As a high-performance key-value database, Tair (Redis OSS-compatible) often stores large amounts of critical data for your business. To ensure data security, Tair (Redis OSS-compatible) provides a variety of disaster recovery solutions.
Evolution of disaster recovery architectures
A disaster recovery mechanism ensures data consistency and service availability if an instance fails due to unexpected events, such as hardware malfunctions or power outages in the data center.
Figure 1. Evolution of disaster recovery architectures

Disaster recovery solution | Protection level | Description |
★★★☆☆ | The master node and replica node are deployed on different machines within the same zone. If a node fails, the high availability (HA) system automatically performs a failover to prevent service interruptions caused by a single point of failure (SPOF). | |
★★★★☆ | The master node and replica node are deployed in two different zones within the same region. If a zone becomes unavailable due to factors like power outages or network failures, the HA system performs a failover to ensure the instance remains available. | |
★★★★★ | A Global Distributed Cache instance consists of multiple child instances that synchronize data in real time through dedicated channels. A channel manager monitors the health of the child instances and handles exceptions, such as a failover. This solution is ideal for scenarios like geo-disaster recovery, active geo-redundancy, routing users to the nearest application access point, and distributing load. |
Single-zone HA solution
All instance architectures support a single-zone HA architecture. The HA system monitors the health of the master and replica nodes and automatically performs a failover to prevent service interruptions caused by an SPOF.
Deployment architecture | Description |
Figure 2. HA architecture for a standard dual-replica instance  A standard architecture instance uses a two-node master-replica setup. If the HA system detects a failure on the master node, it automatically initiates a failover, promoting the replica node to become the new master node. When the original master node recovers, it reconnects as the new replica node. | |
Figure 3. HA architecture for a multi-replica cluster instance  In a multi-replica cluster architecture, data is stored on data shards. Each data shard has a multi-replica configuration with nodes deployed on different machines to ensure high availability. If a master node fails, the system automatically performs a failover to maintain service availability. | |
Figure 4. HA architecture for a read/write splitting instance 
|
Multi-zone disaster recovery
Tair (Redis OSS-compatible) provides a zone-disaster recovery architecture that spans multiple zones. If your services are deployed in a single region and require a high level of disaster recovery, you can select the multi-zone option when you create an instance. For instructions, see Create an instance.
Figure 5. Create a zone-disaster recovery instance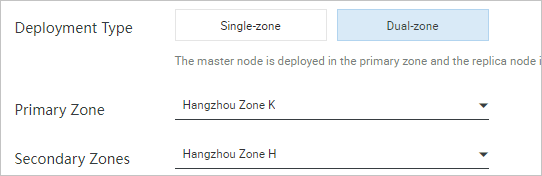
After the instance is created, a replica instance with the same specifications as the primary instance is created in the secondary zone. Data is synchronized between the primary and secondary zones over a dedicated replication channel.
If the primary zone experiences a power or network failure, the system promotes the replica instance to a master instance and calls the Config Server API to update the routing information for the proxy. In addition, Tair (Redis OSS-compatible) optimizes the Redis synchronization mechanism. Similar to the GTID feature in MySQL, Tair uses a global Opid to manage synchronization points. A lock-free background thread performs the Opid lookup, and the AOF binlog is sent asynchronously with rate limiting, which ensures the performance of the Redis service.
