This topic describes how to develop a Spark on MaxCompute application by using PySpark.
If you want to access MaxCompute tables in your application, you must compile the odps-spark-datasource package. For more information, see Set up a Linux development environment.
Develop a Spark SQL application in Spark 1.6
Sample code:
from pyspark import SparkContext, SparkConf
from pyspark.sql import OdpsContext
if __name__ == '__main__':
conf = SparkConf().setAppName("odps_pyspark")
sc = SparkContext(conf=conf)
sql_context = OdpsContext(sc)
sql_context.sql("DROP TABLE IF EXISTS spark_sql_test_table")
sql_context.sql("CREATE TABLE spark_sql_test_table(name STRING, num BIGINT)")
sql_context.sql("INSERT INTO TABLE spark_sql_test_table SELECT 'abc', 100000")
sql_context.sql("SELECT * FROM spark_sql_test_table").show()
sql_context.sql("SELECT COUNT(*) FROM spark_sql_test_table").show()Run the following command to commit and run the code:
./bin/spark-submit \
--jars cupid/odps-spark-datasource_xxx.jar \
example.pyDevelop a Spark SQL application in Spark 2.3
Sample code:
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("spark sql").getOrCreate()
spark.sql("DROP TABLE IF EXISTS spark_sql_test_table")
spark.sql("CREATE TABLE spark_sql_test_table(name STRING, num BIGINT)")
spark.sql("INSERT INTO spark_sql_test_table SELECT 'abc', 100000")
spark.sql("SELECT * FROM spark_sql_test_table").show()
spark.sql("SELECT COUNT(*) FROM spark_sql_test_table").show()Commit and run the code.
Run the following command to commit and run the code in cluster mode:
spark-submit --master yarn-cluster \ --jars cupid/odps-spark-datasource_xxx.jar \ example.pyRun the following command to commit and run the code in local mode:
cd $SPARK_HOME ./bin/spark-submit --master local[4] \ --driver-class-path cupid/odps-spark-datasource_xxx.jar \ /path/to/odps-spark-examples/spark-examples/src/main/python/spark_sql.pyNoteIf Spark runs in local mode, MaxCompute Tunnel is required for accessing MaxCompute tables.
If Spark runs in local mode, you must use the --driver-class-path option instead of the --jars option.
Develop a Spark SQL application in Spark 2.4
The following sample code provides an example. You must create a Python project on your on-premises machine and package the Python project.
spark-test.py
# -*- coding: utf-8 -*- import os from pyspark.sql import SparkSession from mc.service.udf.udfs import udf_squared, udf_numpy def noop(x): import socket import sys host = socket.gethostname() + ' '.join(sys.path) + ' '.join(os.environ) print('host: ' + host) print('PYTHONPATH: ' + os.environ['PYTHONPATH']) print('PWD: ' + os.environ['PWD']) print(os.listdir('.')) return host if __name__ == '__main__': # When you perform local debugging, you must add the following code. When you run a MaxCompute job, you must delete the following code. If you do not delete the code, an error is reported. # .master("local[4]") \ spark = SparkSession \ .builder \ .appName("test_pyspark") \ .getOrCreate() sc = spark.sparkContext # Verify the current environment variables of the system. rdd = sc.parallelize(range(10), 2) hosts = rdd.map(noop).distinct().collect() print(hosts) # Verify user-defined functions (UDFs). # https://docs.databricks.com/spark/latest/spark-sql/udf-python.html# spark.udf.register("udf_squared", udf_squared) spark.udf.register("udf_numpy", udf_numpy) tableName = "test_pyspark1" df = spark.sql("""select id, udf_squared(age) age1, udf_squared(age) age2, udf_numpy() udf_numpy from %s """ % tableName) print("rdf count, %s\n" % df.count()) df.show()udfs.py
# -*- coding: utf-8 -*- import numpy as np def udf_squared(s): """ spark udf :param s: :return: """ if s is None: return 0 return s * s def udf_numpy(): rand = np.random.randn() return rand if __name__ == "__main__": print(udf_numpy())
Commit and run the code.
