PolarDB for MySQL comes in two editions: Cluster Edition and Multi-master Cluster (Limitless).
Choose an edition
| Cluster Edition | Multi-master Cluster (Limitless) | |
|---|---|---|
| Architecture | One primary node + up to 15 read-only nodes | Multiple primary nodes + read-only nodes |
| MySQL versions | 5.6, 5.7, 8.0 | 8.0 only |
| Write scale-out | Single primary node | Scale out across up to 32 compute nodes |
| Failover | Active-active failover between primary and read-only nodes | Failover to another low-traffic primary node within seconds |
| Storage | PolarStore shared storage (expandable to hundreds of terabytes) | PolarStore shared storage |
| Specifications | Dedicated, General-purpose | Dedicated, General-purpose |
| Best for | General-purpose production workloads; finance, Internet, IoT | High-concurrency read/write; multi-tenancy; gaming; e-commerce |
Cluster Edition
Cluster Edition separates compute from storage. A cluster consists of one primary node and up to 15 read-only nodes. The primary node handles read and write requests; read-only nodes handle reads only. All compute nodes share a single copy of data in PolarStore, so storage costs are lower and the cluster can scale to hundreds of terabytes without being limited by individual server capacity.
Architecture
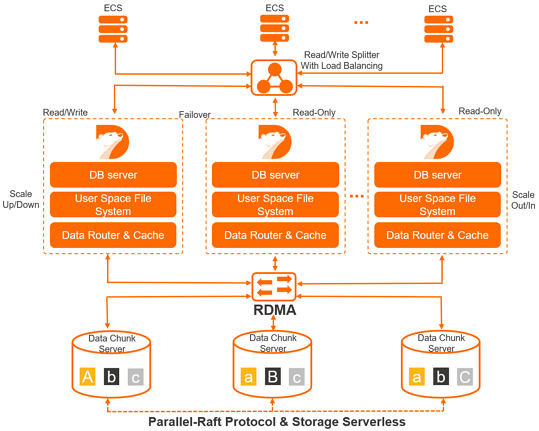
Compute and storage decoupling
Compute nodes store only metadata. Data files and redo logs live in PolarStore. Only redo log metadata is synchronized between nodes, which reduces replication latency between the primary node and read-only nodes. If the primary node fails, a read-only node takes over quickly.
Shared distributed storage
All compute nodes access one shared copy of data in PolarStore rather than maintaining separate copies. PolarStore expands online to hundreds of terabytes without downtime or reconfiguration.
Read/write splitting
PolarProxy routes read and write traffic across nodes automatically. Cluster endpoints distribute SQL requests using transparent, high-availability load balancing, so the cluster handles large volumes of concurrent requests without application-level changes. For details, see Read/write splitting.
High-speed RDMA interconnect
Compute and storage nodes communicate over Remote Direct Memory Access (RDMA) on high-speed networks. Network I/O is not a bottleneck for database performance.
Data reliability and consistency
Storage nodes maintain multiple replicas. The Parallel-Raft protocol keeps replicas consistent, ensuring data reliability and correctness under concurrent writes.
Use cases
Production databases for large and medium-sized enterprises
Applications in Internet, IoT, e-commerce, logistics, and gaming industries
Core databases in finance, securities, and insurance that require high data security
Specifications and pricing
Cluster Edition supports Dedicated and General-purpose specifications. For pricing details, see Billable items.
Multi-master Cluster (Limitless)
Multi-master Cluster (Limitless) runs multiple primary nodes simultaneously. All data files are stored in PolarStore, and each primary node uses PolarFileSystem to access data in PolarStore. All nodes are accessible through the cluster endpoint. PolarProxy routes each SQL statement to the appropriate primary node automatically.
Architecture
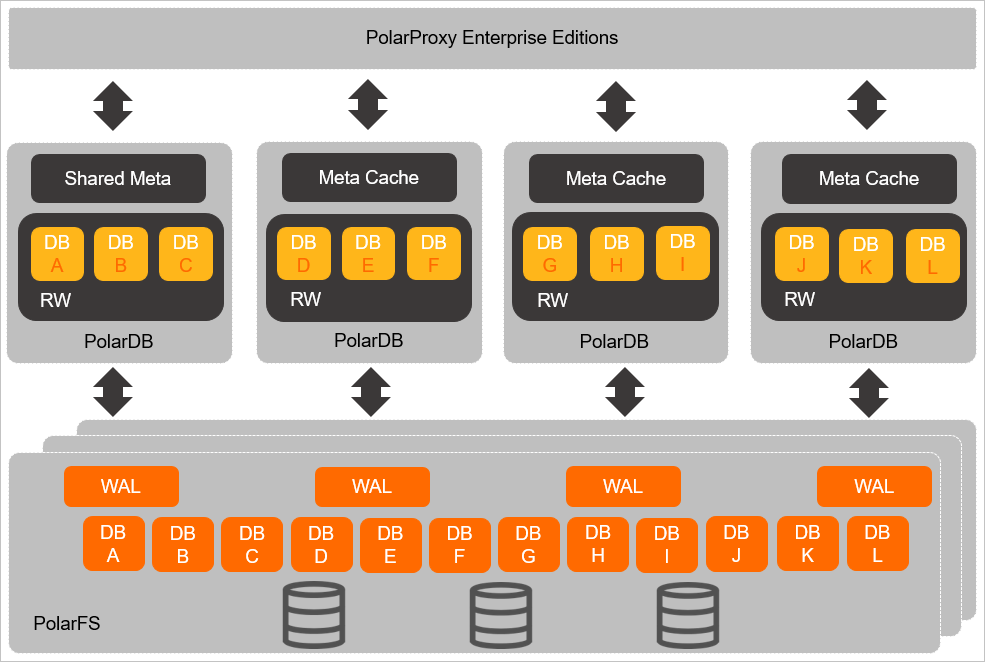
Write scale-out across 32 nodes
Concurrent writes are distributed across up to 32 compute nodes. Databases are scheduled to different nodes within seconds, increasing overall read/write throughput for concurrent workloads.
Failover without secondary nodes
When a primary node fails, traffic shifts to another low-traffic primary node within seconds. Because there are no dedicated secondary nodes reserved only for failover, this can halve the total cost of ownership (TCO).
Global read-only node
A global read-only node can read data written to all primary nodes, which enables queries that span multiple databases within the cluster.
Use cases
Multi-tenancy in SaaS
Balance tenant load by moving their databases to less busy primary nodes or by adding new primary nodes during traffic spikes.
Gaming and e-commerce
Combined with transparent routing and database/table sharding, scale-out that previously took days can be completed in minutes.
Games on different servers
When a game server attracts high player traffic, its database moves to a new primary node to distribute load. When traffic declines, databases consolidate onto fewer primary nodes to cut operating costs.
Specifications and pricing
Multi-master Cluster (Limitless) supports Dedicated and General-purpose specifications. For compute node specifications, see Compute node specifications of PolarDB for MySQL Enterprise Edition. For pricing, see Billable items.