
Instead of putting lots of objects on the heap, Flink serializes objects into a fixed number of pre-allocated memory segments. A memory segment has a fixed size (default size: 32 KB), representing the minimum memory unit in Flink, and can be read and written efficiently. You can consider a memory segment as java.nio.ByteBuffer customized for Flink. It can use a common Java byte array (byte[]) or an off-heap ByteBuffer as the bottom layer. Each record is serialized and stored in one or more memory segments.
A Flink worker is named TaskManager, which is a JVM process used to execute user code. TaskManager's heap memory is divided into three parts:
Network Buffers: A certain number of 32 KB buffers are used for data transmission over networks. The buffers are allocated upon TaskManager startup. By default, there are 2,048 such buffers. You can set taskmanager.network.numberOfBuffers to specify the quantity.
Memory Manager Pool: It is a huge collection of MemorySegments managed by MemoryManager. Flink algorithms (such as sort, shuffle, and join) apply to the pool for MemorySegments, store serialized data in the MemorySegments, and release the MemorySegments after they are no longer required. By default, the pool takes 70% of the heap memory.
Remaining (Free) Heap: This part of heap memory is reserved for user code and TaskManager's data structures. The data structures are small in size, and therefore this part of heap memory is used basically for user code. From the GC perspective, this part of heap memory can be regarded as the young generation, which means that it contains mostly short-lived objects generated by user code.
Note: The Memory Manager Pool should be used in Batchmode. In Steaming mode, the pool does not pre-allocate memory and the pool is not requested for MemorySegments. It means that this part of heap memory can be used by user code. However, the community expects that the pool can be utilized in Streaming mode.
Flink's DBMS-style sort and join algorithms operate on this binary data to keep the serialization/deserialization overhead at a minimum. In this sense, Flink’s internal implementations look more like C/C++ rather than common Java. If more data needs to be processed than can be kept in memory, Flink’s operators partially spill data to disks. If Flink needs to operate multiple MemorySegments in the same way as a large continuous block of memory, it will use the logical view (AbstractPagedInputView) to facilitate the operations. The following figure gives a high-level overview of how Flink stores data serialized in memory segments and spills to disks if necessary.
According to the preceding introduction, Flink's style of active memory management and operating on binary data has several benefits:
Reduced garbage collection pressure. Obviously, as all long-lived data is in binary representation in Flink’s MemoryManager, the memory segments containing the data stay in the old generation and are not recycled by GC. The other data objects are mostly short-lived objects generated by user code. These objects can be quickly recycled by the minor GC. If a user does not create a large number of buffer-like resident objects, the size of the old generation will not change and major GC will never occur. This effectively reduces the garbage collection pressure. The off-heap memory can be used as memory segments, which helps to further reduce the size of the JVM memory and increase garbage collection.
OOM error prevention. All runtime data structures and algorithms can apply only to the memory pool for memory, which ensures that the size of allocated memory is fixed and prevents the OOM error caused by runtime data structures or algorithms. In case of memory shortage, the algorithms (sort/join) can efficiently write large batches of memory segments to disks and read them back later. This effectively prevents the OOM error.
Lower memory requirement. Java objects require much additional overhead when they are stored (as mentioned in the previous section). If only binary content of data is stored, the additional overhead is not required.
Efficient binary operations & cache-friendly computing. Binary data can be efficiently compared and operated on a given suitable binary representation. Furthermore, the binary representations can put related values, as well as hash codes, keys, and pointers, adjacently into memory. This gives data structures with usually more cache efficient access patterns and increases the performance of the L1, L2, and L3 caches (which will be explained in the following section).
Serialization Framework Customized for Flink
The Java ecosystem offers several libraries to convert objects into a binary representation and back. Common alternatives are standard Java serialization, Kryo, and Apache Avro. Flink includes its own custom serialization framework. Generally, Flink processes only data flows of the same type. Because dataset objects belong to the same type, only one copy of object schema information is required for them. This greatly saves storage space. In addition, a fixed-size dataset object can be read and written with a fixed offset. You can use a customized serialization tool and fixed offset to access an object member variable. In this case, you only need to deserialize the specific object member variable instead of deserializing the entire Java object. If a dataset object has multiple member variables, this mechanism helps significantly reduce the Java objection creation overhead and the size of data to be copied in memory.
