Container Service for Kubernetes (ACK) integrates the Ray autoscaler with Elastic Container Instance (ECI) to let your Ray cluster scale worker pods on demand. Each new worker pod runs as an isolated ECI instance — no Elastic Compute Service (ECS) nodes to purchase, provision, or maintain. You pay only for the resources your containers consume.
How it works
Autoscaling in a KubeRay cluster operates at three levels:
-
Ray actor/task: Some Ray libraries (such as Ray Serve) automatically adjust the number of actors based on incoming request volume.
-
Ray node: The Ray autoscaler adjusts the number of Ray pods based on the *logical* resource demand declared in
@ray.remoteannotations — not physical CPU or memory utilization. When a task or actor requests more resources than the cluster has available, the Ray autoscaler queues the request and provisions new worker pods. Idle nodes are removed automatically over time. -
Kubernetes node: When the Kubernetes cluster lacks capacity for the new Ray pods, the Kubernetes autoscaler can provision additional nodes. This document covers Ray-level autoscaling to ECI virtual nodes.
With ECI, each new Ray worker pod maps to an ECI instance rather than an ECS node, giving you fast, isolated startup without managing the underlying infrastructure.
Example of the cluster architecture
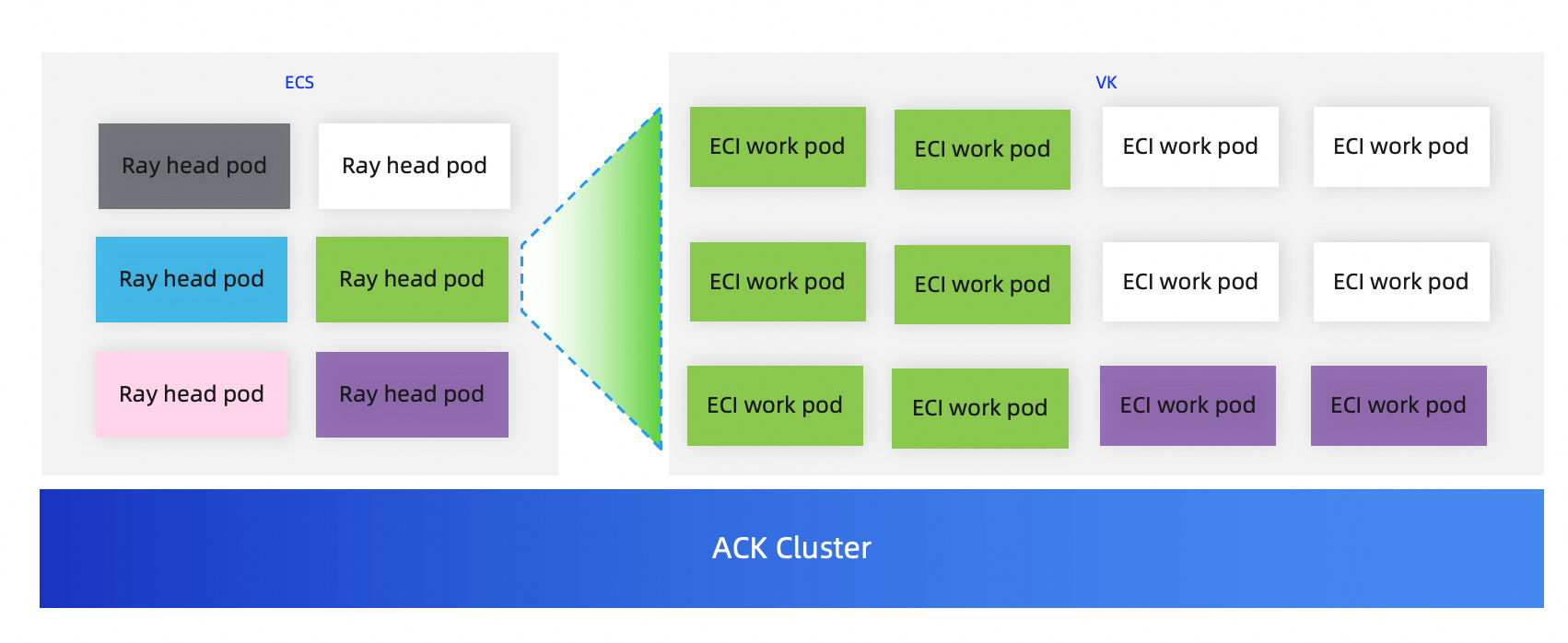
Prerequisites
Before you begin, ensure that you have:
-
A Ray cluster created based on ACK. For more information, see Create a Ray cluster based on ACK.