Use the Spark client
Configure settings on the Spark client.
Configure settings on the Spark client.
For more information about how to configure a Linux development environment, see Set up a Linux development environment.
For more information about how to configure a Windows development environment, see Set up a Windows development environment.
Add the following parameters for shared resources to the spark-defaults.conf file in the
conffolder of the Spark client:spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/pythonNoteThe preceding parameters specify the directories of the Python packages. You can choose to use the Python package that is downloaded or the shared resource package.
Commit and run the code.
# mc_pyspark-0.1.0-py3-none-any.zip is a file that contains the common business logic code. spark-submit --py-files mc_pyspark-0.1.0-py3-none-any.zip spark-test.pyNoteIf the downloaded third-party dependency package cannot be imported, the error message
ImportError: cannot import name _distributor_initappears. We recommend that you use the shared resource package. For more information, see PySpark Python versions and supported dependencies.
Use a DataWorks ODPS Spark node
Create a DataWorks ODPS Spark node. For more information, see Develop a MaxCompute Spark task.
Commit and run the code.
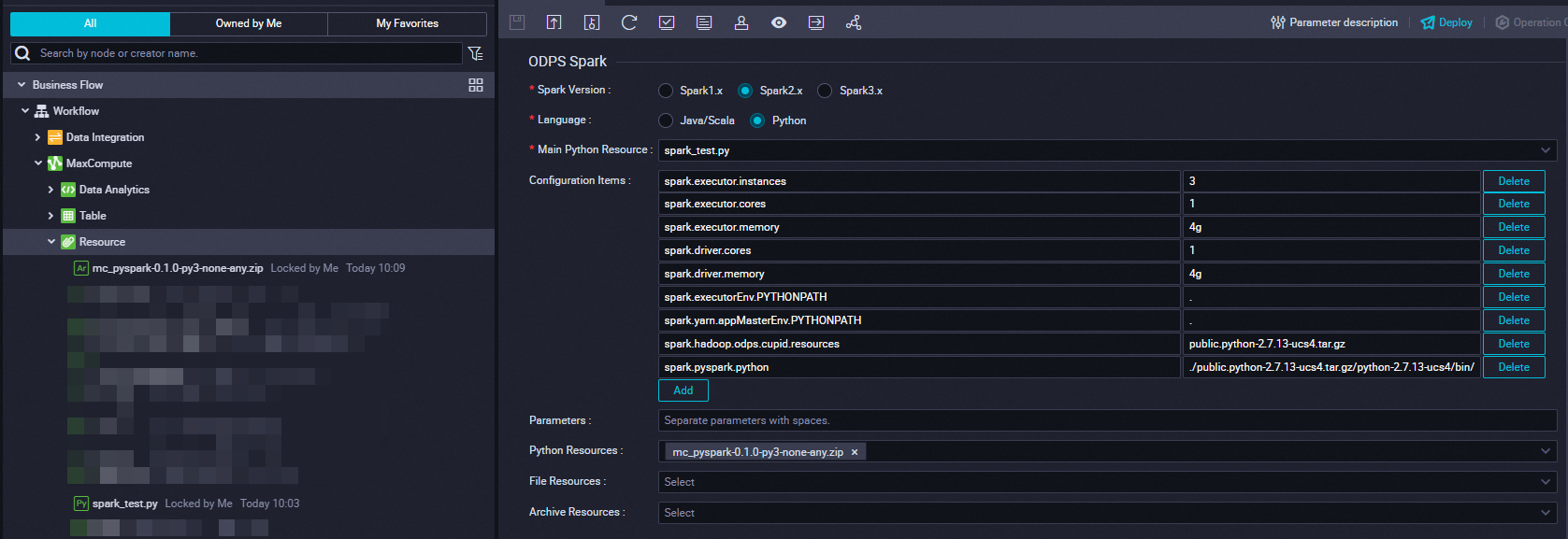
The following table describes the parameters that you need to configure when you create an ODPS Spark node in the DataWorks console.
