Advanced Horizontal Pod Autoscaler (AHPA) predicts future resource demands by learning historical usage patterns, then scales pod replicas ahead of predicted demand peaks — reducing cold-start delays and improving system stability. When demand is expected to drop, AHPA scales in early to cut resource costs.
Prerequisites
Before you begin, make sure you have:
-
An ACK managed cluster or an ACK Serverless cluster. If not, see Create an ACK managed cluster or Create an ACK Serverless cluster.
-
Managed Service for Prometheus enabled on the cluster. If not, see Connect to and configure Managed Service for Prometheus.
-
At least seven days of application statistics collected by Prometheus, including CPU and memory usage data. AHPA requires this historical data to generate predictions. If your Prometheus instance was just enabled, wait seven days before proceeding to Step 4: Deploy AHPA.
Step 1: Install the AHPA controller
-
Log on to the ACK console. In the left navigation pane, click Clusters.
-
On the Clusters page, click the name of the cluster you want to manage. In the left navigation pane, click Add-ons.
-
On the Add-ons page, find the AHPA Controller card and click Install. Follow the on-screen instructions to complete the installation.
Step 2: Configure Prometheus as a data source
-
Log on to the ARMS console.
-
In the left navigation pane, choose Managed Service for Prometheus > Instances.
-
On the Instances page, select the region where your Prometheus instance is deployed. Click the name of the Prometheus instance. The instance name matches the name of your ACK cluster.
-
On the Settings page, find the HTTP API URL (Grafana Read URL) section and record the internal endpoint. If access tokens are enabled on your cluster, also note the access token.
-
Create a file named
application-intelligence.yamlwith the following content. Replace the placeholder values with your actual Prometheus endpoint and access token.To view Prometheus Service metrics on the AHPA dashboard, add the following parameters to the ConfigMap:
prometheus_writer_url(internal endpoint for Remote Write),prometheus_writer_ak(AccessKey ID), andprometheus_writer_sk(AccessKey secret). For details, see Enable the Prometheus dashboard for AHPA.Placeholder Description prometheusUrlThe internal endpoint of your Prometheus instance tokenThe access token of your Prometheus instance. Required only if access tokens are enabled apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-hangzhou-intranet.arms.aliyuncs.com:9443/api/v1/prometheus/da9d7dece901db4c9fc7f5b9c40****/158120454317****/cc6df477a982145d986e3f79c985a****/cn-hangzhou" token: "eyJhxxxxx" -
Apply the ConfigMap:
kubectl apply -f application-intelligence.yaml
Step 3: Deploy a test service
This step deploys a test environment to compare AHPA predictive scaling against standard Horizontal Pod Autoscaler (HPA) behavior. The environment consists of:
-
fib-deployment: the target workload -
fib-svc: a Service that routes traffic tofib-deployment -
fib-loader: a load generator that simulates traffic fluctuation -
fib-hpa: an HPA policy to provide a baseline for comparison
Create a file named demo.yaml with the following content:
apiVersion: apps/v1
kind: Deployment
metadata:
name: fib-deployment
namespace: default
annotations:
k8s.aliyun.com/eci-use-specs: "1-2Gi"
spec:
replicas: 1
selector:
matchLabels:
app: fib-deployment
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: fib-deployment
spec:
containers:
- image: registry.cn-huhehaote.aliyuncs.com/kubeway/knative-sample-fib-server:20200820-171837
imagePullPolicy: IfNotPresent
name: user-container
ports:
- containerPort: 8080
name: user-port
protocol: TCP
resources:
limits:
cpu: "1"
memory: 2000Mi
requests:
cpu: "1"
memory: 2000Mi
---
apiVersion: v1
kind: Service
metadata:
name: fib-svc
namespace: default
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app: fib-deployment
sessionAffinity: None
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: fib-loader
namespace: default
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: fib-loader
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: fib-loader
spec:
containers:
- args:
- -c
- |
/ko-app/fib-loader --service-url="http://fib-svc.${NAMESPACE}?size=35&interval=0" --save-path=/tmp/fib-loader-chart.html
command:
- sh
env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
image: registry.cn-huhehaote.aliyuncs.com/kubeway/knative-sample-fib-loader:20201126-110434
imagePullPolicy: IfNotPresent
name: loader
ports:
- containerPort: 8090
name: chart
protocol: TCP
resources:
limits:
cpu: "8"
memory: 16000Mi
requests:
cpu: "2"
memory: 4000Mi
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: fib-hpa
namespace: default
spec:
maxReplicas: 50
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: fib-deployment
targetCPUUtilizationPercentage: 50Apply the configuration:
kubectl apply -f demo.yamlStep 4: Deploy AHPA
Start AHPA in observer mode. In this mode, AHPA records its scaling predictions but does not act on them — letting you verify prediction accuracy before enabling automatic scaling.
