Branch nodes are a type of logical control node in DataStudio. This topic describes how to run tasks at a specific point in time by using branch nodes.
Background information for supporting branch nodes
You cannot schedule a node to run on the last day of each month by using a cron expression. After branch nodes are supported, you can create a branch node and use the switch-case model to schedule a node to run on the last day of each month. For more information, see Configure a branch node.
Branch nodes and other control nodes
On the DataStudio page, you can view the control nodes that are supported by DataWorks of the current edition, including assignment nodes, branch nodes, and merge nodes.
Features of each control node:
Assignment node: You can pass the output of an assignment node to its descendant nodes. For more information, see Configure an assignment node.
An assignment node reuses the node context feature for configuring dependencies. In addition to constants and variables, an assignment node supports custom output in the node context. DataWorks captures or displays the query result of an assignment node and uses the result as the value of the outputs parameter in the node context for descendant nodes to reference.
Branch node: A branch node determines which descendant nodes can be run as expected. For more information, see Configure a branch node.
A branch node reuses the feature of DataWorks for configuring input and output in dependencies. For more information, see Configure same-cycle scheduling dependencies.
For common nodes, the output is only a globally unique string. To configure a node as a descendant node of a common node, you can specify the globally unique string of the common node as the input of the descendant node.
However, for a branch node, you can select the output that is associated with a condition as the output of the branch node when you configure descendant nodes for the branch node. When nodes become descendant nodes of the branch node, the nodes are also associated with the condition:
If the condition is met, the descendant nodes that depend on the output associated with the condition can be run as expected.
Other descendant nodes that do not depend on the output associated with the condition are dry run.
Merge node: A merge node is scheduled to run no matter whether its ancestor nodes are run.
On a branch that is not selected by a branch node, DataWorks sets instances of all nodes on the branch as dry-run instances. An instance is dry run when one of its ancestor instances is a dry-run instance.
DataWorks allows you to use a merge node to prevent the dry-run property from being passed downstream without any limits. A merge node is set as successful no matter how many ancestor nodes are dry run, and the descendant nodes of the merge node are not dry run.
The following figure shows the logical relationships in a dependency tree that contains branch nodes.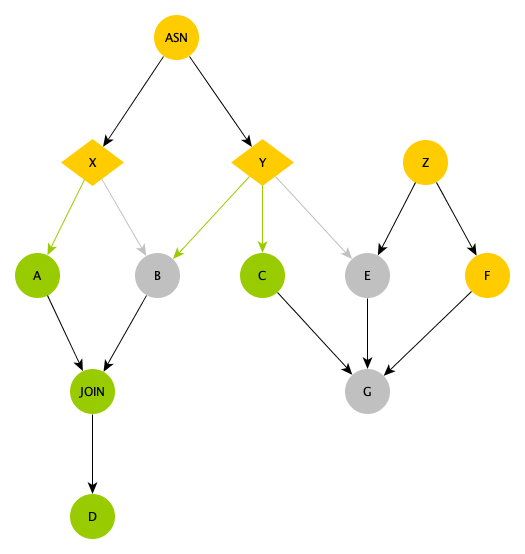
ASN: an assignment node, which is used for computing in complex scenarios and allows you to select conditions for branch nodes.
X and Y: the branch nodes, which are the descendant nodes of the assignment node ASN and select branches based on the output of the assignment node. Node X selects the left branch, and Node Y selects the left two branches, as marked by the green lines in the following figure.
Nodes A and C can be run as expected because they are selected by Nodes X and Y.
Node B is selected by Node Y. However, Node B is dry run because it is not selected by Node X.
Node E is not selected by Node Y. Therefore, Node E is also dry run even though it has a common node Z as an ancestor node.
Node G is also dry run because its ancestor node E is dry run even if Nodes C and F are run.
When will the dry-run property not be passed downstream?
The JOIN node is a merge node. Its special feature is to prevent the dry-run property from being passed. Node D is a descendant node of the JOIN node. Therefore, Node D does not inherit the dry-run property from Node B and can be run.
You can use branch nodes together with other control nodes to schedule a node to run only on the last day of each month.
Use a branch node
Define node dependencies.