Parameter
Value
Spark Version
Spark2.x
Language
Python
Main Python Resource
spark_test.py
Configuration Items
-- Configure items for resource application. spark.executor.instances=3 spark.executor.cores=1 spark.executor.memory=4g spark.driver.cores=1 spark.driver.memory=4g -- spark.executorEnv.PYTHONPATH=. spark.yarn.appMasterEnv.PYTHONPATH=. -- Specify the resources to be referenced. spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/pythonPython Resources
mc_pyspark-0.1.0-py3-none-any.zip
Upload the resource.
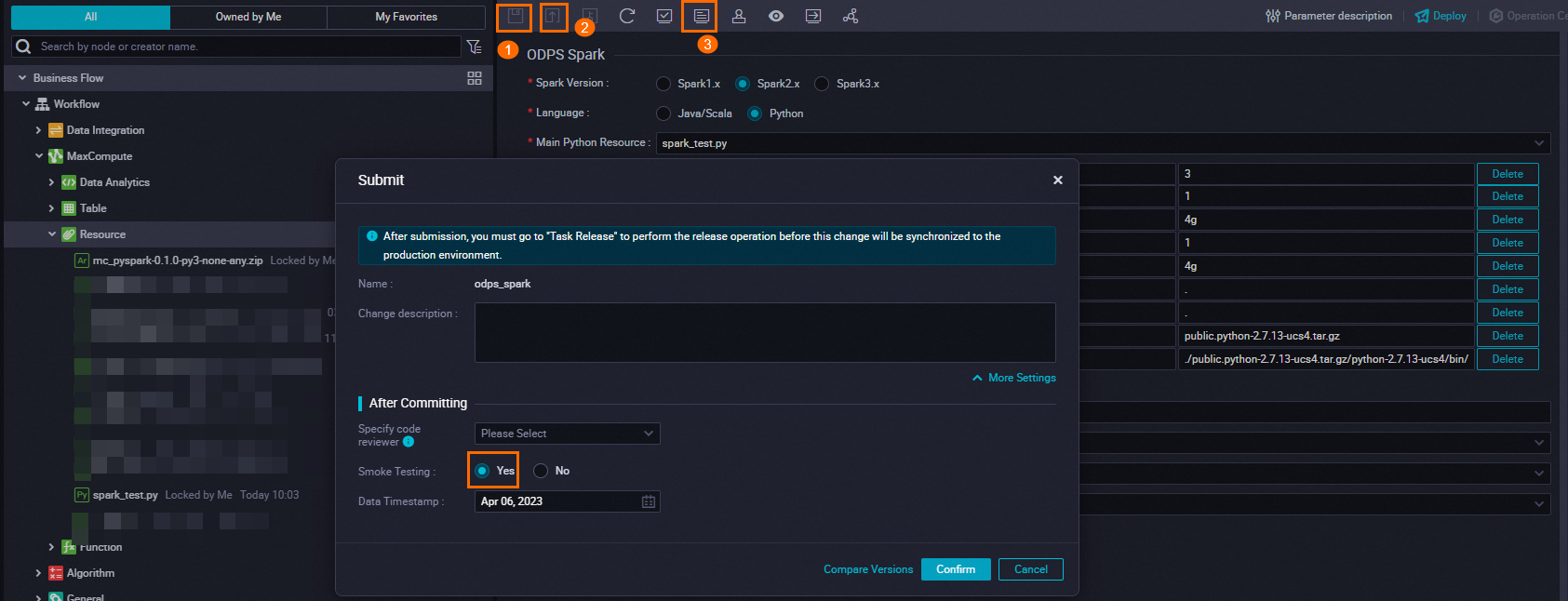
# Change the extension of the business logic code package to .zip. cp /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.whl /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.zip # Run the following command to upload the package to MaxCompute as a resource: # The `-f` directive will overwrite resources in the MaxCompute project that have the same name. Please confirm whether to overwrite or rename. add archive /Users/xxx/PycharmProjects/mc-pyspark/dist/mc_pyspark-0.1.0-py3-none-any.zip -f;Configure and execute a task.