Figure 6. Data synchronization process of a zone-disaster recovery instance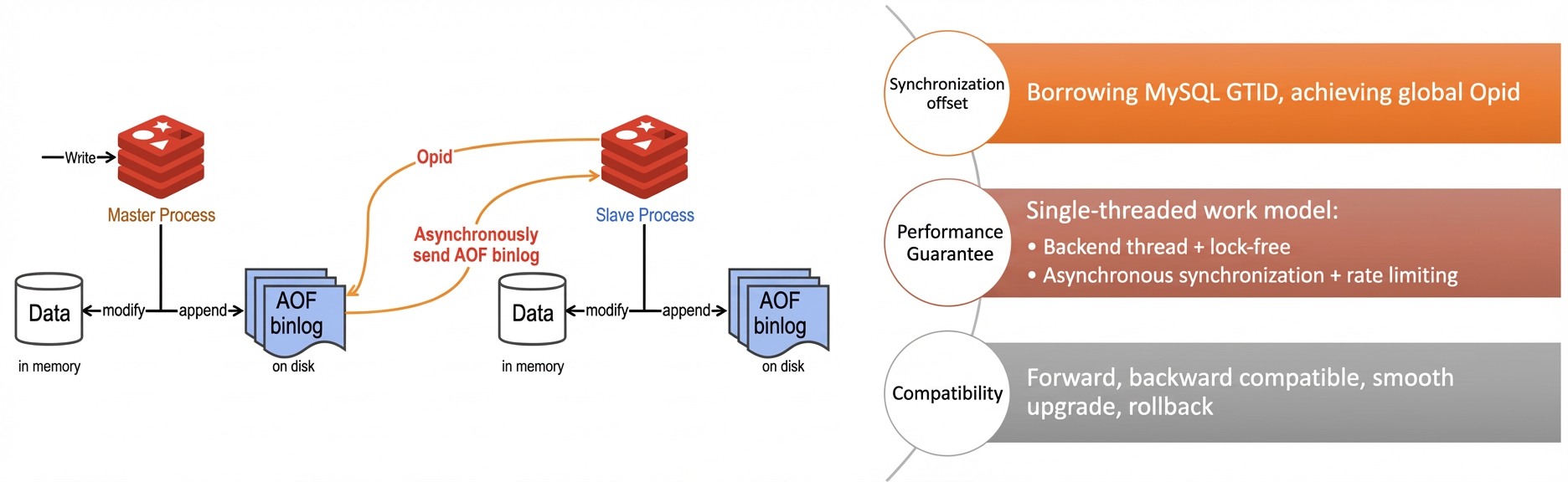
Cross-region disaster recovery
As your business expands globally, a cross-region access architecture can lead to high latency and a poor user experience. The Tair Global Distributed Cache feature reduces this cross-region latency. It offers the following advantages:
You can directly create or specify child instances for synchronization. This eliminates complex application-level redundancy designs, which significantly simplifies development and allows you to focus on your core business logic.
It enables you to quickly implement geo-disaster recovery and active geo-redundancy.
This feature is suitable for cross-region data synchronization and global deployments in industries such as multimedia, gaming, and e-commerce. For more information, see Global Distributed Cache.
Figure 7. Architecture of Tair Global Distributed Cache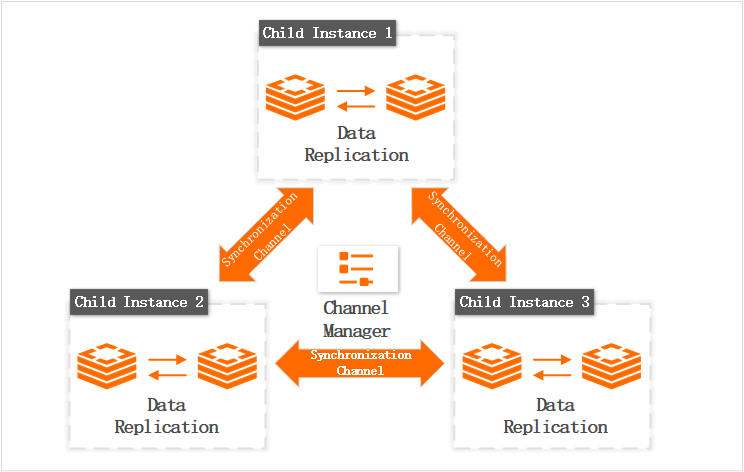
Responding to failures
Failures, such as hardware malfunctions, data center power outages, and natural disasters, can be classified as master node failures or zone-level failures. Although rare, failures can temporarily prevent data writes, cause transient connection issues, or even lead to downtime or data loss. Instance reliability is closely tied to its architecture. Cluster architectures generally offer higher reliability. To minimize the impact of failures, instances with multi-replica and multi-zone deployments automatically perform a failover. This significantly reduces downtime. The following sections describe how instances with different disaster recovery solutions respond to failures.
Responding to a node failure
When a master node fails:
If the instance has multiple replicas in a single zone (for example, a master node and a replica node): The system promotes the replica node with the lowest replication latency to become the new master node and updates the routing information.
If the instance is deployed across multiple zones: The system promotes a replica node in another zone to become the new master node and updates the routing information. However, this may result in cross-zone access between your instance and other services.
NoteIn a multi-zone cluster architecture, if replica nodes exist in both the primary and secondary zones, a failover preferentially promotes a replica node from the primary zone. This avoids cross-zone access for your application.
Responding to a zone-level failure
When a zone-level failure occurs, such as a power outage or a fire that makes an entire data center unavailable:
If the instance is deployed in a single zone: The instance becomes unavailable. You must wait for the zone to recover. During this time, you can create a new instance in another zone by using historical backup data.
If the instance is deployed across multiple zones: The system triggers an automatic failover.
For maximum reliability, deploying across multiple zones and creating multiple replicas in each zone can significantly minimize downtime. However, you must balance the probability of failure, the importance of your data, and the associated costs.
The preceding principles also apply to the child instances of Global Distributed Cache. The failure of a single child instance does not affect the availability of other child instances. We recommend deploying child instances across multiple zones to prevent data write failures if a single child instance fails.