CLB通过健康检查判断后端服务器的可用性。开启健康检查后,如果某台后端服务器异常,CLB会将请求分发到其他正常的服务器。当该服务器恢复正常,CLB会重新将其流量转发。健康检查机制提高了业务整体可用性,避免了局部服务器异常对服务的影响。
如果您的业务对负载敏感,高频率的健康检查可能影响正常业务访问。您可以根据业务情况,通过降低健康检查频率、增大检查间隔、将七层检查改为四层检查等方式,来降低影响。但为了保障业务的持续可用,不建议关闭健康检查。
健康检查过程
健康检查是通过定期发送请求来确认服务器的状态。
CLB采用集群部署,集群内的节点服务器同时负责数据转发和健康检查。如果某台服务器健康检查失败,则不会再将新的客户端请求分发给该异常服务器。
CLB健康检查使用的地址段是100.64.0.0/10,后端服务器务必不能屏蔽该地址段。您无需在ECS安全组中额外配置放行策略,但如有配置iptables等安全策略,请务必放行(100.64.0.0/10 是阿里云保留地址,不会存在安全风险)。

HTTP/HTTPS监听健康检查机制
七层监听(HTTP/HTTPS)通过HEAD或GET请求进行健康检查。
HTTPS监听的证书由CLB系统管理,数据交互使用HTTP以提高性能。

七层监听的检查机制如下:
服务器根据配置向后端服务器发送HTTP HEAD请求。
后端服务器返回HTTP状态码。
若在响应超时时间内未收到响应,则判定健康检查失败。
若在响应超时时间内收到响应,则比对状态码,匹配则成功,否则失败。
CLB 健康检查默认仅将 HTTP 2XX 和 3XX 状态码视为健康状态。如果后端服务器返回 4XX(如 400、403、404、429)或 5XX(如 500、502、503)状态码,健康检查将判定为失败。
建议创建专用健康检查端点(如 /health)并确保返回 HTTP 200 状态码,而非将 4XX/5XX 加入健康状态码范围。
TCP监听健康检查机制
为了提高四层TCP监听的健康检查效率,健康检查通过定制的TCP探测来获取状态信息,如下图所示。

TCP监听的检查机制如下:
四层集群中的服务器根据健康检查配置,向后端服务器的内网IP和健康检查端口发送TCP SYN数据包。
后端服务器收到请求后,如果相应端口正在正常监听,则返回SYN+ACK数据包。
如果在响应超时时间内,四层集群中的服务器没有收到后端服务器返回的数据包,则认为服务无响应,判定健康检查失败,并发送RST数据包中断TCP连接。
如果在响应超时时间内,四层集群中的服务器成功收到后端服务器返回的数据包,则认为服务正常运行,判定健康检查成功,并发送RST数据包中断TCP连接。
该机制可能会导致后端服务器认为相关TCP连接异常,并在业务软件日志中抛出Connection reset by peer错误信息。
解决方案:
TCP监听采用HTTP方式进行健康检查。
在后端服务器配置获取客户端真实IP后,忽略来自CLB服务地址段的连接错误。
UDP监听健康检查
针对四层UDP监听,健康检查通过UDP报文探测来获取状态信息,如下图所示。

UDP监听的检查机制如下:
四层集群中的服务器根据监听的健康检查配置,向后端服务器的内网IP+【健康检查端口】发送UDP报文。
如果后端服务器相应端口未正常监听,则系统会返回类似
port XX unreachable的ICMP报错信息,反之不做任何处理。如果在【响应超时时间】之内,四层集群中的服务器收到了后端服务器返回的上述错误信息,则认为服务异常,判定健康检查失败。
如果在【响应超时时间】之内,四层集群中的服务器没有收到后端服务器返回的任何信息,则认为服务正常,判定健康检查成功。
当前UDP协议服务健康检查可能存在服务真实状态与健康检查不一致的问题:
如果后端服务器是Linux服务器,在大并发场景下,由于Linux的防ICMP攻击保护机制,会限制服务器发送ICMP的速度。此时,即便服务已经出现异常,但由于无法向前端返回port XX unreachable报错信息,会导致负载均衡由于没收到ICMP应答进而判定健康检查成功,最终导致服务真实状态与健康检查不一致。
解决方案:
负载均衡通过发送指定字符串到后端服务器,并在收到指定应答后判定检查成功。此机制需要客户端程序配合。
健康检查时间窗
健康检查机制提高了服务可用性,但为了避免频繁切换影响系统,只有在健康检查时间窗内连续多次检查成功或失败后,才会进行状态切换。健康检查时间窗由以下三个因素决定:
健康检查间隔(每隔多久进行一次健康检查)
响应超时时间 (等待服务器返回健康检查的时间)
检查阈值(健康检查连续成功或失败的次数)
健康检查时间窗口的计算方法如下:
健康检查失败时间窗口=响应超时时间×不健康阈值+检查间隔×(不健康阈值-1)
健康检查成功时间窗口= (健康检查成功响应时间x健康阈值)+检查间隔x(健康阈值-1)
说明健康检查成功响应时间是一次健康检查请求从发出到响应的时间。TCP方式健康检查时间非常短,几乎可以忽略不计;HTTP方式健康检查时间取决于服务器性能和负载,通常在秒级以内。