Configuration
Execution
Upload required packages
A MaxCompute cluster does not allow you to install Python libraries. If your Spark on MaxCompute application depends on Python libraries, plug-ins, or projects, you can package the required resources on your on-premises machine and run the spark-submit script to upload the packages to MaxCompute. For some special resources, the Python version on your on-premises machine that you use to package the resources must be the same as the Python version in the MaxCompute cluster in which your application runs. Select one of the following methods to package resources for your application based on the complexity of your business.
Use public resources without packaging
Use public resources for Python 2.7.13.
spark.hadoop.odps.cupid.resources = public.python-2.7.13-ucs4.tar.gz spark.pyspark.python = ./public.python-2.7.13-ucs4.tar.gz/python-2.7.13-ucs4/bin/pythonThe following third-party libraries are available:
$./bin/pip list Package Version ----------------------------- ----------- absl-py 0.11.0 aenum 2.2.4 asn1crypto 0.23.0 astor 0.8.1 astroid 1.6.1 atomicwrites 1.4.0 attrs 20.3.0 backports.functools-lru-cache 1.6.1 backports.lzma 0.0.14 backports.weakref 1.0.post1 beautifulsoup4 4.9.3 bleach 2.1.2 boto 2.49.0 boto3 1.9.147 botocore 1.12.147 bz2file 0.98 cachetools 3.1.1 category-encoders 2.2.2 certifi 2019.9.11 cffi 1.11.2 click 6.7 click-plugins 1.1.1 cligj 0.7.0 cloudpickle 0.5.3 configparser 4.0.2 contextlib2 0.6.0.post1 cryptography 2.6.1 cssutils 1.0.2 cycler 0.10.0 Cython 0.29.5 dask 0.18.1 DBUtils 1.2 decorator 4.2.1 docutils 0.16 entrypoints 0.2.3 enum34 1.1.10 fake-useragent 0.1.11 Fiona 1.8.17 funcsigs 1.0.2 functools32 3.2.3.post2 future 0.16.0 futures 3.3.0 gast 0.2.2 gensim 3.8.3 geopandas 0.6.3 getpass3 1.2 google-auth 1.23.0 google-auth-oauthlib 0.4.1 google-pasta 0.2.0 grpcio 1.33.2 h5py 2.7.0 happybase 1.1.0 html5lib 1.0.1 idna 2.10 imbalanced-learn 0.4.3 imblearn 0.0 importlib-metadata 2.0.0 ipaddress 1.0.23 ipython-genutils 0.2.0 isort 4.3.4 itchat 1.3.10 itsdangerous 0.24 jedi 0.11.1 jieba 0.42.1 Jinja2 2.10 jmespath 0.10.0 jsonschema 2.6.0 kafka-python 1.4.6 kazoo 2.5.0 Keras-Applications 1.0.8 Keras-Preprocessing 1.1.2 kiwisolver 1.1.0 lazy-object-proxy 1.3.1 libarchive-c 2.8 lightgbm 2.3.1 lml 0.0.2 lxml 4.2.1 MarkupSafe 1.0 matplotlib 2.2.5 mccabe 0.6.1 missingno 0.4.2 mistune 0.8.3 mock 2.0.0 more-itertools 5.0.0 munch 2.5.0 nbconvert 5.3.1 nbformat 4.4.0 networkx 2.1 nose 1.3.7 numpy 1.16.1 oauthlib 3.1.0 opt-einsum 2.3.2 packaging 20.4 pandas 0.24.2 pandocfilters 1.4.2 parso 0.1.1 