Recommendation systems and search engines are necessary for apps to resolve information overload. Developing a recommendation system from scratch is expensive and time-consuming, and may fail to meet business requirements in time. In addition, a self-developed recommendation system may be unable to iterate with various algorithms. This topic describes how to use Machine Learning Platform for AI (PAI) of Alibaba Cloud to create data and models that are required by a recommendation system.
Architecture
A complete recommendation process involves the recall and sorting modules. The recall module selects a list of to-be-recommended items from a large number of existing items. The sorting module sorts items based on the correlation between each item in the to-be-recommended list and users. The following figure shows a recommendation process without PAI.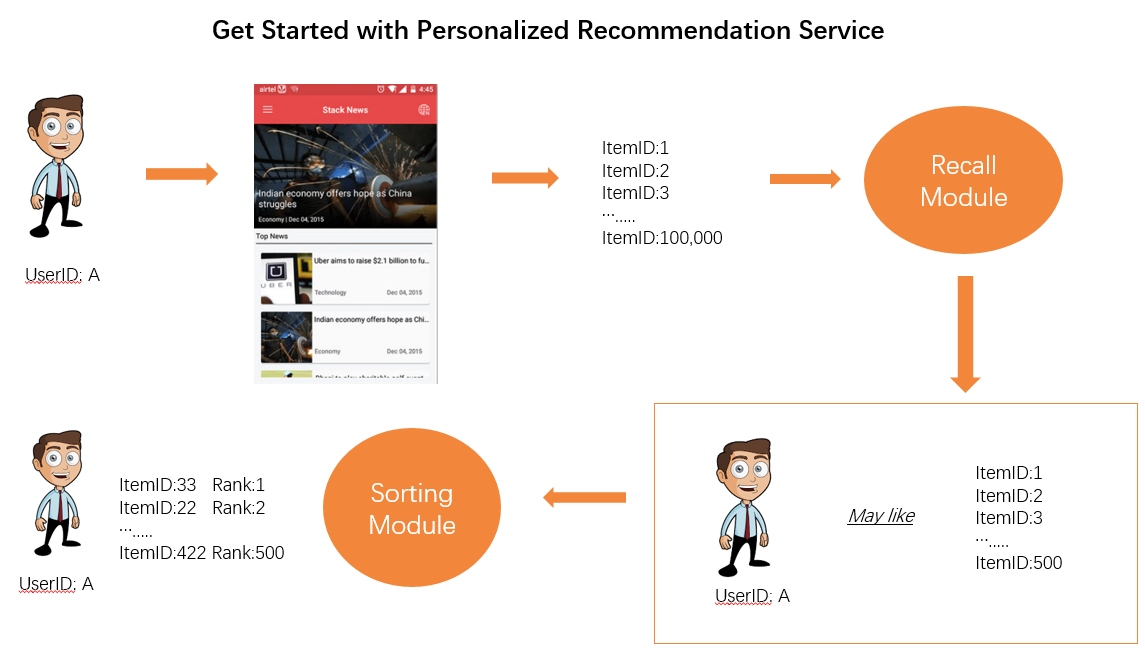
The following figure shows the architecture of a PAI-based recommendation system.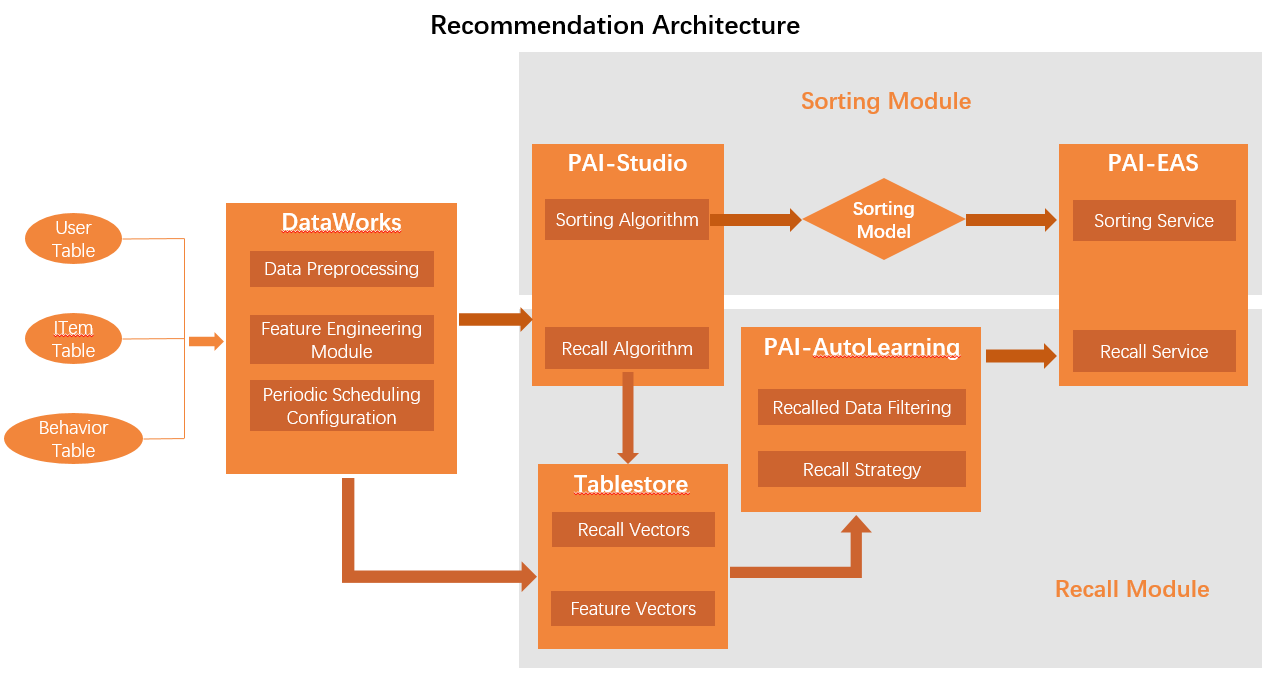 A PAI-based recommendation system works based on the following rules:
A PAI-based recommendation system works based on the following rules:
Stores user, item, and behavior data in MaxCompute.
Uses DataWorks to preprocess data and create basic features.
Writes some feature vectors to Tablestore.
Uses recall and sorting algorithms in Machine Learning Studio to compute data.
Generates sorting models and deploys the models as RESTful APIs in Elastic Algorithm Service (EAS).
Writes recall results to Tablestore, uses AutoLearning to filter the recall results, and then deploys RESTful APIs in EAS based on the filtering results.
The following figure shows a complete PAI-based recommendation process. The recommendation system recommends items to users based on the following process: EAS obtains a recall list by using the recall service. AutoLearning reads feature data from Tablestore based on user IDs and item IDs, filters the feature data, and then sends the filtering result to EAS. EAS sorts the obtained data by using the sorting service and generates a list of to-be-recommended items.
The recommendation system recommends items to users based on the following process: EAS obtains a recall list by using the recall service. AutoLearning reads feature data from Tablestore based on user IDs and item IDs, filters the feature data, and then sends the filtering result to EAS. EAS sorts the obtained data by using the sorting service and generates a list of to-be-recommended items.
References
Use FM-Embedding for matching recall: describes how to use FM-Embedding for matching recall.
Cold start scenarios