-
The ack-virtual-node component deployed, with pods scheduled to ECI nodes. For more information, see Use virtual nodes to schedule pods to run on Elastic Container Instance nodes.
-
(Optional) Familiarity with submitting Ray jobs. For more information, see Submit a Ray job.
Configure and verify ECI elastic scaling
Step 1: Verify the virtual-kubelet node
Run the following command to confirm that the virtual-kubelet virtual node is present in your cluster:
kubectl get nodeExpected output:
NAME STATUS ROLES AGE VERSION
cn-hangzhou.172.XX.XX.20 Ready <none> 19h v1.26.3-aliyun.1
cn-hangzhou.172.XX.XX.236 Ready <none> 82m v1.26.3-aliyun.1
cn-hangzhou.172.XX.XX.41 Ready <none> 19h v1.26.3-aliyun.1
virtual-kubelet-cn-hangzhou-k Ready agent 16m v1.26.3-aliyun.1The virtual-kubelet-cn-hangzhou-k node represents the ECI virtual node. Worker pods scheduled to this node run as ECI instances.
Step 2: Create the values.yaml configuration file
Run the following command to create a values.yaml file that labels the worker group for ECI scheduling:
cat > values.yaml <<EOF
worker:
groupName: workergroup
labels:
alibabacloud.com/eci: "true"
EOFThe alibabacloud.com/eci: "true" label instructs the scheduler to place worker pods on the ECI virtual node.
Step 3: Deploy the Ray cluster with ECI support
Run the following commands to redeploy your Ray cluster with the updated configuration:
helm uninstall ${RAY_CLUSTER_NAME} -n ${RAY_CLUSTER_NS}
helm install ${RAY_CLUSTER_NAME} aliyunhub/ack-ray-cluster -n ${RAY_CLUSTER_NS} -f values.yamlStep 4: Verify the head pod is running
Run the following command to confirm the head pod is ready:
kubectl get podExpected output:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myfirst-ray-cluster-head-7fgp4 2/2 Running 0 7m2s 172.16.0.241 cn-hangzhou.172.16.0.240 <none> <none>The head pod runs on a regular ECS node. Its --num-cpus is set to 0 by default, which means the Ray autoscaler does not schedule compute tasks on the head pod — all tasks go to worker pods.
Step 5: Log in to the head node
Replace the pod name with the actual name of your head pod, then run:
kubectl -n ${RAY_CLUSTER_NS} exec -it myfirst-ray-cluster-head-7fgp4 -- bashStep 6: Submit a Python job to trigger scale-out
The following script submits two tasks, each requiring 1 vCPU. Because the head pod has --num-cpus=0 and each worker pod provides 1 vCPU and 1 GB of memory by default, the Ray autoscaler detects the unmet logical resource demand and provisions two new ECI worker pods.
The Ray autoscaler scales based on *logical* resource requests declared in @ray.remote, not on physical CPU or memory utilization. The num_cpus=1 declaration per task is what triggers scale-out — not actual CPU usage.
import time
import ray
import socket
ray.init()
@ray.remote(num_cpus=1)
def get_task_hostname():
time.sleep(120)
host = socket.gethostbyname(socket.gethostname())
return host
object_refs = []
for _ in range(2):
object_refs.append(get_task_hostname.remote())
ray.wait(object_refs)
for t in object_refs:
print(ray.get(t))Step 7: Verify scale-out
Run the following command to confirm that two ECI worker pods are provisioned on the virtual node:
kubectl get pod -o wideExpected output:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myfirst-ray-cluster-head-7fgp4 2/2 Running 0 4m56s 172.16.0.241 cn-hangzhou.172.16.0.240 <none> <none>
myfirst-ray-cluster-worker-workergroup-6s2cl 0/1 Init:0/1 0 4m5s 172.16.0.17 virtual-kubelet-cn-hangzhou-k <none> <none>
myfirst-ray-cluster-worker-workergroup-l9qgb 1/1 Running 0 4m5s 172.16.0.16 virtual-kubelet-cn-hangzhou-k <none>Both worker pods run on virtual-kubelet-cn-hangzhou-k, confirming they are ECI instances. Init:0/1 means the pod is still initializing — it transitions to Running once the ECI instance is ready.
After the tasks complete and the pods remain idle, the Ray autoscaler automatically terminates the worker pods.
What's next
-
Virtual nodes — learn more about how virtual nodes work in ACK.
-
Elastic scaling based on the Ray autoscaler and ACK autoscaler — configure autoscaling for ECS nodes alongside ECI scaling.