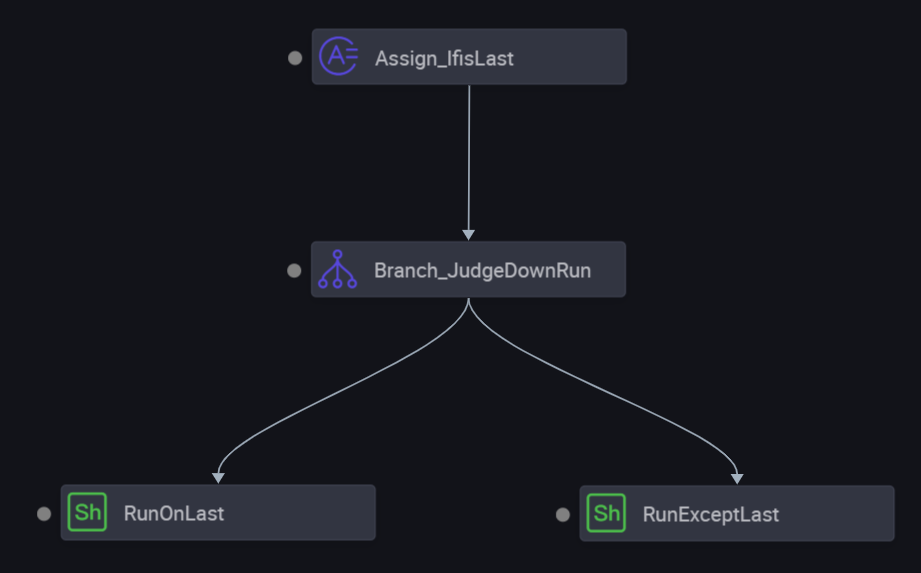
The root node, which is an assignment node, determines whether the current day is the last day of the month based on the SKYNET_CYCTIME parameter, which specifies the scheduling time. If the current day is the last day, 1 is returned. Otherwise, 0 is returned. The output is captured by DataWorks and passed to the descendant node.
The branch node defines branches based on the output of the assignment node.
Two Shell nodes are configured as the descendant nodes of the branch node to run different branch logic.
Define the assignment node.
A created assignment node has a built-in outputs parameter. An assignment node can be written in the SQL, SHELL, or Python language.
For an assignment node that is written in the SQL language, DataWorks captures the last SELECT statement as the value of the outputs parameter.
For an assignment node that is written in the SHELL or Python language, DataWorks captures the standard output in the last line as the value of the outputs parameter.
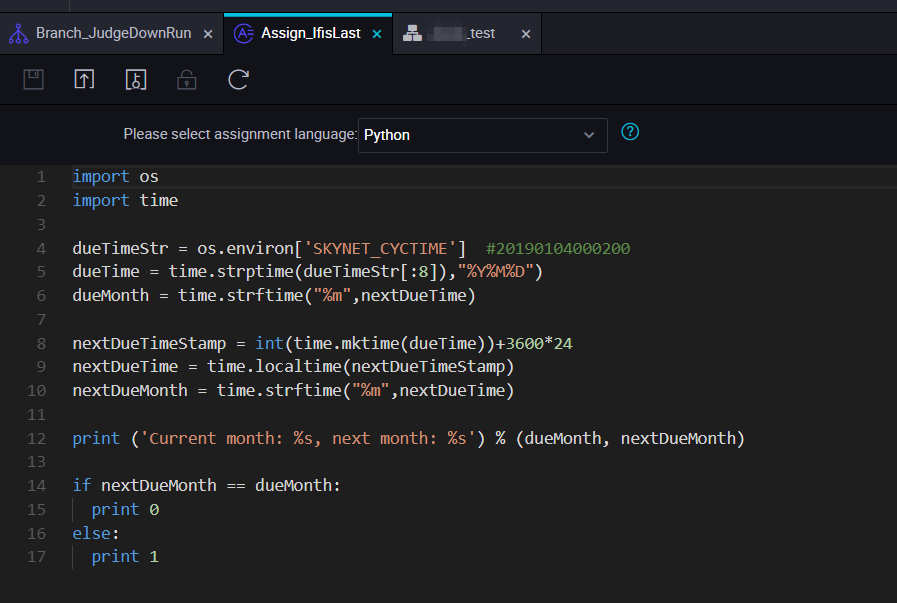
In this topic, the code of the assignment node is written in Python. The following figures show the scheduling properties and code of the assignment node.
