ACK Pro edition clusters support GPU sharing through cGPU, which lets multiple containers share a single GPU by dividing its compute time into slices. This topic explains how to set the computing power allocation policy (the POLICY field in the cGPU DaemonSet) that controls how those time slices are distributed across containers.
For an introduction to cGPU, see What is cGPU.
Prerequisites
Before you begin, ensure that you have:
-
An ACK Pro edition cluster running Kubernetes 1.18.8 or later. To upgrade Kubernetes, see the referenced document
-
cGPU version 1.0.6 or later. To upgrade cGPU, see the referenced document
Constraints
-
All shared GPU nodes in a cluster must use the same policy.
-
If the cGPU isolation module is already installed on a node, restart the node after you install the shared GPU component for the policy to take effect. To restart a node, see the referenced document.
Run
cat /proc/cgpu_km/versionon the node to check whether the isolation module is installed. If the command returns a version number, the module is installed. -
If the cGPU isolation module is not installed, the policy takes effect immediately after you install the shared GPU component.
Policy values
cGPU supports six scheduling policies. Choose the one that matches your workload requirements.
| Value | Policy | Description |
|---|---|---|
0 |
Average scheduling | Each container receives a fixed time slice. The ratio is 1/max_inst. |
1 |
Preemptive scheduling | Each container takes as many time slices as possible. The ratio is 1/current_number_of_containers. |
2 |
Weighted preemptive scheduling | Applied automatically when ALIYUN_COM_GPU_SCHD_WEIGHT is greater than 1. |
3 |
Fixed computing power scheduling | Assigns a fixed percentage of compute to each container. |
4 |
Weak computing power scheduling | Provides lighter isolation than preemptive scheduling. |
5 |
Native scheduling | Uses the GPU driver's own scheduling method. |
For more details on policy behavior and examples, see cGPU Service Usage Example.
Step 1: Check whether the shared GPU component is installed
The configuration procedure differs depending on whether the shared GPU component is already installed.
-
Log on to the ACK console. In the left navigation pane, click Clusters.
-
On the Clusters page, click the name of your cluster. In the left navigation pane, click Applications > Helm.
-
On the Helm page, check whether ack-ai-installer appears in the component list.
-
If ack-ai-installer is listed, the shared GPU component is installed. Proceed to Configure the policy when the component is installed.
-
If it is not listed, the component is not installed. Proceed to Configure the policy when the component is not installed.
-
Step 2: Configure the policy
Configure the policy when the component is not installed
-
Log on to the ACK console. In the left navigation pane, click Clusters.
-
On the Clusters page, click the name of your cluster. In the left navigation pane, click Applications > Cloud-native AI Suite.
-
On the Cloud-native AI Suite page, click Deploy.
-
In the Scheduling area, select Scheduling Policy Extension (Batch Task Scheduling, GPU Sharing, Topology-aware GPU Scheduling). Then click Advanced on the right.
-
On the Parameters page, set the
policyfield to your target policy value. Then click OK.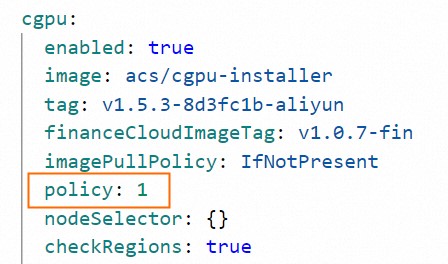
-
At the bottom of the page, click Deploy Cloud-native AI Suite.
Configure the policy when the component is installed
-
Edit the DaemonSet that installs the cGPU isolation module:
kubectl edit daemonset cgpu-installer -nkube-system -
Verify that the image version is v1.0.6 or later. The
imagefield looks similar to:image: registry-vpc.cn-hongkong.aliyuncs.com/acs/cgpu-installer:<Image Version> -
Under
spec.containers[].env, set thevalueofPOLICYto your target policy value:# Other fields are omitted. spec: containers: - env: - name: POLICY value: "1" # Other fields are omitted. -
Save the file to apply the change.
-
Restart the shared GPU node. For details, see the referenced document.
What's next
-
To learn how to use cGPU policies in practice with workload examples, see cGPU Service Usage Example.