pathlib2 2.3.5 patsy 0.5.1 pbr 3.1.1 pexpect 4.4.0 phpserialize 1.3 pickleshare 0.7.4 Pillow 6.2.0 pip 20.2.4 pluggy 0.13.1 ply 3.11 prompt-toolkit 2.0.1 protobuf 3.6.1 psutil 5.4.3 psycopg2 2.8.6 ptyprocess 0.5.2 py 1.9.0 py4j 0.10.6 pyasn1 0.4.8 pyasn1-modules 0.2.8 pycosat 0.6.3 pycparser 2.18 pydot 1.4.1 Pygments 2.2.0 pykafka 2.8.0 pylint 1.8.2 pymongo 3.11.0 PyMySQL 0.10.1 pynliner 0.8.0 pyodps 0.9.3.1 pyOpenSSL 17.5.0 pyparsing 2.2.0 pypng 0.0.20 pyproj 2.2.2 PyQRCode 1.2.1 pytest 4.6.11 python-dateutil 2.8.1 pytz 2020.4 PyWavelets 0.5.2 PyYAML 3.12 redis 3.2.1 requests 2.25.0 requests-oauthlib 1.3.0 rope 0.10.7 rsa 4.5 ruamel.ordereddict 0.4.15 ruamel.yaml 0.11.14 s3transfer 0.2.0 scandir 1.10.0 scikit-image 0.14.0 scikit-learn 0.20.3 scipy 1.2.3 seaborn 0.9.1 Send2Trash 1.5.0 setuptools 41.0.0 Shapely 1.7.1 simplegeneric 0.8.1 singledispatch 3.4.0.3 six 1.15.0 sklearn2 0.0.13 smart-open 1.8.1 soupsieve 1.9.6 SQLAlchemy 1.3.20 statsmodels 0.11.0 subprocess32 3.5.4 tabulate 0.8.7 tensorflow 2.0.0 tensorflow-estimator 2.0.1 termcolor 1.1.0 testpath 0.3.1 thriftpy 0.3.9 timeout-decorator 0.4.1 toolz 0.9.0 tqdm 4.32.2 traitlets 4.3.2 urllib3 1.24.3 wcwidth 0.2.5 webencodings 0.5.1 Werkzeug 1.0.1 wheel 0.35.1 wrapt 1.11.1 xgboost 0.82 xlrd 1.2.0 XlsxWriter 1.0.7 zipp 1.2.0Use public resources for Python 3.7.9.
spark.hadoop.odps.cupid.resources = public.python-3.7.9-ucs4.tar.gz spark.pyspark.python = ./public.python-3.7.9-ucs4.tar.gz/python-3.7.9-ucs4/bin/python3The following third-party libraries are available:
Package Version ----------------------------- ----------- appnope 0.1.0 asn1crypto 0.23.0 astroid 1.6.1 attrs 20.3.0 autopep8 1.3.4 backcall 0.2.0 backports.functools-lru-cache 1.5 backports.weakref 1.0rc1 beautifulsoup4 4.6.0 bidict 0.17.3 bleach 2.1.2 boto 2.49.0 boto3 1.9.147 botocore 1.12.147 bs4 0.0.1 bz2file 0.98 cached-property 1.5.2 cachetools 3.1.1 category-encoders 2.2.2 certifi 2019.11.28 cffi 1.11.2 click 6.7 click-plugins 1.1.1 cligj 0.7.0 cloudpickle 0.5.3 cryptography 2.6.1 cssutils 1.0.2 cycler 0.10.0 Cython 0.29.21 dask 0.18.1 DBUtils 1.2 decorator 4.2.1 docutils 0.16 entrypoints 0.2.3 fake-useragent 0.1.11 Fiona 1.8.17 future 0.16.0 gensim 3.8.3 geopandas 0.8.0 getpass3 1.2 h5py 3.1.0 happybase 1.1.0 html5lib 1.0.1 idna 2.10 imbalanced-learn 0.4.3 imblearn 0.0 importlib-metadata 2.0.0 iniconfig 1.1.1 ipykernel 5.3.4 ipython 7.19.0 ipython-genutils 0.2.0 isort 4.3.4 itchat 1.3.10 itsdangerous 0.24 jedi 0.11.1 jieba 0.42.1 Jinja2 2.10 jmespath 0.10.0 jsonschema 2.6.0 jupyter-client 6.1.7 jupyter-core 4.6.3 kafka-python 