Code
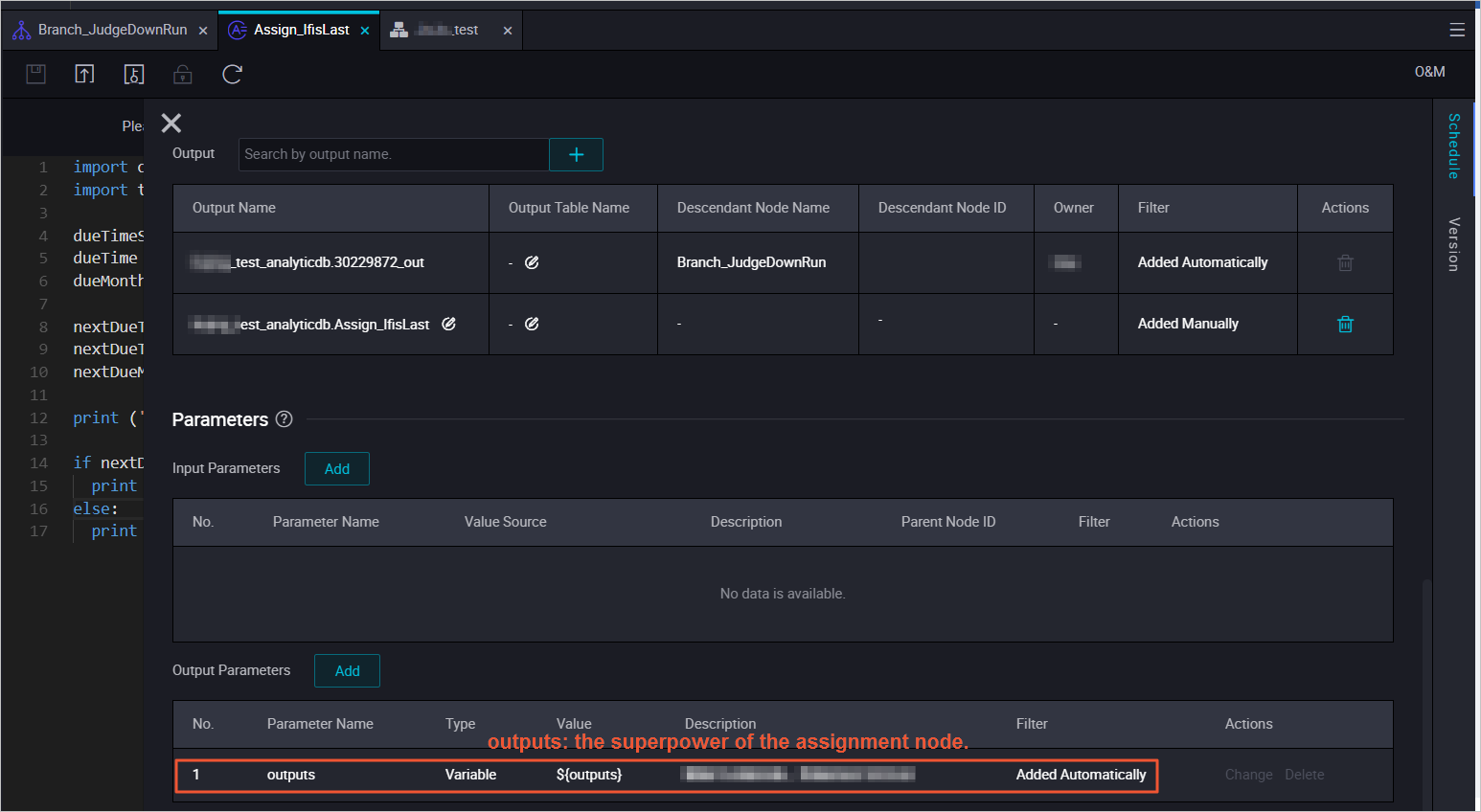
Configuration of scheduling properties
Define branches.
You can define conditions for branch nodes by using Python expressions. Each condition is associated with an output. If a condition is met, the descendant node that depends on the output associated with the condition is run, and other descendant nodes are dry run.
