When you run Slurm High Performance Computing (HPC) jobs and Kubernetes workloads on the same ACK cluster using static allocation, each Slurm Pod permanently reserves fixed resources — even when idle. Those idle resources are unavailable to Kubernetes, which causes resource fragmentation. Changing a Slurm Pod's resource specs also requires deleting and recreating it, making workload migration difficult when resource demand fluctuates.
The ack-slurm-operator colocated scheduling solution solves this by letting Slurm jobs and Kubernetes Pods share the same physical nodes dynamically. A SlurmCopilot component running in the Kubernetes cluster coordinates resource allocation with Slurm in real time, so both schedulers use the same physical capacity without conflicting over allocations.
How it works
The following figure shows how colocated scheduling works for Slurm HPC and Kubernetes workloads.
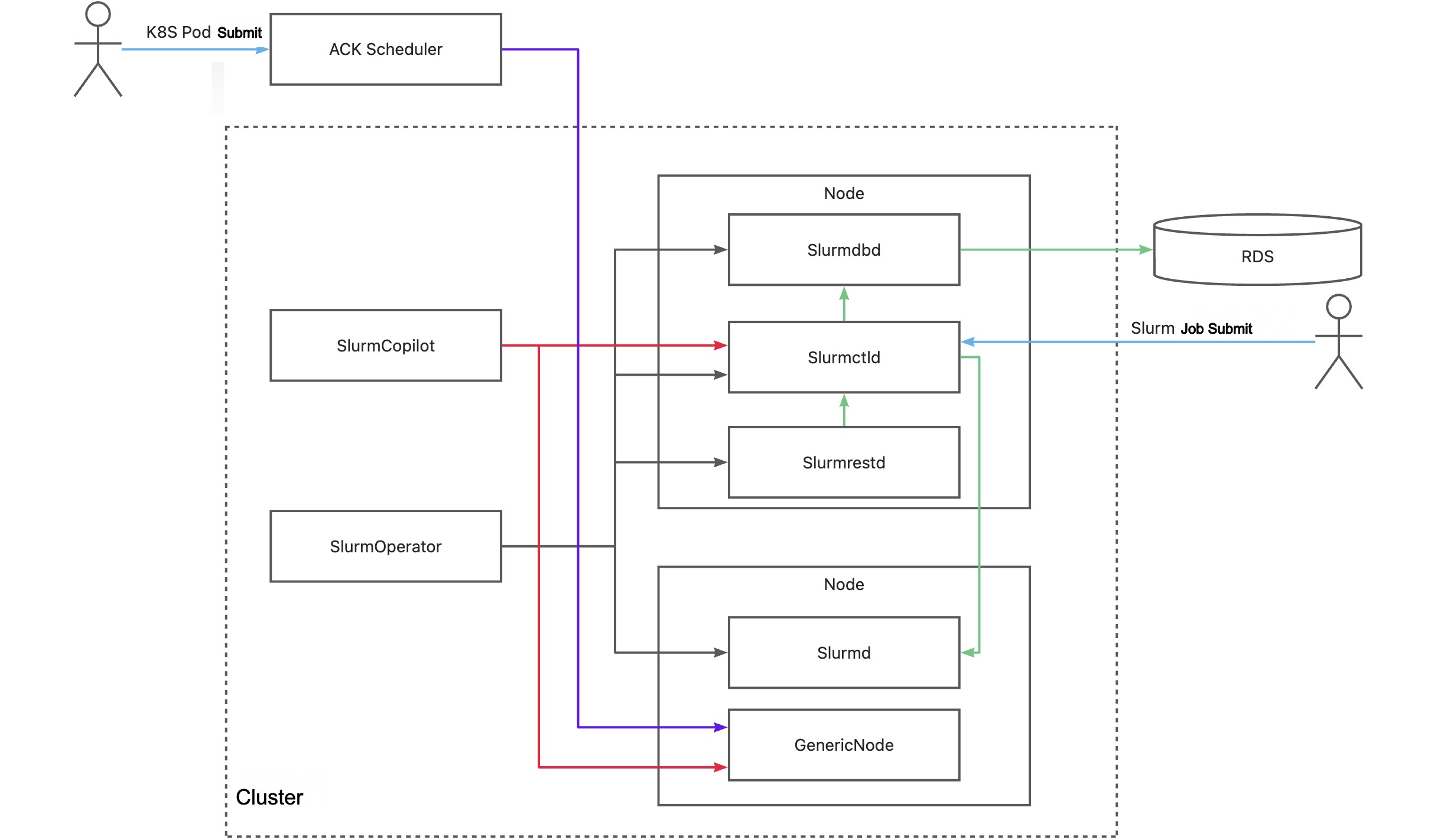
Key components
| Component | Description |
|---|---|
| SlurmOperator | Launches a containerized Slurm cluster. Worker Pods run exclusively on dedicated cluster nodes; other Slurm system components are scheduled on random nodes. |
| SlurmCopilot | Communicates with Slurmctld using a cluster token for resource coordination. When an AdmissionCheck is added to a GenericNode, SlurmCopilot updates the available resources for that node in Slurmctld. After successfully modifying the resources, it writes the status back to the GenericNode and notifies the ACK scheduler to complete scheduling. |
| Slurmctld | The central manager daemon for Slurm. Monitors cluster resources and jobs, schedules jobs, and allocates resources. Supports a backup Slurmctld for high availability. |
| GenericNode | A custom resource that acts as a resource ledger between Kubernetes and Slurm. Before the ACK scheduler places a Pod on a node, it adds an AdmissionCheck to the GenericNode to request resource confirmation from Slurm. |
| Slurmd | The Slurm node daemon. Runs on each compute node, executes jobs, and reports node and job status to Slurmctld. |
| Slurmdbd | The Slurm database daemon for job accounting. Optional — you can store accounting data in files instead. |
| Slurmrestd | The Slurm REST API daemon. Optional — you can interact with Slurm using CLI tools instead. |
By default, when Slurmctld starts, a JWT token is auto-generated and written to a Kubernetes Secret via kubectl. To override this, use a custom startup script or revoke the Secret update permission, then manually update the token in theack-slurm-jwt-tokenSecret in theack-slurm-operatornamespace. In theDatafield, use the cluster name as the key and the Base64-encoded token (base64 --wrap=0) as the value.
