Classic Load Balancer (CLB) performs health checks to check the availability of backend servers. After health checks are enabled, if a backend server is declared unhealthy, CLB distributes requests to other backend servers. When the unhealthy backend server becomes healthy, requests fail back to the backend server. Health checks improve the availability of applications because health checks can prevent single points of failure (SPOFs).
If your business is highly sensitive to traffic fluctuations, frequent health checks may affect the availability of your business. To reduce the adverse impacts of health checks on your business, you can reduce the health check frequency, increase the health check interval, or change Layer 7 health checks to Layer 4 health checks. To ensure business continuity, we recommend that you enable the health check feature.
How health checks work
Health checks refer to sending requests periodically to backend servers to check the servers' status.
CLB instances are deployed in clusters. Nodes in the clusters are responsible for forwarding network traffic and performing health checks.
If a backend server fails health checks performed by a node in a cluster, the backend server is declared unhealthy. All nodes in the cluster stop distributing requests to the unhealthy backend server.
CLB health checks originate from the CIDR block 100.64.0.0/10, which is reserved by Alibaba Cloud. You do not need to configure a security group rule to allow access from this CIDR block unless you have configured security rules such as iptables. Permitting this CIDR block does not increase potential risks.

How CLB performs HTTP and HTTPS health checks
For HTTP and HTTPS listeners at Layer 7, health checks use the HEAD or GET method to probe the availability of backend servers.
Certificates of HTTPS listeners are managed in CLB. Data between CLB and backend servers is exchanged over HTTP to improve system performance.

How CLB performs Layer 7 health checks:
Nodes send HTTP Head requests to the backend servers based on health check configurations.
The backend servers return HTTP status codes.
If the nodes receive no response within the timeout period, the backend servers are declared unhealthy.
If the nodes receive a response within the timeout period, the returned HTTP status code is compared against the specified HTTP status codes. If the returned status code matches one of the specified status codes, the backend servers are declared healthy. If the returned status code matches no specified status codes, the backend servers are declared unhealthy.
How CLB performs TCP health checks
To improve the health check efficiency for TCP listeners, the CLB instance performs Layer 4 health checks (TCP health checks) by establishing TCP sessions, as shown in the following figure.

How CLB performs TCP health checks:
Nodes in Layer 4 clusters send TCP SYN packets to the internal IP addresses and health check ports of backend servers based on health check configurations.
If the backend server ports are alive, the backend servers return SYN-ACK packets after they receive the TCP-SYN packets.
If the nodes in the Layer 4 clusters do not receive a SYN-ACK packet within the timeout period, the backend servers are declared unhealthy. The nodes send RST packets to close the TCP connections.
If the nodes in the Layer 4 clusters receive a SYN-ACK packet within the timeout period, the backend servers are declared healthy. The nodes send RST packets to close the TCP connections.
This mechanism may cause false TCP connection errors on backend servers. As a result, the backend servers may record error messages such as Connection reset by peer in software logs.
Solution:
Configure HTTP health checks for TCP listeners.
Enable client IP preservation on backend servers to ignore connection errors triggered by requests from CLB endpoints.
How CLB performs UDP health checks
If you add UDP listeners to your CLB instance, CLB checks the status of backend servers by sending UDP packets, as shown in the following figure.

