREATE INDEX ON chunks(intime);Indexing structured columns like intime improves performance when combining vector similarity with filters.
Index building methods
Two approaches are available for building vector indexes. For large-scale imports, asynchronous building is faster: import all data without a vector index first, then build the index in one pass on the complete dataset.
| Method | When to use | Trade-off |
|---|---|---|
| Stream building | Create the index before importing data | Index is built in real time as data arrives; slows import throughput |
| Asynchronous building (recommended) | Import data first, then create the index | Faster overall for large datasets; no index overhead during import |
Asynchronous building with parallel processing
AnalyticDB for PostgreSQL supports concurrent index building via the fastann.build_parallel_processes Grand Unified Configuration (GUC) parameter. Set it to match the number of cores on your compute nodes.
| Instance type | Recommended value |
|---|---|
| 4-core 16 GB | 4 |
| 8-core 32 GB | 8 |
| 16-core 64 GB | 16 |
If the instance is serving live traffic, don't set fastann.build_parallel_processes to the maximum. A lower value leaves capacity for ongoing workloads.
Build with DMS:
On DMS, all SET statements and the CREATE INDEX statement must be on the same line to take effect together.
SET statement_timeout = 0;SET idle_in_transaction_session_timeout = 0;SET fastann.build_parallel_processes = 8;CREATE INDEX ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);Build with psql:
Save the following to
create_index.sql:SET statement_timeout = 0; SET idle_in_transaction_session_timeout = 0; SET fastann.build_parallel_processes = 8; CREATE INDEX ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);Run the file:
psql -h gp-xxxx-master.gpdb.rds.aliyuncs.com -p 5432 -d dbname -U username -f create_index.sql
Vector functions reference
Supported functions
| Category | Function | Return type | Description | Supported data types |
|---|---|---|---|---|
| Distance | l2_distance | double precision | Euclidean distance (square root). Note In v6.3.10.17 and earlier, returns squared Euclidean distance. In v6.3.10.18 and later, returns the square root value. | smallint[], float2[], float4[], real[] |
| Distance | inner_product_distance | double precision | Inner product distance. Equals cosine similarity after normalization. Formula: 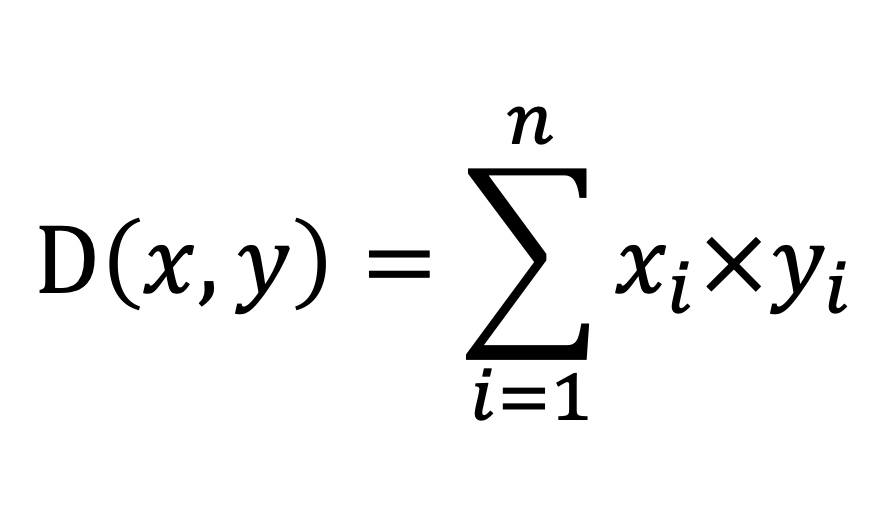 | smallint[], float2[], float4[], real[] |
| Distance | cosine_similarity | double precision | Cosine similarity. Range: [-1, 1]. Measures directional similarity regardless of vector length. Formula: 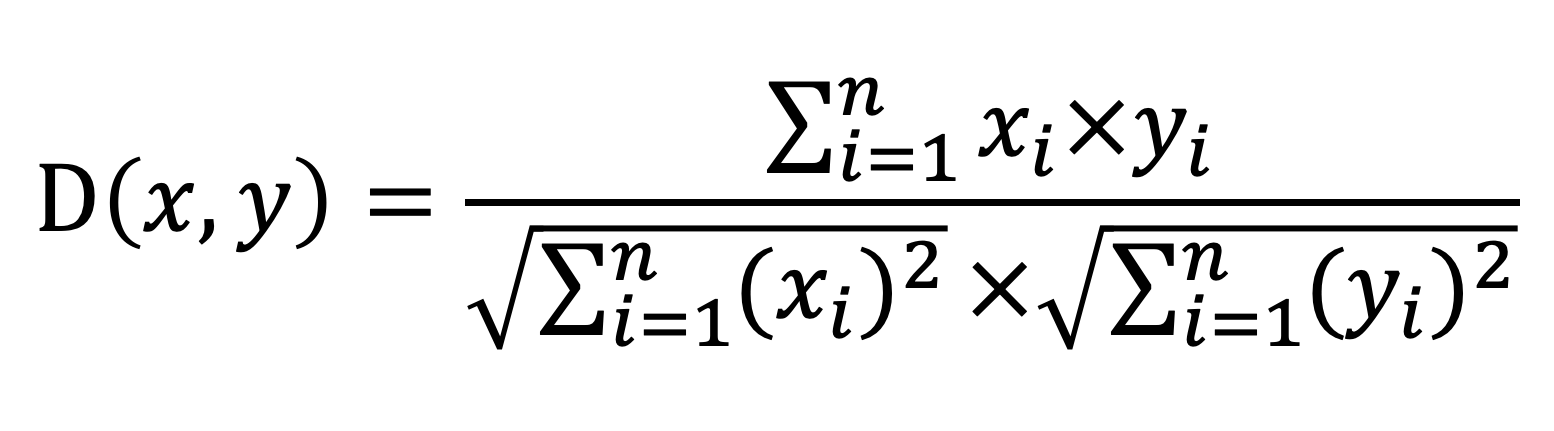 | smallint[], float2[], float4[], real[] |