Configuration of scheduling properties
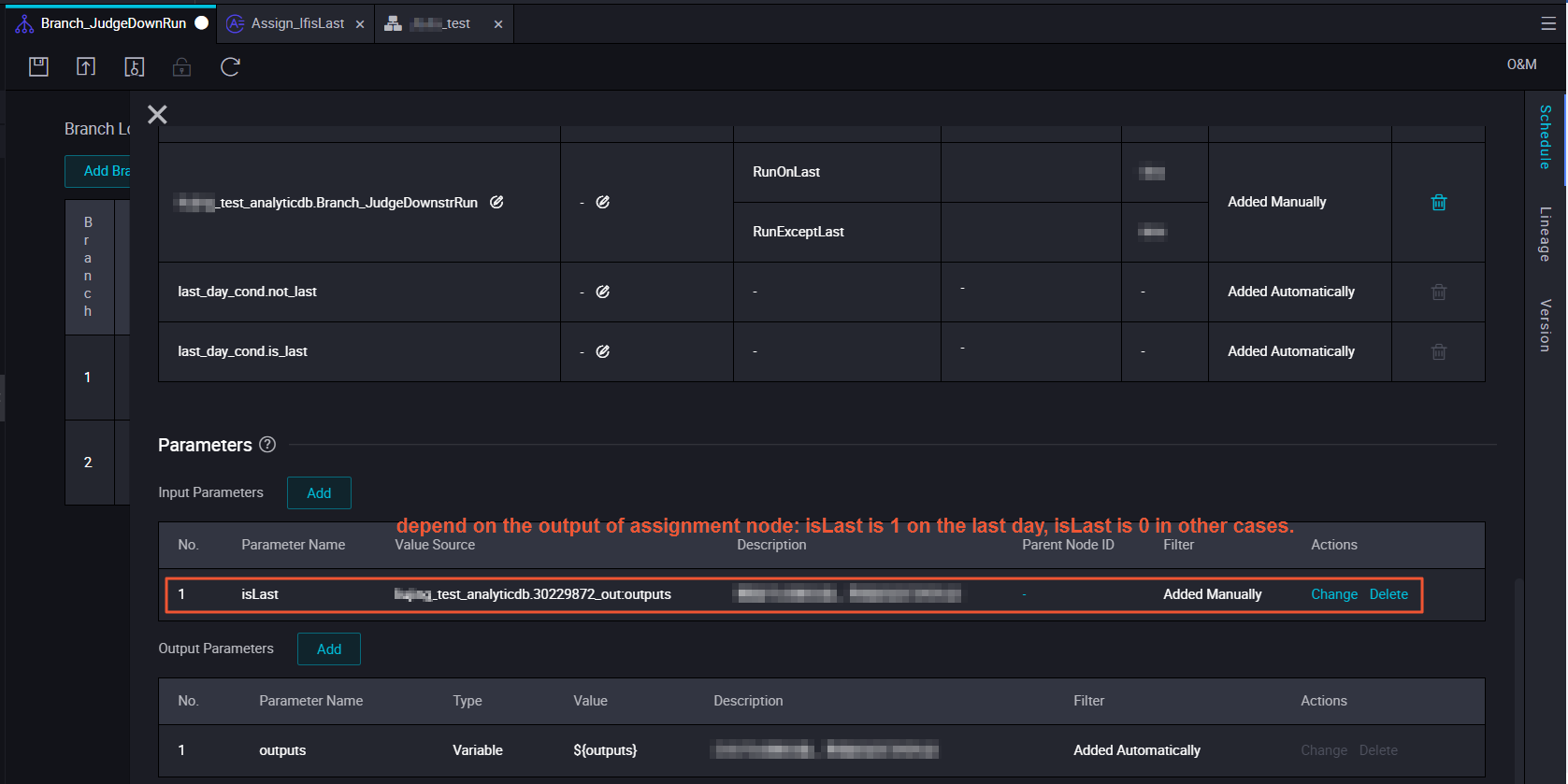
Configuration of branches
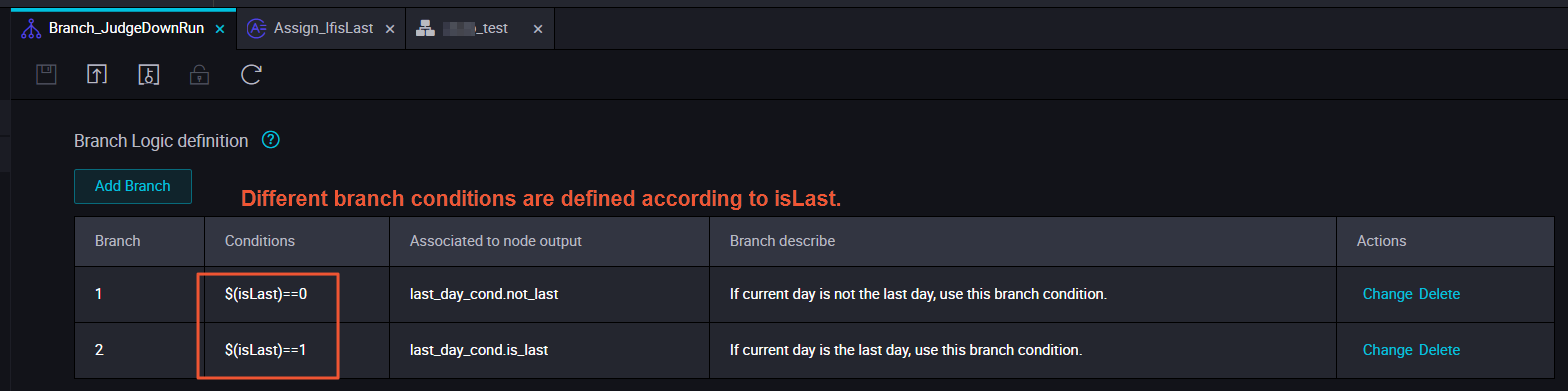