How CLB performs UDP health checks:
Nodes in Layer 4 clusters send UDP packets to the internal IP addresses and health check ports of backend servers based on health check configurations of listeners.
If the backend server ports are not alive, an ICMP error message such as
port XX unreachableis returned. Otherwise, no ICMP error message is returned.If the nodes in the Layer 4 clusters receive ICMP error messages within the timeout period, the backend servers are declared unhealthy.
If the nodes in the Layer 4 clusters do not receive ICMP error messages within the timeout period, the backend servers are declared healthy.
UDP health check results may not reflect the actual status of the application on a backend server in the following situation:
If a Linux backend server is used in high concurrency scenarios, the ICMP flood protection feature of Linux throttles the transmission frequency of ICMP packets. In this case, even if an application error occurs, CLB may consider the backend server healthy because CLB has not received the error message port XX unreachable. As a result, the health check result is different from the actual application status.
Solution:
You can set CLB to send a specified string to a backend server. The backend server is considered healthy only if it returns a specified response to CLB. However, the application on the backend server must be configured accordingly to return responses.
Health check time window
The health check feature improves the availability of your services. However, frequent failovers caused by unhealthy backend servers may affect system availability. Health check time windows are introduced to control failovers. A failover is performed only when a backend server consecutively passes or fails a certain number of health checks within a time window. The health check time window is determined by the following factors:
Health check interval: the time between two health checks.
Response timeout: the time that a backend server takes to respond.
Health check threshold: the number of consecutive times that a backend server passes or fails health checks.
The health check time window is calculated based on the following formula:
Time window for health check failures = Response timeout × Unhealthy threshold + Health check interval × (Unhealthy threshold - 1)
Time window for health check successes = Response time of a successful health check × Healthy threshold + Health check interval × (Healthy threshold - 1)
NoteThe response time of a successful health check is the duration from the time when the health check request is sent to the time when the response is received. For TCP health checks, the response time is short and almost negligible. For HTTP health checks, the response time depends on the performance and load of the server and is typically within a few seconds.
The health check result has the following impacts on request forwarding:
If a backend server fails health checks, new requests are distributed to other backend servers. CLB remains accessible to clients.
If a backend server passes health checks, new requests are distributed to the backend server. CLB remains accessible to clients.
If a backend server encounters an error and fails a health check, but is not declared unhealthy by health checks, requests are distributed to the backend server. However, the backend server is inaccessible to requests. By default, a backend server is declared unhealthy if it fails health checks for three consecutive times.