Static allocation vs. colocated scheduling
The following table compares the two approaches.
| Static allocation | Colocated scheduling |
|---|---|
 |  |
SlurmCopilot communicates with Slurm using the OpenAPI, so colocated scheduling also works with non-containerized Slurm clusters. See Extend colocated scheduling to non-containerized clusters for details.
Prerequisites
Before you begin, ensure that you have:
An ACK cluster running Kubernetes v1.26 or later. For setup, see Add GPU nodes to a cluster and Upgrade a cluster
Helm installed and configured
Install ack-slurm-operator
Log on to the ACK consoleACK console and click the name of your cluster to open the cluster details page.
Follow the steps shown below to install ack-slurm-operator. Leave the Application Name and Namespace fields blank. After clicking Next, a Confirm dialog box appears. Click Yes to use the default application name (
ack-slurm-operator) and namespace (ack-slurm-operator).
Set the Chart Version to the latest version, set
enableCopilottotrue, and setwatchNamespacetodefault(or a custom namespace). Click OK to complete installation.
(Optional) To update ack-slurm-operator later: on the Cluster Information page, click the Applications > Helm tab, find ack-slurm-operator, and click Update.
Install and configure ack-slurm-cluster
Use Helm to deploy the SlurmCluster chart from Alibaba Cloud. The chart creates all required resources — RBAC, ConfigMaps, Secrets, and the SlurmCluster resource — from a single values.yaml file.
Step 1: Pull the Helm chart
Add the Alibaba Cloud Helm repository.
helm repo add aliyun https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/Pull and unpack the chart. This creates an
ack-slurm-clusterdirectory containing all chart files and templates.helm pull aliyun/ack-slurm-cluster --untar=trueOpen
values.yamlto configure the chart parameters.cd ack-slurm-cluster vi values.yaml
Step 4: Install the chart
Install the chart. If ack-slurm-cluster is already installed, run helm upgrade instead. After an upgrade, manually delete the existing Pods and the Slurmctld StatefulSet to apply configuration changes.
cd ..
helm install my-slurm-cluster ack-slurm-clusterVerify installation
Confirm the chart is deployed.
helm listExpected output:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION ack-slurm-cluster default 1 2024-07-19 14:47:58.126357 +0800 CST deployed ack-slurm-cluster-2.0.0 2.0.0Confirm all Pods are running.
kubectl get podExpected output shows one worker Pod and three control plane Pods running.