Outputs that are associated with the conditions and generated in the scheduling configuration
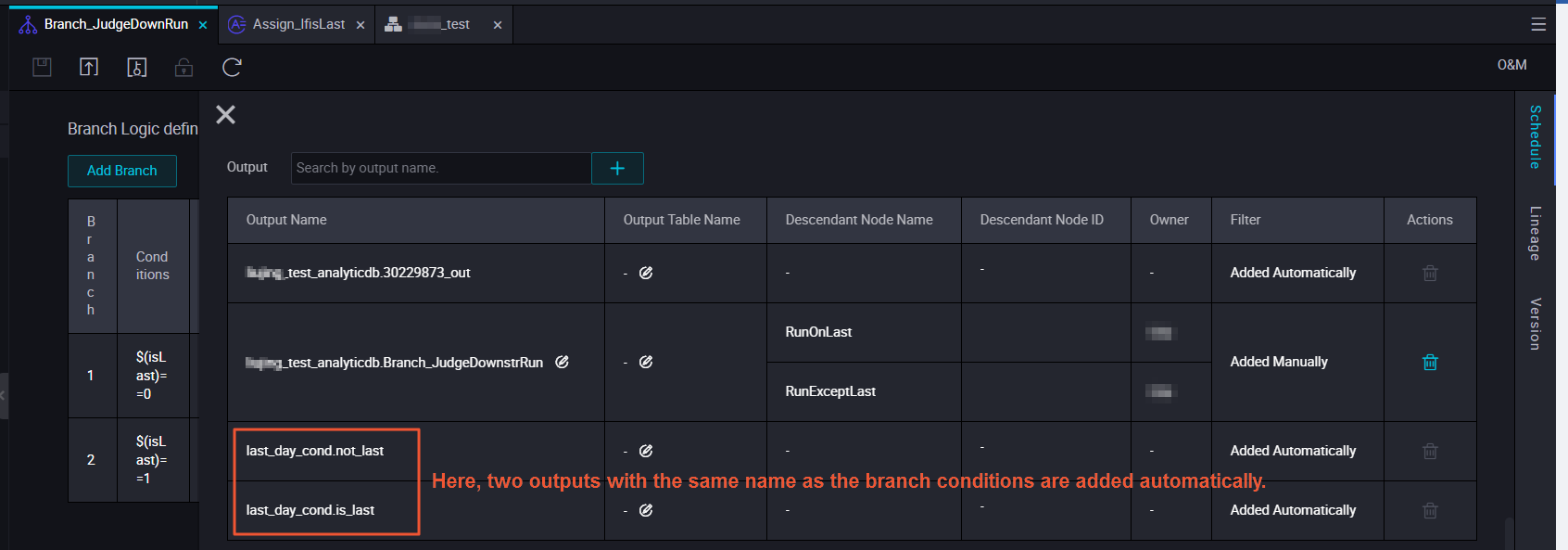
Associate task execution nodes with different branches.