1.4.6 kazoo 2.5.0 kiwisolver 1.3.1 lazy-object-proxy 1.3.1 libarchive-c 2.8 lightgbm 2.3.1 lml 0.0.2 lxml 4.2.1 Mako 1.0.10 MarkupSafe 1.0 matplotlib 3.3.3 mccabe 0.6.1 missingno 0.4.2 mistune 0.8.3 mock 2.0.0 munch 2.5.0 nbconvert 5.3.1 nbformat 4.4.0 networkx 2.1 nose 1.3.7 numpy 1.19.4 packaging 20.4 pandas 1.1.4 pandocfilters 1.4.2 parso 0.1.1 patsy 0.5.1 pbr 3.1.1 pexpect 4.4.0 phpserialize 1.3 pickleshare 0.7.4 Pillow 6.2.0 pip 20.2.4 plotly 4.12.0 pluggy 0.13.1 ply 3.11 prompt-toolkit 2.0.1 protobuf 3.6.1 psutil 5.4.3 psycopg2 2.8.6 ptyprocess 0.5.2 py 1.9.0 py4j 0.10.6 pycodestyle 2.3.1 pycosat 0.6.3 pycparser 2.18 pydot 1.4.1 Pygments 2.2.0 pykafka 2.8.0 pylint 1.8.2 pymongo 3.11.0 PyMySQL 0.10.1 pynliner 0.8.0 pyodps 0.9.3.1 pyOpenSSL 17.5.0 pyparsing 2.2.0 pypng 0.0.20 pyproj 3.0.0.post1 PyQRCode 1.2.1 pytest 6.1.2 python-dateutil 2.8.1 pytz 2020.4 PyWavelets 0.5.2 PyYAML 3.12 pyzmq 17.0.0 qtconsole 4.3.1 redis 3.2.1 requests 2.25.0 retrying 1.3.3 rope 0.10.7 ruamel.yaml 0.16.12 ruamel.yaml.clib 0.2.2 s3transfer 0.2.0 scikit-image 0.14.0 scikit-learn 0.20.3 scipy 1.5.4 seaborn 0.11.0 Send2Trash 1.5.0 setuptools 41.0.0 Shapely 1.7.1 simplegeneric 0.8.1 six 1.15.0 sklearn2 0.0.13 smart-open 1.8.1 SQLAlchemy 1.3.20 statsmodels 0.12.1 tabulate 0.8.7 testpath 0.3.1 thriftpy 0.3.9 timeout-decorator 0.4.1 toml 0.10.2 toolz 0.9.0 tornado 6.1 tqdm 4.32.2 traitlets 4.3.2 urllib3 1.24.3 wcwidth 0.2.5 webencodings 0.5.1 wheel 0.35.1 wrapt 1.11.1 xgboost 1.2.1 xlrd 1.2.0 XlsxWriter 1.0.7 zipp 3.4.0
Upload a single wheel package
If a few Python dependencies are required, you can upload only one wheel package. In most cases, a manylinux wheel package is uploaded. To upload a single wheel package, perform the following steps:
Package the wheel package into a ZIP package. For example, package the pymysql.whl package into the pymysql.zip package.
Upload the ZIP package and store the package with the storage class of Archive.
Select the ZIP package on the configuration tab of the Spark node in the DataWorks console.
Change environment variables in the code to import the ZIP package.
sys.path.append('pymysql') import pymysql
Use a requirements.txt file
If a large number of additional dependencies are required, you must repeat the procedure for uploading a wheel package several times. In this case, you can download the script and create a requirements.txt file that lists the required dependencies and use the script and the requirements.txt file to generate a Python environment package. Then, you can develop a Spark on MaxCompute application by using PySpark.
