AnalyticDB for PostgreSQL High-performance Edition uses a single-replica architecture to reduce storage costs and deliver higher write I/O performance than High-availability Edition. It suits analytics workloads where cost efficiency and write throughput matter more than maximum uptime.
High-performance Edition is suitable for most business analysis scenarios. For core business requirements that demand the highest availability, use High-availability Edition.
When to use High-performance Edition
| Criteria | High-performance Edition | High-availability Edition |
|---|---|---|
| Architecture | Single replica | Dual replica (primary + standby) |
| Storage cost | Lower (50% reduction vs. same specs) | Higher |
| Write I/O performance | Higher (no replication overhead) | Lower |
| Recovery from SQL crash | ~10 seconds | 5–10 minutes |
| Recovery from compute node failure | Restart required; no automatic failover | Automatic failover; no service interruption |
| Recovery from host failure | Restart required after host migration; ~15 minutes | Automatic failover; migration runs in background |
| Best for | Analytics, batch processing, cost-sensitive workloads | Mission-critical, production OLAP |
Choose High-performance Edition when your workload can tolerate a recovery window of minutes to hours in the event of a hardware failure. For workloads that require continuous availability during hardware failures, use High-availability Edition.
Architecture
High-performance Edition deploys both coordinator nodes and compute nodes in a single-replica architecture, as shown below.
Figure 1. High-performance Edition architecture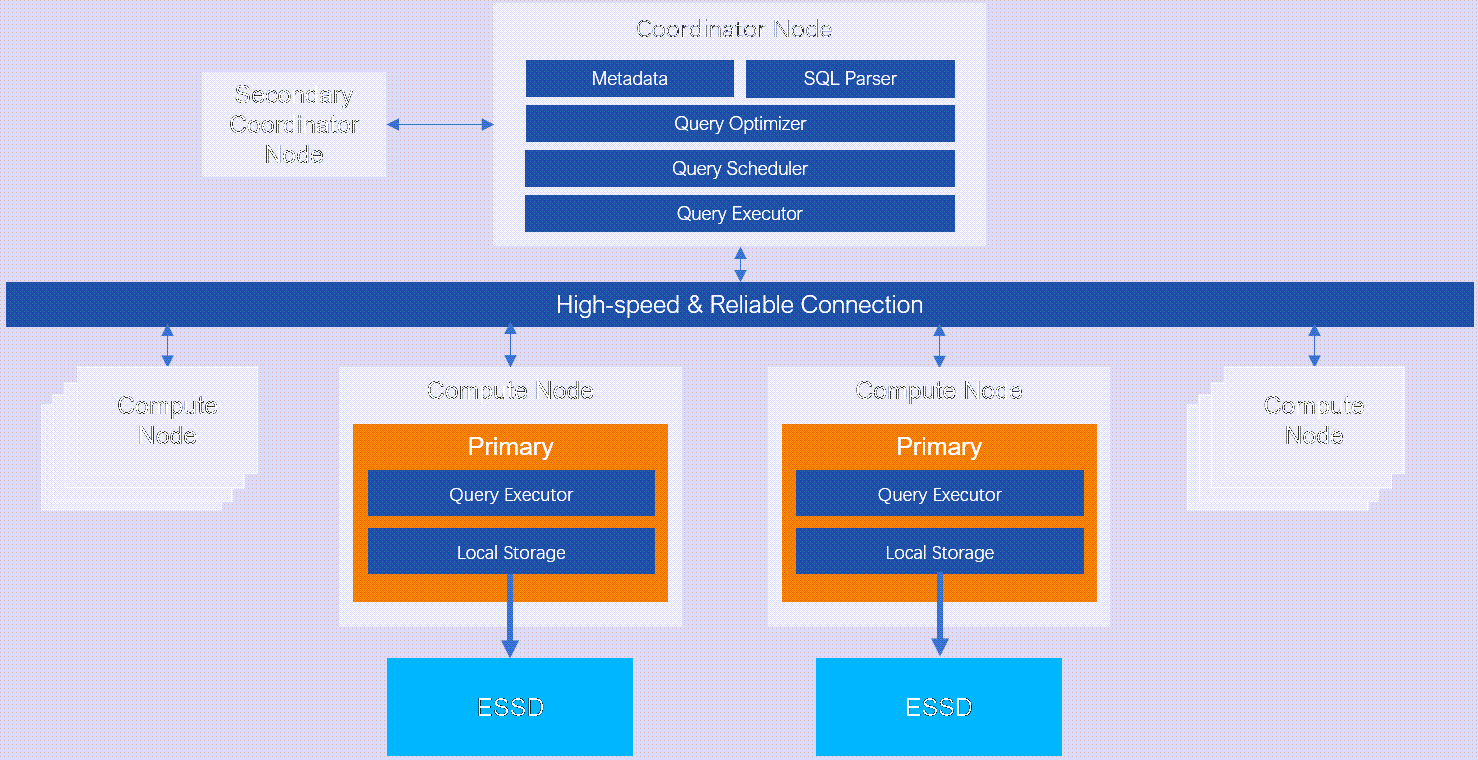
High-availability Edition includes a standby coordinator node and secondary compute nodes.