Flink programs can process data represented as arbitrary Java or Scala objects. Flink can automatically identify data types without dedicated interface (like the org.apache.hadoop.io.Writable interface of Hadoop). For Java programs, Flink features a reflection-based type extraction component to analyze the return types of user-defined functions (UDFs). Scala programs are analyzed with help of the Scala compiler. Flink represents each data type with a TypeInformation. Flink has TypeInformations for several kinds of data types, including:
BasicTypeInfo: Any (boxed) Java primitive type or java.lang.String.
BasicArrayTypeInfo: Any array of a (boxed) Java primitive type or java.lang.String.
WritableTypeInfo: Any implementation of Hadoop’s Writable interface. TupleTypeInfo: Any Flink tuple (Tuple1 to Tuple25). Flink tuples are Java representations for fixed-length tuples with typed fields. CaseClassTypeInfo: Any Scala CaseClass (including Scala tuples). PojoTypeInfo: Any POJO (Java or Scala), i.e., an object with all fields either being public or accessible through getters and setter that follow the common naming conventions. GenericTypeInfo: Any data type that cannot be identified as another type.The first six data types are basically enough to address the needs of most Flink programs. For datasets of those six types, Flink can automatically generate corresponding TypeSerializers to efficiently serialize and deserialize the datasets. For datasets of the last data type, Flink uses Kryo to serialize and deserialize them. Each TypeInformation provides a serializer for the data type it represents. The type is automatically serialized using the serializer and then written to memory segments using the Java Unsafe interface. For data types that can be used as keys, the TypeInformation provides TypeComparators. TypeComparators compare and hash serialized binary data. Tuple, Pojo, and CaseClass types are composite types. As such, their serializers and comparators are also composite and delegate the serialization and comparison of their member data types to the respective serializers and comparators. The following figure illustrates the serialization of a (nested) Tuple3<Integer, Double, Person> object.
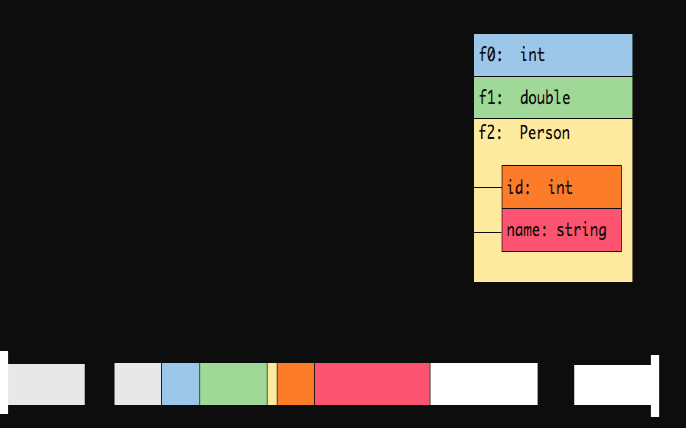
You can see that the serialization achieves high storage density. Among the data, int takes 4 bytes, double takes 8 bytes, and POJO includes multiple one-byte headers. PojoSerializer serializes only the headers and delegates the field-specific serializers to serialize their corresponding fields.
Flink’s type system can be easily extended by providing custom TypeInformations, Serializers, and Comparators to improve the performance of serializing and comparing custom data types.
How Does Flink Operate on Binary Data?
Flink’s APIs provide transformations to group, sort, and join data sets. These transformations operate on potentially very large data sets. Here, sort, which is frequently performed in Flink, is taken as an example.
Upon initialization, a sort algorithm requests its memory budget from the MemoryManager and receives a corresponding set of MemorySegments. The set of MemorySegments becomes the memory pool of a so-called sort buffer which collects the data that has been sorted.
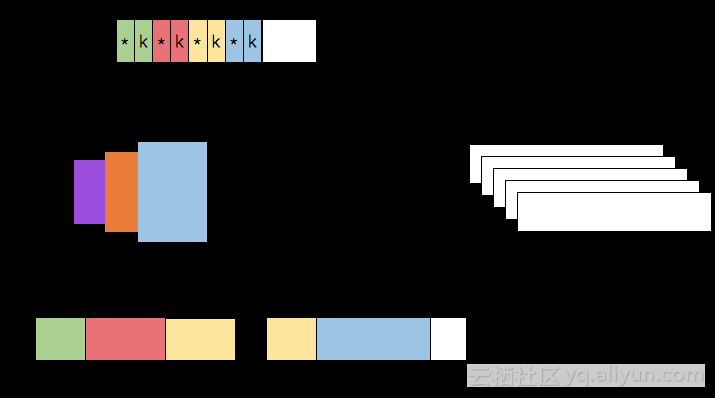
The sort buffer is internally organized into two memory regions. The first region holds the full binary data of all objects. The second region contains pointers to the full binary object data and fixed-length sort keys (key+pointer). If the sort key is a variable length data type such as a String, the fixed-length sort key must be a prefix key. As shown in the preceding figure, when an object is added to the sort buffer, its binary data is appended to the first region, and a pointer (and possibly a key) is appended to the second region.