-
Create a file named
ahpa-demo.yamlwith the following content:apiVersion: autoscaling.alibabacloud.com/v1beta1 kind: AdvancedHorizontalPodAutoscaler metadata: name: ahpa-demo spec: scaleStrategy: observer # Start in observer mode to verify predictions first metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 40 # Scale when average CPU utilization exceeds 40% scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: fib-deployment maxReplicas: 100 minReplicas: 2 stabilizationWindowSeconds: 300 # Wait 300s after a scale-in signal before acting, to prevent flapping prediction: quantile: 0.95 # Confidence level: 95% of historical peaks will be covered scaleUpForward: 180 # Start scaling 180s early to cover pod cold start time instanceBounds: - startTime: "2021-12-16 00:00:00" endTime: "2031-12-16 00:00:00" bounds: - cron: "* 0-8 ? * MON-FRI" maxReplicas: 15 minReplicas: 4 - cron: "* 9-15 ? * MON-FRI" maxReplicas: 15 minReplicas: 10 - cron: "* 16-23 ? * MON-FRI" maxReplicas: 20 minReplicas: 15The following table describes the key parameters.
Parameter Required Default Description scaleTargetRefYes — The Deployment to apply predictive scaling to metricsYes — The metrics that trigger scaling. Supported: CPU, GPU, memory, queries per second (QPS), and response time (RT) target.averageUtilizationYes — The utilization threshold for triggering scaling. For example, 40triggers scaling when average CPU utilization exceeds 40%scaleStrategyNo observerThe scaling mode. See the table below for valid values maxReplicasYes — The maximum number of pod replicas minReplicasYes — The minimum number of pod replicas stabilizationWindowSecondsNo 300The cooldown time of scale-in activities, in seconds prediction.quantileYes 0.99The confidence level for predictions, expressed as a quantile. A higher value yields more conservative predictions — more likely to pre-provision enough capacity. Valid values: 0–1, accurate to two decimal places. Values between0.90and0.99are recommended for most workloadsprediction.scaleUpForwardYes — How many seconds before a predicted demand peak AHPA starts scaling. Set this to match the pod cold start duration (time from pod creation to Ready state) instanceBoundsNo — The duration of a scaling operation. The number of replicated pods is limited by the maximum number and minimum number of replicated pods defined by AHPA instanceBounds.startTimeNo — The start time for the instance bounds rule instanceBounds.endTimeNo — The end time for the instance bounds rule instanceBounds.bounds.cronNo — A cron expression defining when the replica limits apply The
scaleStrategyfield accepts the following values:Value Description observerRecords predictions without performing any scaling. Use this to validate AHPA behavior before going live autoAHPA automatically performs scaling operations proactiveApplies only predictive scaling based on historical patterns reactiveApplies only metric-driven scaling, similar to standard HPA Cron expression format
The
instanceBounds.bounds.cronfield uses the following five-field format:Field Required Valid values Special characters Minutes Yes 0–59 */,-Hours Yes 0–23 */,-Day of month Yes 1–31 */,-?Month Yes 1–12 or JAN–DEC */,-Day of week No 0–6 or SUN–SAT */,-?Special characters:
*(any value),/(increment),,(list separator),-(range),?(placeholder).The Month and Day of week fields are case-insensitive (
SUN,Sun,sunare equivalent). If Day of week is omitted, it defaults to*.For more information about cron expression syntax, see Cron expressions.