Figure 2. High-availability Edition architecture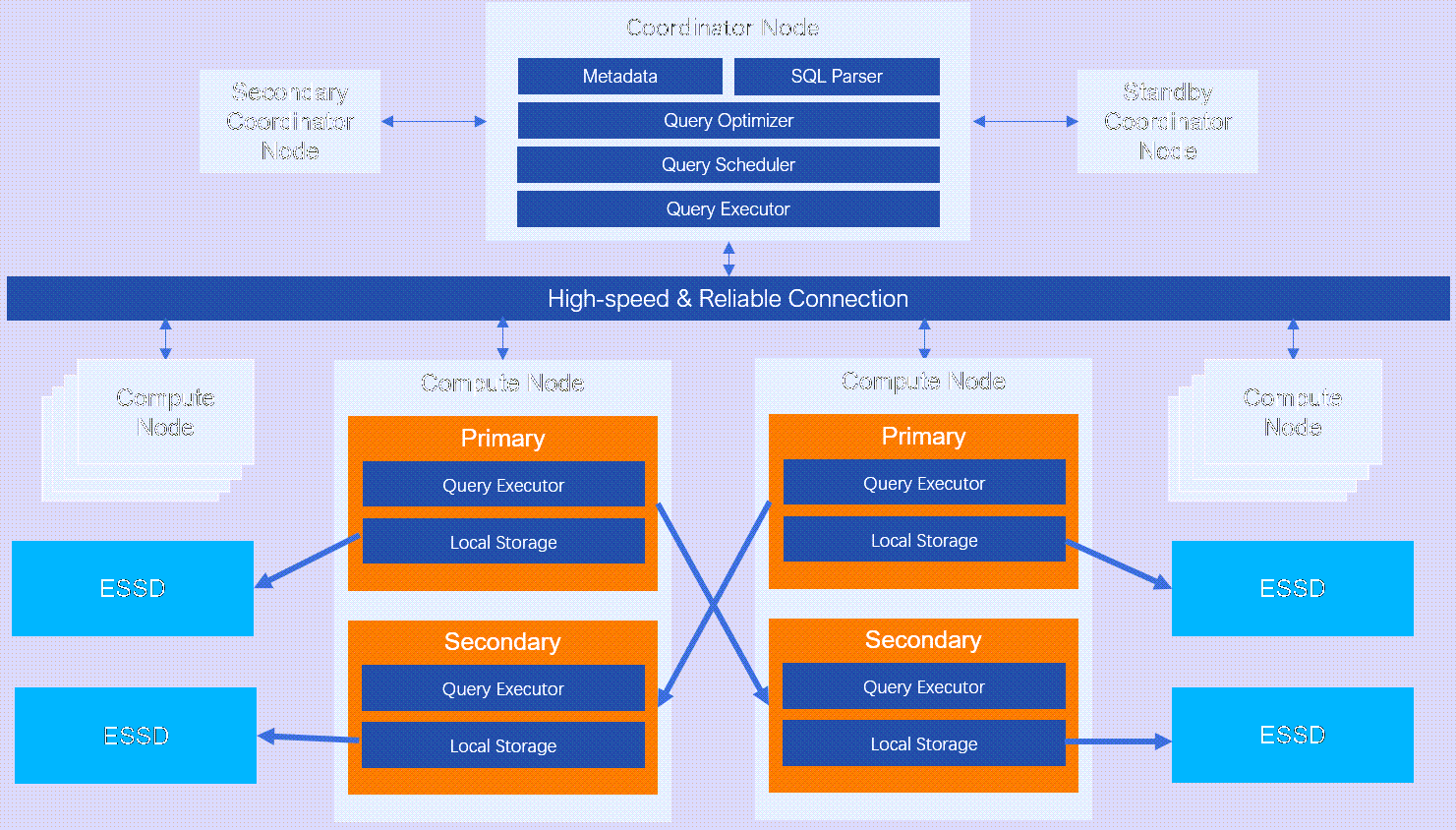
Removing the standby coordinator and secondary compute nodes has three direct effects:
-
No storage is allocated for the standby coordinator node.
