Distributed training workloads spread across multiple GPU nodes incur significant cross-node communication overhead during gradient synchronization. ACK supports topology-aware GPU scheduling based on the scheduling framework, which selects GPUs based on their physical interconnect topology—placing workers on GPUs that share high-bandwidth NVLink connections—to reduce this overhead and maximize training throughput. This topic shows how to apply topology-aware GPU scheduling to TensorFlow distributed training jobs and compare the results against regular GPU scheduling.
Prerequisites
Before you begin, ensure that you have:
-
An ACK Pro cluster with the instance type set to Elastic GPU Service. See Create an ACK managed cluster
-
Arena installed
-
Component versions that meet the following requirements:
| Component | Required version | Check command |
|---|---|---|
| Kubernetes | 1.18.8 and later | kubectl version --short |
| NVIDIA driver | 418.87.01 and later | nvidia-smi --query-gpu=driver_version --format=csv,noheader |
| NCCL (NVIDIA Collective Communications Library) | 2.7 and later | python3 -c "import torch; print(torch.cuda.nccl.version())" |
| Operating system | CentOS 7.6, CentOS 7.7, Ubuntu 16.04, Ubuntu 18.04, Alibaba Cloud Linux 2, Alibaba Cloud Linux 3 | cat /etc/os-release |
| GPU | V100 | nvidia-smi --query-gpu=name --format=csv,noheader |
Complete the prerequisites in order. Create the ACK Pro cluster first, then install Arena, and finally install the topology-aware GPU scheduling component. Installing components out of order may cause failures.
Limitations
Topology-aware GPU scheduling applies only to Message Passing Interface (MPI) jobs trained with a distributed framework.
Regular GPU scheduling assigns GPUs based on availability alone, without considering physical interconnect topology. This means workers can be placed on GPUs across different nodes connected only by slower network links, making cross-GPU communication the primary bottleneck. Topology-aware scheduling solves this by grouping workers on GPUs that share NVLink connections within the same node, significantly reducing gradient synchronization latency.
Pods are created only when all requested resources can be satisfied simultaneously (gang scheduling). If resources are insufficient, the job remains pending until enough GPUs are available.
Configure nodes
Label each node to enable topology-aware GPU scheduling:
kubectl label node <your-node-name> ack.node.gpu.schedule=topologyEnabling topology-aware scheduling on a node disables regular GPU scheduling for that node. To revert to regular GPU scheduling, run:
kubectl label node <your-node-name> ack.node.gpu.schedule=default --overwriteSubmit a job
Submit an MPI job with --gputopology=true and --gang:
arena submit mpi --gputopology=true --gang <other-parameters>Both flags are required: --gputopology=true enables topology-aware GPU selection, and --gang enforces gang scheduling so all workers start simultaneously.
Example 1: Train VGG16
The cluster in this example has two nodes, each with eight V100 GPUs.
Topology-aware GPU scheduling
-
Submit the training job:
arena submit mpi \ --name=tensorflow-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod" -
Check the job status:
arena get tensorflow-topo-4-vgg16 --type mpijobExpected output:
Name: tensorflow-topo-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 2m Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-topo-4-vgg16-launcher-lmhjl Running 2m true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-vgg16-worker-0 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-1 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-2 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-3 Running 2m false 1 cn-shanghai.192.168.16.173All four workers are placed on the same node, sharing its high-bandwidth GPU interconnect.
-
View the training log:
arena logs -f tensorflow-topo-4-vgg16Expected output:
total images/sec: 991.92
Regular GPU scheduling
-
Submit the training job without topology flags:
arena submit mpi \ --name=tensorflow-4-vgg16 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod" -
Check the job status:
arena get tensorflow-4-vgg16 --type mpijobExpected output:
Name: tensorflow-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 9s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-4-vgg16-launcher-xc28k Running 9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-0 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-1 Running 9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-vgg16-worker-2 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-3 Running 9s false 1 cn-shanghai.192.168.16.173Workers are spread across two nodes, requiring cross-node communication for each gradient synchronization step.
-
View the training log:
arena logs -f tensorflow-4-vgg16Expected output:
total images/sec: 200.47
Example 2: Train ResNet50
Topology-aware GPU scheduling
-
Submit the training job:
arena submit mpi \ --name=tensorflow-topo-4-resnet50 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod" -
Check the job status:
arena get tensorflow-topo-4-resnet50 --type mpijobExpected output:
Name: tensorflow-topo-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 8s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-topo-4-resnet50-launcher-7ln8j Running 8s true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-resnet50-worker-0 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-1 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-2 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-3 Running 8s false 1 cn-shanghai.192.168.16.173 -
View the training log:
arena logs -f tensorflow-topo-4-resnet50Expected output:
total images/sec: 1471.55
Regular GPU scheduling
-
Submit the training job without topology flags:
arena submit mpi \ --name=tensorflow-4-resnet50 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod" -
Check the job status:
arena get tensorflow-4-resnet50 --type mpijobExpected output:
Name: tensorflow-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 9s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-4-resnet50-launcher-q24hv Running 9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-0 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-1 Running 9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-resnet50-worker-2 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-3 Running 9s false 1 cn-shanghai.192.168.16.173 -
View the training log:
arena logs -f tensorflow-4-resnet50Expected output:
total images/sec: 745.38
Performance comparison
The following chart shows throughput for VGG16 and ResNet50 training under topology-aware and regular GPU scheduling.
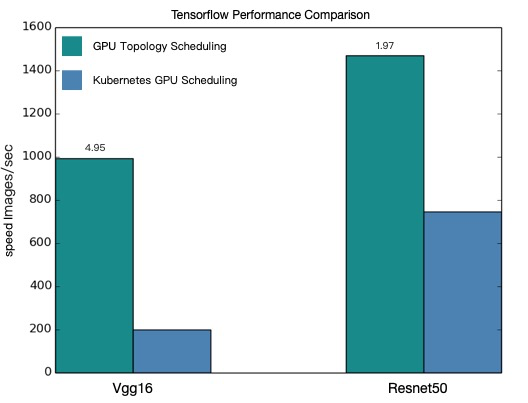
| Model | Topology-aware (images/sec) | Regular (images/sec) | Improvement |
|---|---|---|---|
| VGG16 | 991.92 | 200.47 | ~4.9x |
| ResNet50 | 1471.55 | 745.38 | ~2.0x |
The performance values in this topic are theoretical values. Actual results vary based on your model architecture, cluster configuration, and network conditions. Run the examples above in your own cluster to measure actual gains.