The separation of actual data and pointers plus fixed-length keys is done for two purposes. 1) It enables efficient swapping of fix-length entries (key+pointer) and also reduces the data that needs to be moved when sorting. 2) It is cache-friendly. Keys are continuously stored in memory, which greatly reduces the cache miss rate (which will be explained in the following section).
Comparison and swapping are critical to sorting. Flink will first compare the sizes of binary sort keys without deserializing the objects. The keys have a fixed length. If two keys are equal (or no binary keys are provided), the sort buffer deserializes both objects and compares the objects. Then, sorting can be implemented without moving the actual data by swapping the keys and pointers.
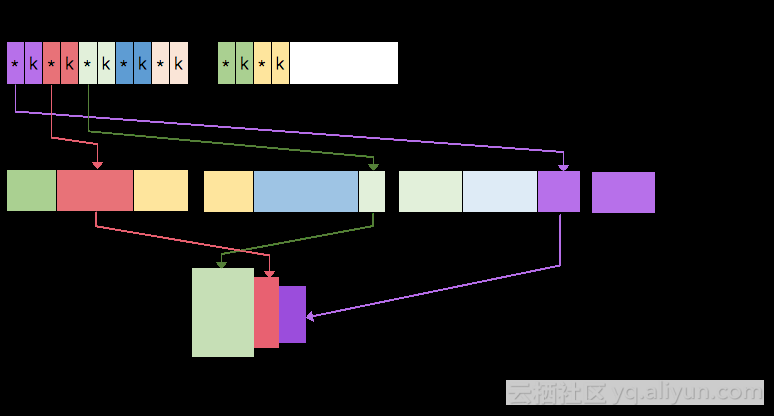
The sorted data is returned by sequentially reading the key+pointer region of the sort buffer and following the sorted pointers to the actual data. The data is then written internally or externally. (For more details, see this blog post on Joins in Flink.)
Cache-Friendly Data Structures and Algorithms
As the disk I/O and I/O get faster and faster, CPUs have gradually become bottlenecks in the big data sector. Reading data from L1/L2/L3 caches is far quicker than reading data from RAM. Performance analysis indicates that, CPUs take a long time to wait for data from RAM. If the data is transferred from the L1/L2/L3 caches, the wait time will be greatly reduced, which benefits all algorithms.
As we mentioned above, Flink uses a custom serialization framework to store the data that needs to be operated (such as sort keys) in a continuous manner and full data in other places. Keys and pointers of full data can be stored in caches more easily, which increases the cache hit rate and the efficiency of basic algorithms. This is transparent to upper-layer applications, which are fully benefited from the performance improvement that results from the cache-friendly mechanism.
Off-Heap Memory
Since Flink' heap-based memory management mechanism is able to address many existing JVM issues, why would Flink introduce off-heap memory?
However, nothing is absolutely powerful, which is why off-heap memory is not used in some cases.
Flink uses ByteBuffer.allocateDirect(numBytes) to apply for off-heap memory and sun.misc.Unsafe to operate off-heap memory.
Off-heap memory can be used easily based on Flink. Flink converts the MemorySegment class into an abstract class and creates two sub-classes, namely HeapMemorySegment and HybridMemorySegment. You can easily tell the usage of the sub-classes from their names. The former is used to allocate heap memory, while the latter is used to allocate both off-heap memory and heap memory. It is true that the latter can be used to allocate both. Why the design?
First, assume that HybridMemorySegment can be used to allocate only off-heap memory. As mentioned above, Flink sometimes needs to allocate short-lived memory segments, and these memory segments will have higher efficiency if they are allocated using HeapMemorySegment. So, Flink needs to load both sub-classes when it needs to use off-heap memory as well as heap memory. This leads to a JIT compilation optimization issue. Originally, the MemorySegment class is a standalone final class without sub-classes. During JIT compilation, all the methods to be called are correct and all method calling operations can be de-virtualized and inlined. This greatly improves the performance when memory segments are used frequently. If two sub-classes are loaded at the same time, the JIT compiler can distinguish the sub-classes only when using either of them. Therefore, optimization cannot be performed in advance. According to tests, the performance can be increase by about 2.7 folds after advance optimization.