-
Compute node storage is reduced by 50%.
-
Data synchronization between primary and secondary compute nodes is eliminated, which improves write I/O performance.
Cost reduction
A High-performance Edition instance with the same specifications costs less than a High-availability Edition instance because it maintains only one replica.
The table below shows USD monthly prices for both editions at two common specification levels.
| Specifications | HPE storage (USD/mo) | HAE storage (USD/mo) | Storage reduction | HPE compute (USD/mo) | HAE compute (USD/mo) | Compute reduction | HPE total (USD/mo) | HAE total (USD/mo) | Total reduction |
|---|---|---|---|---|---|---|---|---|---|
| Entry-level | 22.4 | 100 | 77.6% | 175.55 | 352.05 | 50.13% | 197.95 | 452.05 | 56.21% |
| Common | 89.6 | 200 | 55.2% | 668.65 | 700.28 | 4.52% | 758.25 | 900.28 | 15.78% |
Entry-level specifications: High-performance Edition (HPE) uses 2 CPU cores, 50 GB storage, and 2 compute nodes. High-availability Edition (HAE) uses 2 CPU cores, 50 GB storage, and 4 compute nodes. At these specs, HPE is 56% cheaper.
Common specifications: Both editions use 4 CPU cores, 100 GB storage, and 4 compute nodes. At these specs, HPE is 15% cheaper.
For current pricing, see AnalyticDB for PostgreSQL pricing.
Performance
High-performance Edition delivers higher I/O performance because it eliminates data synchronization and streaming replication between primary and secondary compute nodes. On a 2-CPU-core instance, I/O performance can reach up to 250% of a comparable High-availability Edition instance. Write-intensive workloads see approximately 100% improvement.
The following benchmarks compare both editions configured with 2 CPU cores, 400 GB storage, and 4 compute nodes.
Local replication
Replicating a row-oriented table containing approximately 90 GB of data:
CREATE TABLE lineitem2 AS (SELECT * FROM lineitem);| Edition | Execution time |
|---|---|
| High-performance Edition | 249 seconds |
| High-availability Edition | 1,307 seconds |
High-performance Edition completed the operation approximately 5x faster. The same improvement applies to INSERT INTO SELECT operations.
TPC-H benchmark
This test is based on the TPC-H benchmark methodology but does not satisfy all TPC-H requirements. Results cannot be compared with published TPC-H results.
22 SQL queries were run on a 100 GB TPC-H dataset. The following figure shows the results.
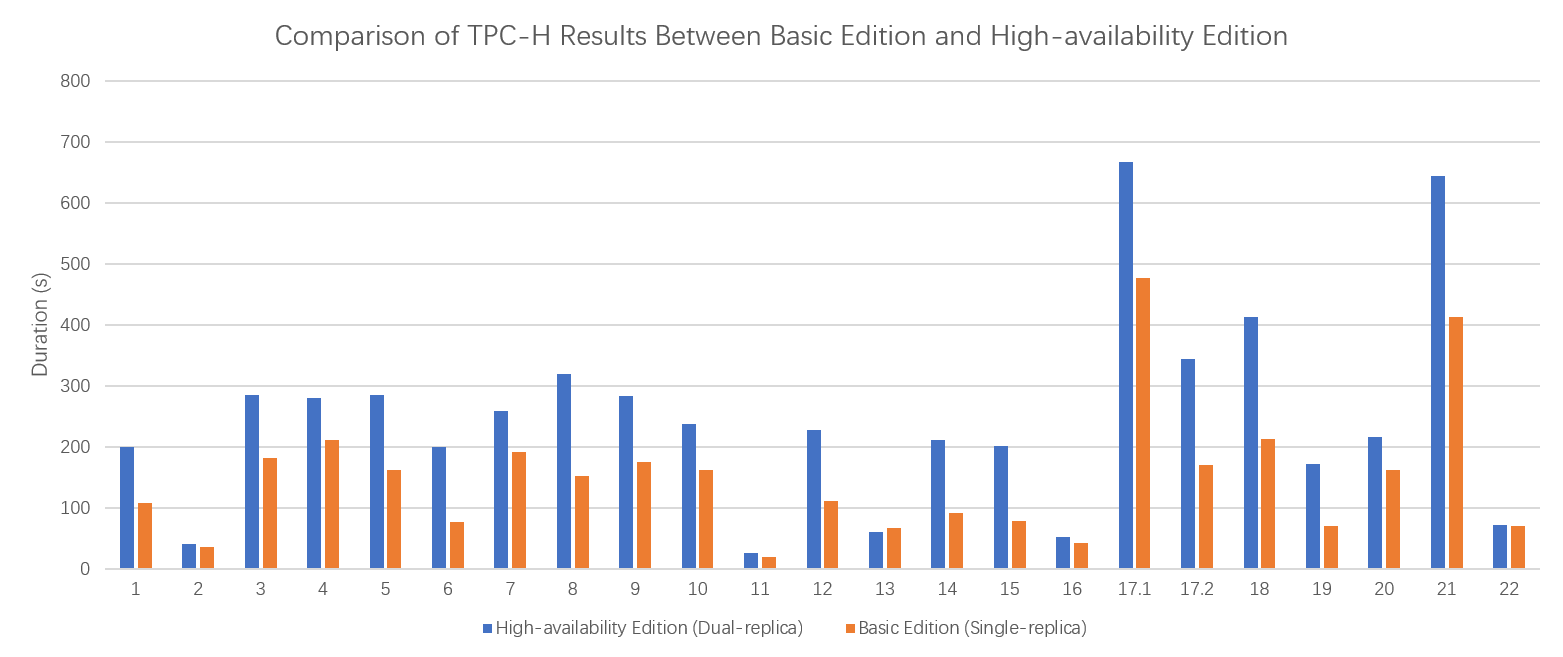
High-performance Edition completed the full query set 40% faster than High-availability Edition, reflecting the I/O advantage of removing replication overhead.
Availability
Data reliability
AnalyticDB for PostgreSQL stores data on enhanced solid-state drives (ESSDs), which use multiple internal replicas at the storage layer. This ensures high data reliability and integrity even in single-replica mode — data is not lost when a compute node fails.
Failure scenarios and recovery