-
Apply the AHPA policy:
kubectl apply -f ahpa-demo.yaml
Step 5: Verify predictions and enable auto scaling
AHPA generates predictions from the last seven days of historical data. After applying the policy, wait seven days for predictions to accumulate. To apply an AHPA policy to an existing application, specify the application in the AHPA policy configurations.
During the seven-day accumulation period, confirm your configuration is working correctly:
# Check the AHPA object status
kubectl describe advancedhorizontalpodautoscaler ahpa-demo
# Watch the predicted replica count update over time
kubectl get advancedhorizontalpodautoscaler ahpa-demo -wAfter seven days, review the prediction results using the Prometheus dashboard. For setup instructions, see Enable the Prometheus dashboard for AHPA.
In this example, AHPA runs in observer mode alongside the HPA baseline. The dashboard shows two comparison charts:
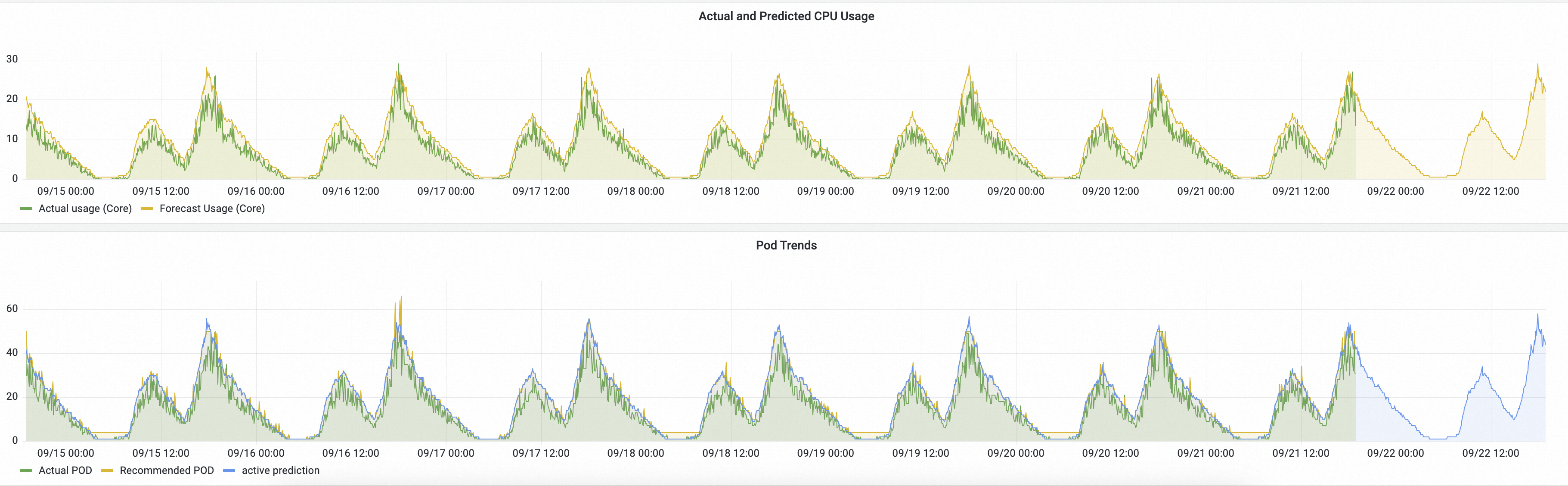
-
CPU usage: The green line shows actual CPU usage (driven by HPA). The yellow line shows AHPA's predicted CPU usage.
-
The predicted value is higher than actual — indicating AHPA pre-provisions sufficient capacity.
-
The predicted value reaches the peak earlier than actual — confirming that resources are ready before demand arrives.
-
-
Pod count: The green line shows actual pods provisioned by HPA. The yellow line shows AHPA's predicted pod count.
-
The predicted pod count (yellow) is lower than the HPA count (green), because AHPA smooths out short-lived spikes.
-
The yellow curve is smoother than the green curve — fewer abrupt changes improves workload stability.
-
Enable automatic scaling
Once the predictions match your expectations, switch AHPA from observer mode to auto mode. Edit ahpa-demo.yaml and change scaleStrategy:
scaleStrategy: autoThen apply the change:
kubectl apply -f ahpa-demo.yamlAHPA now automatically scales fib-deployment using predictive scaling.