| Distance | dp_distance | double precision | Dot product distance. Identical to inner product distance. Formula: | smallint[], float2[], float4[], real[] |
| Distance | hm_distance | integer | Hamming distance (bitwise). | int[] |
| Sorting | l2_squared_distance | double precision | Squared Euclidean distance. Skips the square root calculation for faster distance-based sorting. Formula: 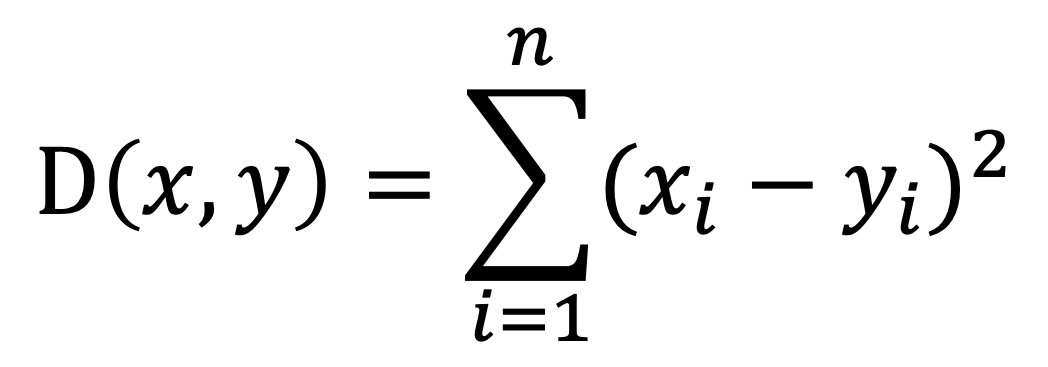 | smallint[], float2[], float4[], real[] |
| Sorting | negative_inner_product_distance | double precision | Negated inner product distance. Used for descending sort by inner product. Formula: 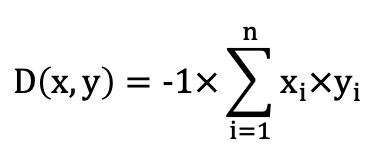 | smallint[], float2[], float4[], real[] |
| Sorting | cosine_distance | double precision | Cosine distance. Range: [0, 2]. Used for descending sort by cosine similarity. Formula: 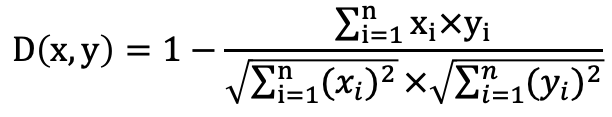 | smallint[], float2[], float4[], real[] |
| Arithmetic | vector_add | smallint[], float2[], or float4[] | Sum of two vector arrays. | smallint[], float2[], float4[], real[] |
| Arithmetic | vector_sub | smallint[], float2[], or float4[] | Difference between two vector arrays. | smallint[], float2[], float4[], real[] |
| Arithmetic | vector_mul | smallint[], float2[], or float4[] | Element-wise product of two vector arrays. | smallint[], float2[], float4[], real[] |
| Arithmetic | vector_div | smallint[], float2[], or float4[] | Element-wise quotient of two vector arrays. | smallint[], float2[], float4[], real[] |
| Aggregation | vector_sum | int or double precision | Sum of all elements in a vector. | smallint[], int[], float2[], float4[], real[], float8[] |
| Aggregation | vector_min | int or double precision | Minimum element value. | smallint[], int[], float2[], float4[], real[], float8[] |
| Aggregation | vector_max | int or double precision | Maximum element value. | smallint[], int[], float2[], float4[], real[], float8[] |
| Aggregation | vector_avg | int or double precision | Average element value. | smallint[], int[], float2[], float4[], real[], float8[] |
| Aggregation | vector_norm | double precision | Norm (length) of a vector. | smallint[], int[], float2[], float4[], real[], float8[] |
| Aggregation | vector_angle | double precision | Angle between two vectors. | smallint[], float2[], float4[], real[] |
vector_add, vector_sub, vector_mul, vector_div, vector_sum, vector_min, vector_max, vector_avg, vector_norm, and vector_angle are supported only in v6.6.1.0 and later. To check your version, see View the minor engine version.
Examples:
-- Euclidean distance
SELECT l2_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Inner product distance
SELECT inner_product_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Cosine similarity
SELECT cosine_similarity(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Dot product distance