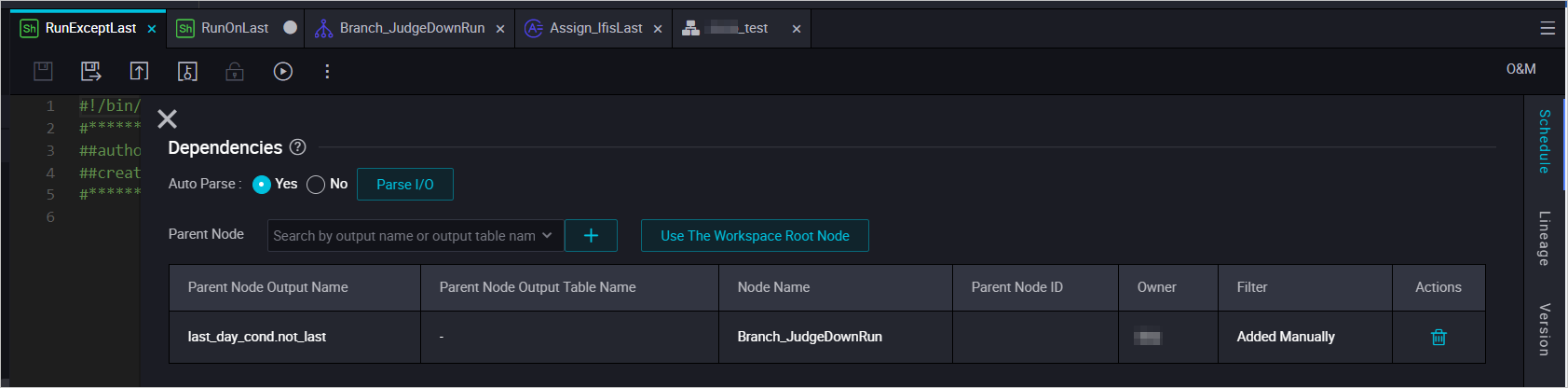
The branch node has three outputs. You can select one output as the input. Select output with caution because the outputs are associated with conditions.
Dependency for the node that is to be run on the last day of each month
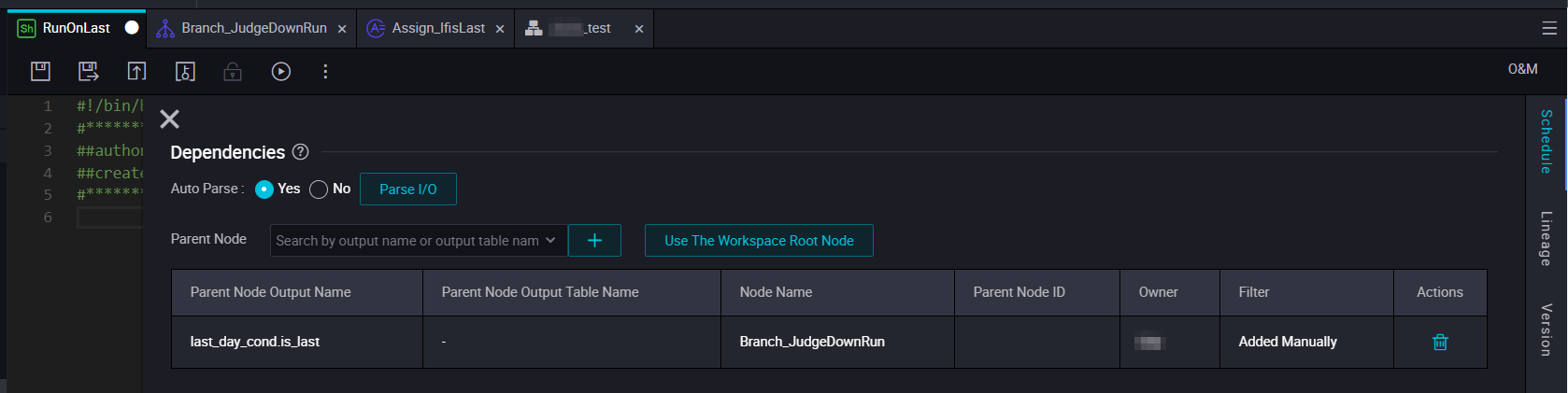
Dependency for the node that is to be run on other days of each month
Verify the result.