Usage
$ chmod +x generate_env_pyspark.sh $ generate_env_pyspark.sh -h Usage: generate_env_pyspark.sh [-p] [-r] [-t] [-c] [-h] Description: -p ARG, the version of python, currently supports python 2.7, 3.5, 3.6 and 3.7 versions. -r ARG, the local path of your python requirements. -t ARG, the output directory of the gz compressed package. -c, clean mode, we will only package python according to your requirements, without other pre-provided dependencies. -h, display help of this script.Example
# Generate a Python environment package with preinstalled dependencies. $ generate_env_pyspark.sh -p 3.7 -r your_path_to_requirements -t your_output_directory # Generate a Python environment package in clean mode. This way, the package that you generate does not contain preinstalled dependencies. generate_env_pyspark.sh -p 3.7 -r your_path_to_requirements -t your_output_directory -cNotes
The script can run on a macOS or Linux operating system. To use the script, you must install Docker in advance. For more information about how to install Docker, see the Docker documentation.
The following Python versions are supported: Python 2.7, Python 3.5, Python 3.6, and Python 3.7. If you do not have special requirements for the Python version, we recommend that you use Python 3.7.
The
-coption specifies whether to enable the clean mode. In clean mode, preinstalled dependencies cannot be packaged. Therefore, the Python package is small in size. For more information about the dependencies of each Python version, see Preinstalled dependencies of Python 2.7, Preinstalled dependencies of Python 3.5, Preinstalled dependencies of Python 3.6, and Preinstalled dependencies of Python 3.7.MaxCompute allows you to upload a resource package with a maximum size of 500 MB. If most preinstalled dependencies are not used, we recommend that you configure the
-coption to package resources in clean mode.
Use packages in Spark
You can use the generate_env_pyspark.sh script to generate a .tar.gz package of a specified Python version in a specified path. The
-toption specifies the path, and the-poption specifies the Python version. For example, if Python 3.7 is used, the py37.tar.gz package is generated. You can upload the package as a resource with the storage class of Archive in MaxCompute. You can upload the package by using the MaxCompute client or a MaxCompute SDK. For more information about resource operations, see Resource operations. To use the MaxCompute client to upload the py37.tar.gz package, perform the following steps:Run the following command on the MaxCompute client to add the package as a resource:
# The `-f` directive will overwrite resources in the MaxCompute project that have the same name. Please confirm whether to overwrite or rename. add archive /your/path/to/py37.tar.gz -f;Add the following parameter settings to the configurations of your Spark job:
spark.hadoop.odps.cupid.resources = your_project.py37.tar.gz spark.pyspark.python = your_project.py37.tar.gz/bin/pythonIf the preceding parameter settings do not take effect, you must add the following configurations to the configurations of your Spark job. For example, if you use Apache Zeppelin to debug PySpark, you must add the following Python environment configurations to an Apache Zeppelin notebook.
spark.yarn.appMasterEnv.PYTHONPATH = ./your_project.py37.tar.gz/bin/python spark.executorEnv.PYTHONPATH = ./your_project.py37.tar.gz/bin/python
Use a Docker container
This method is suitable for the following scenarios:
If you want to package a .so file, you cannot use the method described in "Upload a single wheel package" or run
pip install.The Python version that you use is not Python 2.7, Python 3.5, Python 3.6, or Python 3.7.
In the preceding scenarios, you must make sure that the Python environment that you package is the same as the Python environment in which your Spark job is running. For example, the Python environment that you package in a macOS operating system may not be compatible with the Python environment in which your Spark job is running. To package the Python 3.7 environment by using a Docker container, perform the following steps:
Create a Dockerfile on your Docker host.