To recommend a large number of items, you can use the title and body of an article to train a Doc2Vec model and generate a vector for each item. For more information, see Doc2Vec.
Then, you can use Elasticsearch together with a vector search plug-in to recall the vectors that are similar to each generated vector. We recommend that you classify items and search for similar vectors based on the categories of items. If items are not classified, you can label specific items and use the labeled items as a classification model.
Recommendation based on user behavior
If the data that is required for cold start and user click data are available, you can implement recommendation by using the following method:
Use the click sequences of users to calculate the relationships between items. You can use the word2vec algorithm in natural language processing to treat multiple items that each user clicks as a sentence and cleanse the sequence. For example, you can configure each sequence to contain only the items that belong to the same category or session, or the items that are repeatedly clicked by a user within 30 minutes. For more information, see Word2Vec.
After you obtain sufficient user and item data, you can use the collaborative filtering algorithm named etrec or the matrix factorization algorithm to obtain item-item data. For more information, see Configure the component .
NoteYou can set the weight parameter for the etrec algorithm. For example, you can use the weight parameter to set different weights for the following operations: click, add to favorites, and purchase.
After you obtain the item click logs and exposure logs, you can use the Gradient Boosting Decision Tree (GBDT) model or a tree model such as PS-SMART to sort feature data of users and items. The GBDT model frees you from feature engineering. For more information, see Configure the component or GBDT Regression.
Use one of the following methods to mine features, including features of users and items, feature crosses of users and items, and context features:
Perform feature engineering. For more information, see Feature engineering.
Use the Auto Feature Cross component of PAI to mine feature crosses. For more information, see Use AutoML for automatic feature engineering.
Use the Factorization Machine (FM) algorithm to mine second-order feature crosses. For more information, see Use FM-Embedding for matching recall.
After a model is trained, deploy the model as a RESTful API in EAS. For more information, see Deploy a model service in the PAI console.
Use the TextRank algorithm to extract keywords and mine labels from item data.