After you perform the preceding steps, you can commit and deploy the nodes. After you deploy the nodes, you can backfill data for the nodes to test the configuration effect. Set the data timestamps to December 30, 2018 and December 31, 2018. This means that the scheduling time is December 31, 2018 and January 1, 2019. The first batch of data backfill instances triggers the logic for the last day. The second batch of data backfill instances triggers the logic for days except the last day. The two logic has the following differences:
The data timestamp is December 30, 2018, which indicates that the scheduling time is December 31, 2018.
Branch selection result of the branch node
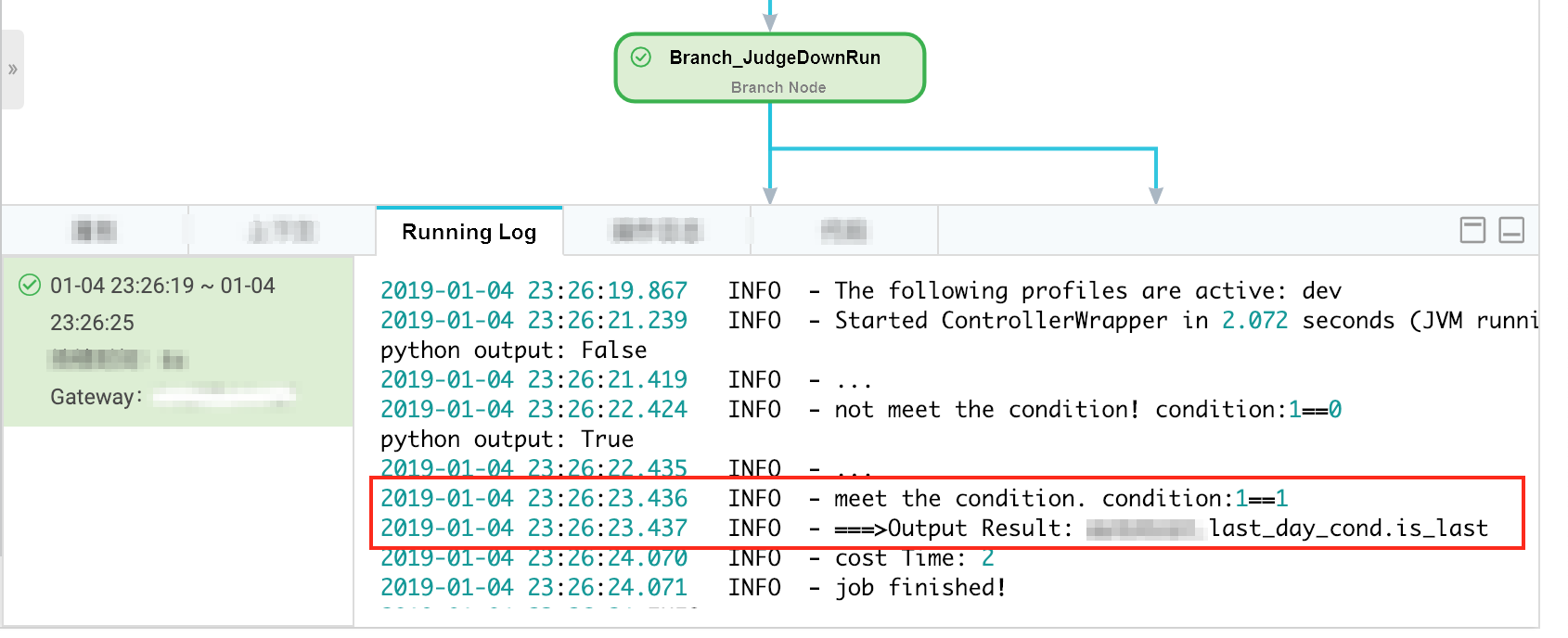
The node that is to be run on the last day is run as expected.