SELECT dp_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Hamming distance
SELECT hm_distance(array[1,0,1,0]::int[], array[0,1,0,1]::int[]);
-- Vector addition
SELECT vector_add(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Vector subtraction
SELECT vector_sub(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Vector multiplication
SELECT vector_mul(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Vector division
SELECT vector_div(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- Element sum
SELECT vector_sum(array[1,1,1,1]::real[]);
-- Minimum element
SELECT vector_min(array[1,1,1,1]::real[]);
-- Maximum element
SELECT vector_max(array[1,1,1,1]::real[]);
-- Average element
SELECT vector_avg(array[1,1,1,1]::real[]);
-- Vector norm
SELECT vector_norm(array[1,1,1,1]::real[]);
-- Angle between vectors
SELECT vector_angle(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);Supported operators
All distance operators use the ANN access method and trigger index-accelerated search when a matching vector index exists. If no matching index exists, the query falls back to an exact search.
| Operator | Calculation | Sorting behavior | Equivalent function | Supported data types |
|---|---|---|---|---|
<-> | Squared Euclidean distance | Ascending | l2_squared_distance | smallint[], float2[], float4[], real[] |
<#> | Negative inner product | Descending by dot product | negative_inner_product_distance | smallint[], float2[], float4[], real[] |
<=> | Cosine distance | Descending by cosine similarity | cosine_distance | smallint[], float2[], float4[], real[] |
+ | Vector sum | — | — | smallint[], float2[], float4[], real[] |
- | Vector difference | — | — | smallint[], float2[], float4[], real[] |
* | Element-wise product | — | — | smallint[], float2[], float4[], real[] |
/ | Element-wise quotient | — | — | smallint[], float2[], float4[], real[] |
The +, -, *, and / operators are supported only in v6.6.1.0 and later. To check your version, see View the minor engine version.
Examples:
-- Euclidean distance
SELECT array[1,1,1,1]::real[] <-> array[2,2,2,2]::real[] AS score;
-- Inner product distance
SELECT array[1,1,1,1]::real[] <#> array[2,2,2,2]::real[] AS score;
-- Cosine distance
SELECT array[1,1,1,1]::real[] <=> array[2,2,2,2]::real[] AS score;
-- Addition
SELECT array[1,1,1,1]::real[] + array[2,2,2,2]::real[] AS value;
-- Subtraction
SELECT array[1,1,1,1]::real[] - array[2,2,2,2]::real[] AS value;
-- Multiplication
SELECT array[1,1,1,1]::real[] * array[2,2,2,2]::real[] AS value;
-- Division
SELECT array[1,1,1,1]::real[] / array[2,2,2,2]::real[] AS value;What's next
Vector search — Run ANN queries against your index
Upgrade versions — Check and upgrade the engine version
Enable or disable vector search engine optimization — Manage the FastANN plugin