NAME READY STATUS RESTARTS AGE slurm-test-slurmctld-dlncz 1/1 Running 0 3h49m slurm-test-slurmdbd-8f75r 1/1 Running 0 3h49m slurm-test-slurmrestd-mjdzt 1/1 Running 0 3h49m slurm-test-worker-cpu-0 1/1 Running 0 166mConfirm Slurmdbd started correctly.
kubectl exec slurm-test-slurmdbd-8f75r cat /var/log/slurmdbd.log | headExpected output:
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. [2024-07-22T19:52:55.727] accounting_storage/as_mysql: _check_mysql_concat_is_sane: MySQL server version is: 8.0.34 [2024-07-22T19:52:55.737] error: Database settings not recommended values: innodb_lock_wait_timeout [2024-07-22T19:52:56.089] slurmdbd version 23.02.7 started
Verify colocated scheduling
Check the GenericNode resource to view resource allocation across both Slurm and Kubernetes.
kubectl get genericnodeExpected output:
NAME CLUSTERNAME ALIAS TYPE ALLOCATEDRESOURCES cn-hongkong.10.1.0.19 slurm-test-worker-cpu-0 Slurm [{"allocated":{"cpu":"0","memory":"0"},"type":"Slurm"},{"allocated":{"cpu":"1735m","memory":"2393Mi"},"type":"Kubernetes"}]Submit a Slurm job and scale a Kubernetes Deployment to observe how allocations are reflected on the GenericNode.
[root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- nohup srun --cpus-per-task=3 --mem=4000 --gres=k8scpu:3,k8smemory:4000 sleep inf & [1] 4132674 [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl scale deployment nginx-deployment-basic --replicas 2 deployment.apps/nginx-deployment-basic scaled [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl get genericnode NAME CLUSTERNAME ALIAS TYPE ALLOCATEDRESOURCES cn-hongkong.10.1.0.19 slurm-test-worker-cpu-0 Slurm [{"allocated":{"cpu":"3","memory":"4000Mi"},"type":"Slurm"},{"allocated":{"cpu":"2735m","memory":"3417Mi"},"type":"Kubernetes"}]Submit a second Slurm job. Because all resources are now allocated, the job enters Pending (PD) state.
[root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- nohup srun --cpus-per-task=3 --mem=4000 sleep inf & [2] 4133454 [root@iZj6c1wf3c25dbynbna3qgZ ~]# srun: job 2 queued and waiting for resources [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 2 debug sleep root PD 0:00 1 (Resources) 1 debug sleep root R 2:34 1 slurm-test-worker-cpu-0
Thesruncommand in step 3 omits the--gresflag because thejob_resource_completionplug-in, loaded at cluster startup, automatically calculates and fills in the GRES amounts from the CPU and memory requests. If this plug-in is not enabled, add--gres=k8scpu:3,k8smemory:4000manually.
Extend colocated scheduling to non-containerized clusters
SlurmCopilot communicates with Slurm via the OpenAPI, so it also supports Slurm clusters that are not running inside containers.
In a non-containerized scenario, create the following Kubernetes resources manually in addition to the JWT token described earlier.
Create a Service for each Slurm cluster. SlurmCopilot retrieves Service information from the cluster and sends OpenAPI requests to
${.metadata.name}.${.metadata.namespace}.svc.cluster.local:${.spec.ports[0].port}. The Service name must be${slurmCluster}-slurmrestd, where${slurmCluster}matches the value specified in the GenericNode.apiVersion: v1 kind: Service metadata: name: slurm-slurmrestd namespace: default spec: ports: - name: slurmrestd port: 8080 protocol: TCP targetPort: 8080Create a DNS record for each Slurm cluster. Create a DNS record that resolves
${.metadata.name}.${.metadata.namespace}.svc.cluster.local:${.spec.ports[0].port}to the address of the Slurmrestd process.Create GenericNode resources for Slurm nodes. GenericNode provides SlurmCopilot with an alias mapping to a node in the Slurm cluster. The GenericNode
namemust match the Kubernetes node name,.spec.aliasmust match the node name in Slurm, and the labelskai.alibabacloud.com/cluster-nameandkai.alibabacloud.com/cluster-namespacemust match the Service.apiVersion: kai.alibabacloud.com/v1alpha1 kind: GenericNode metadata: labels: kai.alibabacloud.com/cluster-name: slurm-test kai.alibabacloud.com/cluster-namespace: default name: cn-hongkong.10.1.0.19 spec: alias: slurm-test-worker-cpu-0 type: Slurm
Summary
With colocated scheduling, you can use Slurm to schedule HPC jobs and Kubernetes to orchestrate containerized workloads on the same cluster. This solution lets you leverage the Kubernetes ecosystem and services, including Helm charts, CI/CD pipelines, and monitoring tools. You can use a unified platform to submit, schedule, and manage both HPC jobs and containerized workloads, consolidating these workloads into a single cluster to use hardware resources more efficiently.