The node that is to be run on days except the last day is dry run.
The data timestamp is December 31, 2018, which indicates that the scheduling time is January 1, 2019.
Branch selection result of the branch node
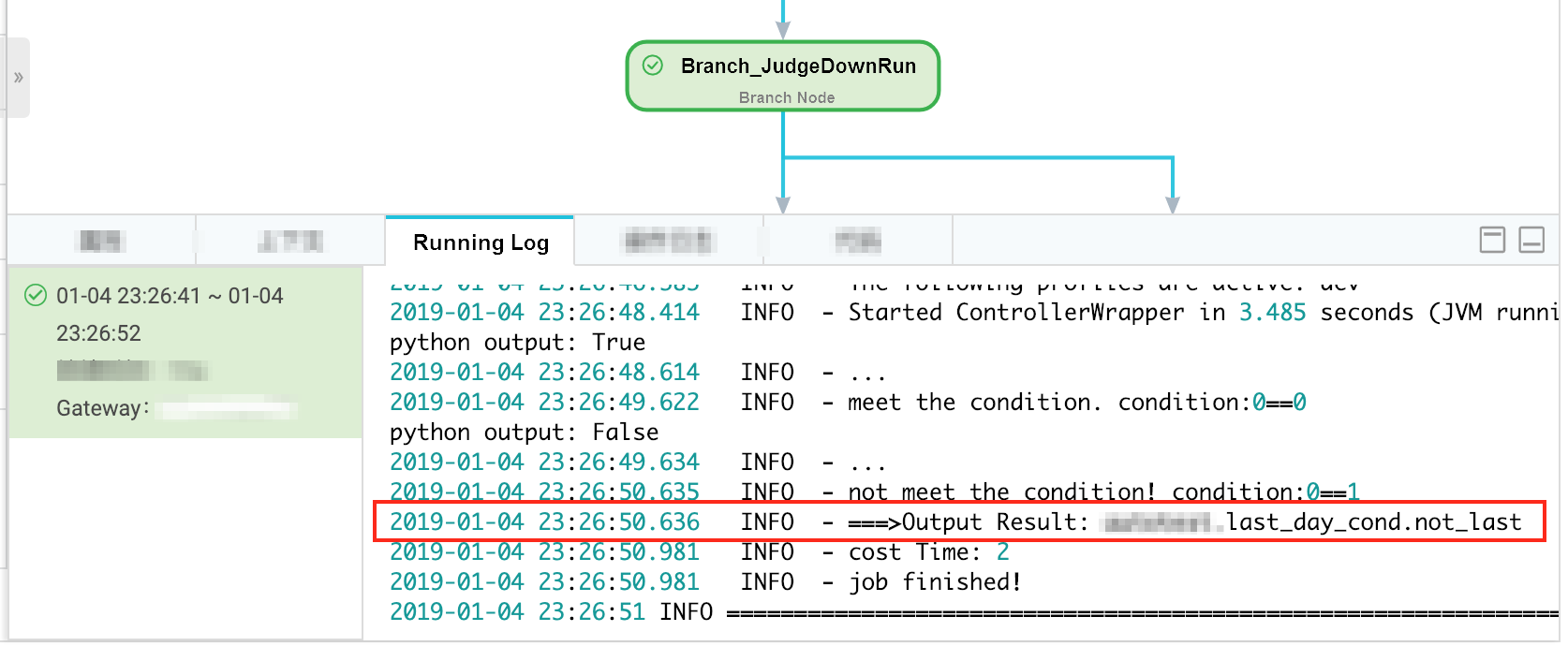
The node that is to be run on the last day is dry run.
The node that is to be run on days except the last day is run as expected.
Summary
Take note of the following instructions when you use branch nodes:
DataWorks captures the last SELECT statement or the last line of the standard output stream of an assignment node as the output of the assignment node. The output is referenced by descendant nodes.
Each output of a branch node is associated with a condition. When you configure a node as a descendant node of a branch node, you must understand the condition that is associated with each output before you select the output.
If a branch is not selected, the descendant node on the branch is dry run. The dry-run property is always passed downstream until a merge node is found.