When GROUP BY fields have high cardinality — such as mobile number or user ID — AnalyticDB for MySQL's default two-step aggregation performs unnecessary work: partial aggregation runs hash computations, deduplication, and aggregation functions, but produces nearly as many rows as it receives and fails to reduce the data volume sent over the network. Use the /*+ aggregation_path_type=single_agg*/ hint to skip partial aggregation and eliminate that overhead.
How two-step aggregation works
AnalyticDB for MySQL is a distributed data warehousing service. By default, it executes a GROUP BY query in two steps:
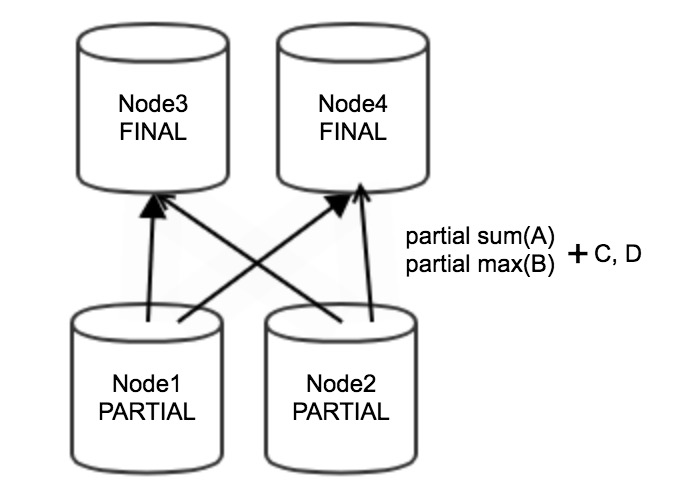
Partial aggregation — Upstream nodes (for example, Node 1 and Node 2) perform partial aggregation on local data. The process is stream-based, so data does not accumulate on aggregation nodes and memory usage stays low. Partial aggregation reduces the volume of data sent over the network to downstream nodes.
Data redistribution and final aggregation — After partial aggregation, data is redistributed among nodes based on the GROUP BY fields. Downstream nodes (for example, Node 3 and Node 4) perform final aggregation. The final aggregation node must hold all values and aggregation state data for each group in memory until every row for that group has been processed, which can result in high memory usage. For background on how data moves between stages, see Factors that affect query performance.
Example: The following query groups data by two columns and computes an aggregate per group:
SELECT sum(A), max(B) FROM tb1 GROUP BY C,D;Node 1 and Node 2 each produce partial results — partial sum(A), partial max(B), C, and D — which are then sent to Node 3 and Node 4 for final aggregation.
Skip partial aggregation for high-cardinality GROUP BY fields
When this optimization applies
Two-step aggregation is efficient when partial aggregation meaningfully reduces the number of rows. It becomes a bottleneck when GROUP BY fields have high cardinality (many unique values), such as mobile number or user ID:
Condition: The aggregation rate is low — partial aggregation produces nearly as many rows as it receives, so it does not reduce the data volume sent to downstream nodes.
Effect: The partial aggregation step still runs hash computations, deduplication, and aggregation function execution, consuming computing resources without reducing network traffic.
Solution: Add the
/*+ aggregation_path_type=single_agg*/hint to skip partial aggregation entirely. All data is sent directly to downstream nodes for final aggregation, eliminating the unnecessary computing overhead.
Apply the hint
Add the hint immediately after SELECT:
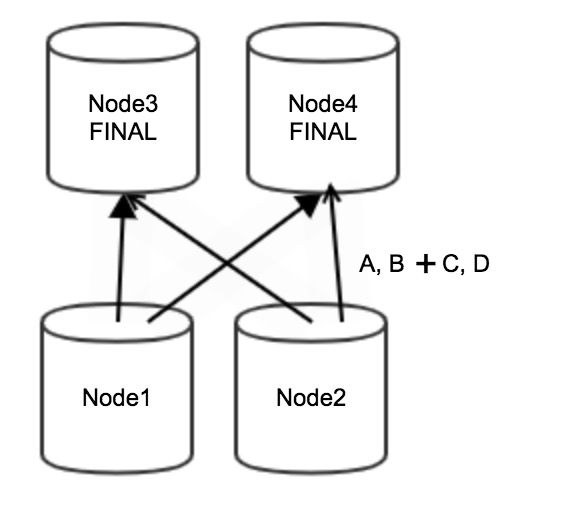
SELECT /*+ aggregation_path_type=single_agg*/ sum(A), max(B) FROM tb1 GROUP BY C,D;After applying the hint, Node 1 and Node 2 skip partial aggregation. All raw data (A, B, C, and D) is redistributed directly to Node 3 and Node 4 for final aggregation.
Trade-offs
| Factor | Two-step aggregation (default) | Single aggregation (hint) |
|---|---|---|
| Best for | Low-cardinality GROUP BY fields | High-cardinality GROUP BY fields |
| Network usage | Lower — partial aggregation reduces data volume | Higher — all raw data is redistributed |
| Computing overhead | Higher when aggregation rate is low | Lower — no partial aggregation step |
| Memory on final node | Lower data volume, but still held in memory | Potentially high — all rows accumulate |
When not to use this optimization
Avoid the hint in these situations:
Low-cardinality GROUP BY fields — If there are few unique group values, partial aggregation effectively reduces network traffic. Skipping it wastes that benefit.
Memory-constrained environments — This hint does not reduce memory usage on the final aggregation node. When the aggregation rate is low, all data accumulates in memory on downstream nodes for deduplication and aggregation. Verify that downstream nodes have enough memory before applying the hint.
Usage notes
The hint applies to all grouping and aggregation queries in the SQL statement, not just specific operators.
Before adding the hint, review the execution plan to identify which aggregation operators have a low aggregation rate and confirm that the expected benefit outweighs the increased memory pressure on final aggregation nodes.