Examples of health check response timeout and health check interval
In this example, the following health check settings are used:
Response timeout period: 5 seconds
Health check interval: 2 seconds
Healthy threshold: 3 times
Unhealthy threshold: 3 times
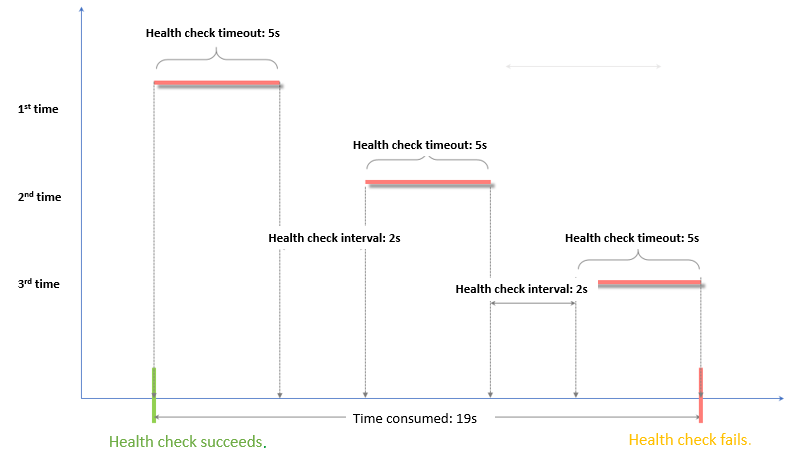
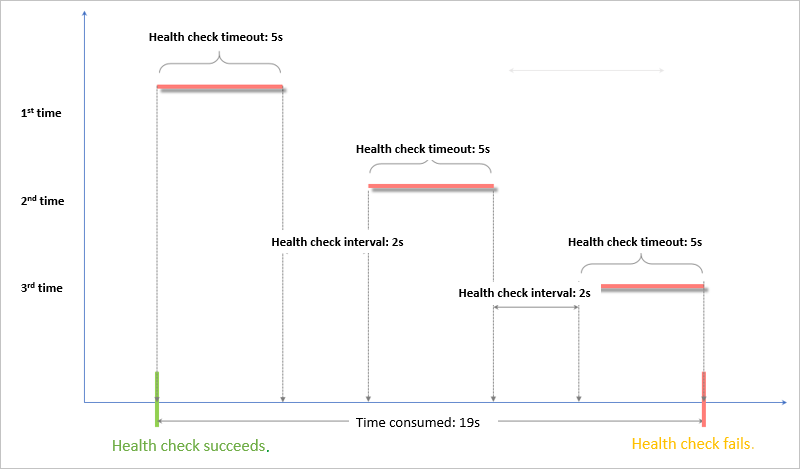
Time window for health check failures = Response timeout × Unhealthy threshold + Health check interval × (Unhealthy threshold - 1). In this example, the time window is 19 seconds based on the formula 5 × 3 + 2 × (3 - 1). If the backend server does not respond for 19 seconds, the backend server is declared unhealthy.
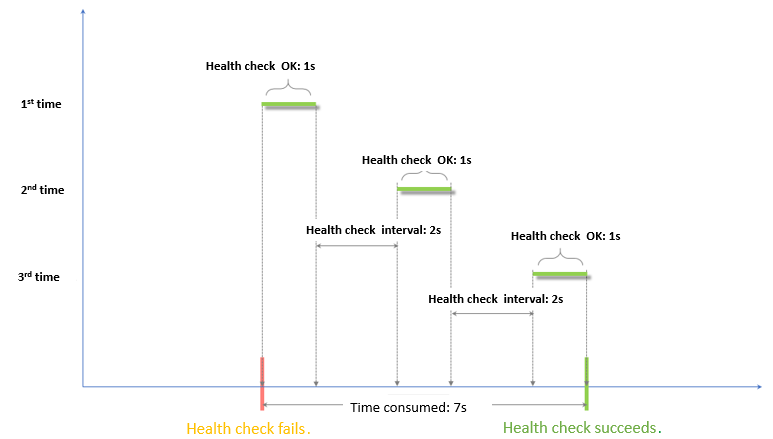
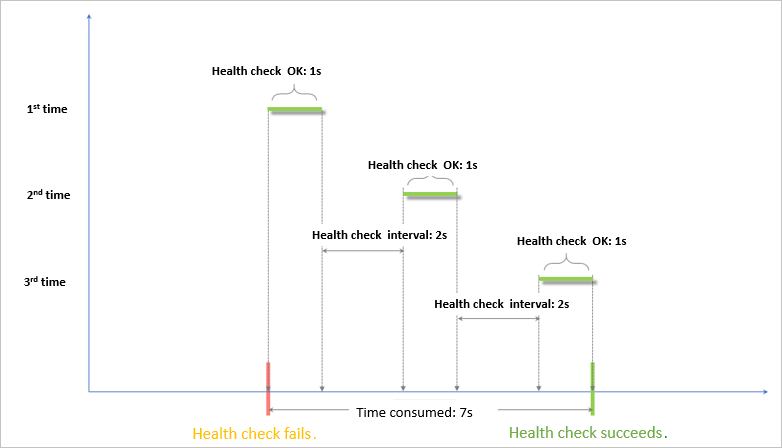
Time window for health check successes = Response time of a successful health check × Healthy threshold + Health check interval × (Healthy threshold - 1). In this example, the time window is 7 seconds based on the formula (1 × 3) + 2 × (3 – 1). If the backend server responds within 7 seconds, the backend server is declared healthy.
The response time of a successful health check is the duration from the time when the health check request is sent to the time when the response is received. When TCP health checks are configured, the response time is short and almost negligible because the only check item is whether the probed port is alive. When HTTP health checks are configured, the response time depends on the performance and load of the application server and is typically within a few seconds.
Domain names for HTTP health checks
You can specify a domain name for HTTP health checks. This setting is optional. Some application servers must verify the Host header in requests before the application servers can accept the requests. In this case, the request must carry the Host header. If a domain name is configured for health checks, CLB inserts the domain name into the Host header. If no domain name is configured, health check requests may be rejected by backend servers, resulting in a mistaken health check result.
Therefore, if your application server verifies the Host header in requests, you must configure a domain name for health checks to ensure that the health check feature works as expected.
References
For more information about how to configure health checks when you create a listener, see Configure and manage CLB health checks.
For more information about the frequently asked questions (FAQ) about health checks, see FAQ about health checks.