Sample code in Python 3:
FROM centos:7.6.1810 RUN set -ex \ # Pre-install the required components. && yum install -y wget tar libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make initscripts zip\ && wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tgz \ && tar -zxvf Python-3.7.0.tgz \ && cd Python-3.7.0 \ && ./configure prefix=/usr/local/python3 \ && make \ && make install \ && make clean \ && rm -rf /Python-3.7.0* \ && yum install -y epel-release \ && yum install -y python-pip # Set the default Python version to Python 3. RUN set -ex \ # Back up resources of Python 2.7. && mv /usr/bin/python /usr/bin/python27 \ && mv /usr/bin/pip /usr/bin/pip-python27 \ # Set the default Python version to Python 3. && ln -s /usr/local/python3/bin/python3.7 /usr/bin/python \ && ln -s /usr/local/python3/bin/pip3 /usr/bin/pip # Fix the YUM bug that is caused by the change in the Python version. RUN set -ex \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/bin/yum \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/libexec/urlgrabber-ext-down \ && yum install -y deltarpm # Update the pip version. RUN pip install --upgrade pipSample code in Python 2:
FROM centos:7.6.1810 RUN set -ex \ # Pre-install the required components. && yum install -y wget tar libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make initscripts zip\ && wget https://www.python.org/ftp/python/2.7.18/Python-2.7.18.tgz \ && tar -zxvf Python-2.7.18.tgz \ && cd Python-2.7.18 \ && ./configure prefix=/usr/local/python2 \ && make \ && make install \ && make clean \ && rm -rf /Python-2.7.18* # Set the default Python version. RUN set -ex \ && mv /usr/bin/python /usr/bin/python27 \ && ln -s /usr/local/python2/bin/python /usr/bin/python RUN set -ex \ && wget https://bootstrap.pypa.io/get-pip.py \ && python get-pip.py RUN set -ex \ && rm -rf /usr/bin/pip \ && ln -s /usr/local/python2/bin/pip /usr/bin/pip # Fix the YUM bug that is caused by the change in the Python version. RUN set -ex \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/bin/yum \ && sed -i "s#/usr/bin/python#/usr/bin/python27#" /usr/libexec/urlgrabber-ext-down \ && yum install -y deltarpm # Update the pip version. RUN pip install --upgrade pip
Build an image and run the Docker container.
# Run the following commands in the path in which the Dockerfile is stored: docker build -t python-centos:3.7 docker run -itd --name python3.7 python-centos:3.7Install required Python libraries in the container.
docker attach python3.7 pip install [Required library]Compress all Python libraries into a package.
cd /usr/local/ zip -r python3.7.zip python3/Copy the Python environment package from the container to your host.
# Exit the container. ctrl+P+Q # Run the following command on the host: docker cp python3.7:/usr/local/python3.7.zipUpload the Python3.7.zip package as a MaxCompute resource. You can use DataWorks to upload a package with a maximum size of 50 MB. If the size of a package exceeds 50 MB, you can use the MaxCompute client to upload the package and store the package with the storage class of Archive. For more information about how to upload resources, see Add resources.
# The `-f` directive will overwrite resources in the MaxCompute project that have the same name. Please confirm whether to overwrite or rename. add archive /path/to/python3.7.zip -f;When you submit a job, you need to only add the following configurations to the spark-defaults.conf file or DataWorks configurations:
spark.hadoop.odps.cupid.resources=[Project name].python3.7.zip spark.pyspark.python=./[Project name].python3.7.zip/python3/bin/python3.7NoteWhen you package resources in a Docker container, you must manually place the .so package in the Python environment if the .so package is not found. In most cases, the .so package can be found in the container. After you find this package, add the following environment variables to the configurations of your Spark job:
spark.executorEnv.LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./[Project name].python3.7.zip/python3/[Directory of the .so package] spark.yarn.appMasterEnv.LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./[Project name].python3.7.zip/python3/[Directory of the .so package]
Reference a custom Python package
In most cases, you will need to use custom Python files. To prevent the workload caused by sequentially uploading multiple '.py' files, you can package these files by following these steps:
Create an empty file named __init__.py and package code into a ZIP package.
Upload the ZIP package as a MaxCompute resource and rename the package. This package is decompressed into the working directory.
NoteFor more information about the types of resources that you can upload to MaxCompute, see Resource.
Configure the parameter
spark.executorEnv.PYTHONPATH=.Import the main Python file to the path that is specified by spark.executorEnv.PYTHONPATH=.