High-performance Edition provides lower availability than High-availability Edition because there is no standby node to fail over to. The table below summarizes recovery behavior for common failure scenarios.
| Failure scenario | High-performance Edition | High-availability Edition |
|---|---|---|
| SQL crash (core dump, out-of-memory (OOM)) | ~10 seconds (optimized checkpoint) | 5–10 minutes |
| Compute node failure | Restart required; service unavailable until restart completes | Automatic failover; secondary node takes over with no service interruption |
| Host failure | Restart required after host migration; ~15 minutes | Automatic failover; host migration runs in background |
For physical machine failures, recovery can take up to 8 hours in extreme scenarios.
How recovery mode works
Most failures in AnalyticDB for PostgreSQL — including SQL crashes caused by core dumps or OOM errors — trigger recovery mode rather than a full node failure. During recovery mode, the instance:
-
Clears remaining locks and memory.
-
Replays Write-Ahead Log (WAL) files to restore committed transactions not yet written to disk.
-
Resumes service.
High-performance Edition uses an optimized checkpoint mechanism that reduces the amount of WAL data to replay. Recovery from these common failure scenarios takes approximately 10 seconds, compared to 5–10 minutes for High-availability Edition.
WAL and checkpoints
-
Write-Ahead Log (WAL): Records all data changes for each transaction before the transaction commits. WAL enables the database to replay changes that were committed but not yet flushed to disk.
-
Checkpoint: The point up to which all data changes are confirmed on disk. The database recovers from the most recent checkpoint. AnalyticDB for PostgreSQL performs checkpoints on a schedule and also triggers them when WAL file size reaches a threshold.
Compute node failures
When a compute node fails in High-availability Edition, the secondary compute node takes over automatically. The faulty node restarts in the background with no service interruption.
When a compute node fails in High-performance Edition, there is no secondary node to take over. The instance becomes unavailable and must be restarted for recovery.
Host failures
Host failures trigger automatic host migration in both editions. In High-availability Edition, the standby node maintains service continuity while the migration runs in the background. In High-performance Edition, the instance must restart after host migration completes — a process that takes approximately 15 minutes.
FAQ
Can I upgrade from High-performance Edition to High-availability Edition?
Direct in-place upgrade is not supported. The two editions use different replica counts and storage configurations, so there is no automated migration path. To switch editions, back up the data from the High-performance Edition instance, purchase a High-availability Edition instance, and restore the data there. For migration instructions, see Migrate data between AnalyticDB for PostgreSQL instances.