健康检查状态对请求转发的影响如下:
如果目标后端服务器的健康检查失败,新的请求不会再分发到相应后端服务器上,所以对前端访问没有影响。
如果目标后端服务器的健康检查成功,新的请求会分发到该后端服务器上,前端访问正常。
如果目标后端服务器存在异常,正处于健康检查失败时间窗,而健康检查还未达到检查失败判定次数(默认为三次),则相应请求还是会被分发到该后端服务器,进而导致前端访问请求失败。

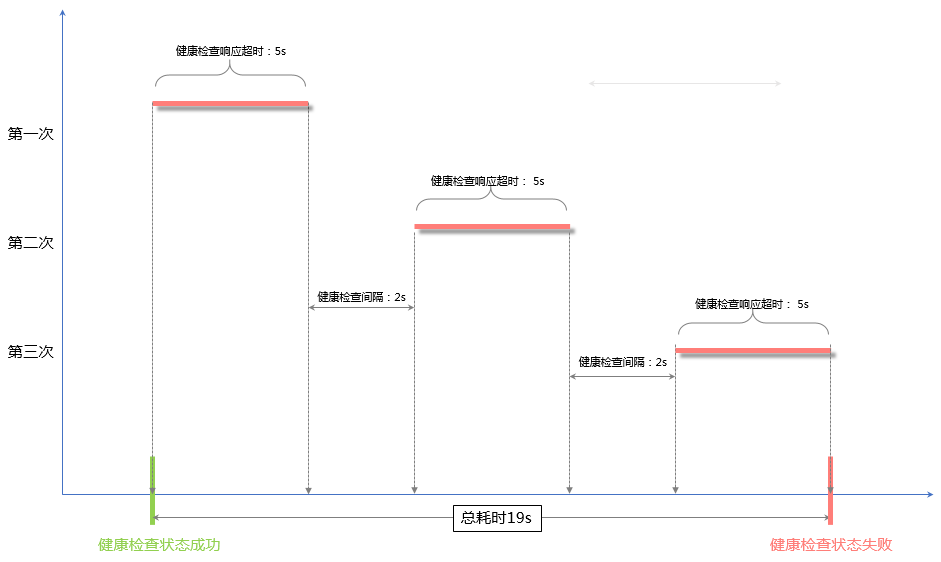
健康检查响应超时和健康检查间隔示例
以如下健康检查配置为例:
响应超时时间:5秒
健康检查间隔:2秒
健康阈值:3次
不健康阈值:3次
健康检查失败时间窗口=响应超时时间×不健康阈值+检查间隔×(不健康阈值-1),5×3+2×(3-1)=19s,即以19s为一个时间窗,健康检查响应时间超过19s,健康检查状态为不健康。
健康检查成功时间窗口= (健康检查成功响应时间×健康阈值)+检查间隔×(健康阈值-1),(1×3)+2×(3-1)=7s,即以7s为一个时间窗,健康检查成功响应时间低于7s,健康检查状态为健康。
健康检查成功响应时间是一次健康检查请求从发出到响应的时间。当采用TCP方式健康检查时,由于仅探测端口是否存活,因此该时间非常短,几乎可以忽略不计。当采用HTTP方式健康检查时,该时间取决于应用服务器的性能和负载,但通常都在秒级以内。
HTTP健康检查中域名的设置
使用HTTP方式进行健康检查时,可以设置域名,但这不是强制的。有些应用服务器会校验请求中的host字段,要求请求头中必须存在host字段。如果配置了域名,CLB会将其添加到host字段中。如果没有配置域名,健康检查请求可能会被服务器拒绝,导致检查失败。
因此,如果您的应用服务器需要校验host字段,请配置相关域名以确保健康检查正常工作。
相关文档
健康检查需要在添加监听时配置,具体操作可参考配置和管理CLB健康检查。
健康检查常见问题可参考CLB健康检查FAQ。