Flink offers two solutions to this problem:
Solution 1: Only one MemorySegment sub-class can be loaded.
Only one sub-class is instantiated for all short-lived and long-lived memory segments and the other is not instantiated. (It is controlled using the factory mode). After a while, JIT will realize that all the methods called are correct and perform optimization accordingly.
Solution 2: A sub-class that can allocate both heap memory and off-heap memory is provided.
This sub-class is HybridMemorySegment. If this sub-class is used, no other sub-classes are required. Flink allows, in an elegant manner, the same code to operate both heap memory and off-heap memory. It is achieved with a series of methods that sun.misc.Unsafe offers, such as the getLong method shown in the following:
sun.misc.Unsafe.getLong(Object reference, long offset)The following introduces the implementations of the MemorySegment class and its sub-classes.
public abstract class MemorySegment {
// Heap memory reference
protected final byte[] heapMemory;
// Off-heap memory reference
protected long address;
//Heap memory initialization
MemorySegment(byte[] buffer, Object owner) {
//Inspection
...
this.heapMemory = buffer;
this.address = BYTE_ARRAY_BASE_OFFSET;
...
}
//Off-heap memory initialization
MemorySegment(long offHeapAddress, int size, Object owner) {
//Inspection
...
this.heapMemory = null;
this.address = offHeapAddress;
...
}
public final long getLong(int index) {
final long pos = address + index;
if (index >= 0 && pos <= addressLimit - 8) {
// Using Unsafe to operate heap memory and off-heap memory, which concerns us
return UNSAFE.getLong(heapMemory, pos);
}
else if (address > addressLimit) {
throw new IllegalStateException("segment has been freed");
}
else {
// index is in fact invalid
throw new IndexOutOfBoundsException();
}
}
...
}
public final class HeapMemorySegment extends MemorySegment {
// Additional reference toheap memory for checking for out-of-bounds array
private byte[] memory;
// Initialization of only the heap memory
HeapMemorySegment(byte[] memory, Object owner) {
super(Objects.requireNonNull(memory), owner);
this.memory = memory;
}
...
}
public final class HybridMemorySegment extends MemorySegment {
private final ByteBuffer offHeapBuffer;
//Off-heap memory initialization
HybridMemorySegment(ByteBuffer buffer, Object owner) {
super(checkBufferAndGetAddress(buffer), buffer.capacity(), owner);
this.offHeapBuffer = buffer;
}
//Heap memory initialization
HybridMemorySegment(byte[] buffer, Object owner) {
super(buffer, owner);
this.offHeapBuffer = null;
}
...
}We can see that many methods of HybridMemorySegment are actually implemented by its parent class, including heal memory initialization and off-heap memory initialization. The getXXX and putXXX methods of the MemorySegment class call the unsafe method. This means that the MemorySegment class has the Hybrid feature. HeapMemorySegment calls only the MemorySegment(byte[] buffer, Object owner) method of the parent class, and therefore only requests for heap memory are allowed. In addition, many methods (getXXX/putXXX) are marked as final according to the code and the two sub-classes are final classes. This aims to optimize the JIT compiler and notify JIT that the methods can be de-virtualized and inlined.
HybridMemorySegment can be used to allocate both long-lived off-heap memory and short-lived heap memory. Why is Solution 1 required when HybridMemorySegment is available? That's because we need a factory mode to ensure that only one sub-class is loaded (for better performance) and HeapMemorySegment is faster than HybridMemorySegment in terms of heap memory allocation.
The following provides some test data.
|
Segment |
Time |
|
HeapMemorySegment, exclusive |
1,441 msecs |
|
HeapMemorySegment, mixed |
3,841 msecs |
|
HybridMemorySegment, heap, exclusive |
1,626 msecs |
|
HybridMemorySegment, off-heap, exclusive |
1,628 msecs |
|
HybridMemorySegment, heap, mixed |
3,848 msecs |
|
HybridMemorySegment, off-heap, mixed |
3,847 msecs |
This article describes the JVM issues that Flink needs to address and elaborates on its memory management mechanism, serialization framework, and off-heap memory allocation mechanism. Actually, all open-source projects in the big data ecosystem show the same features as Flink. For example, the Spark Tungsten project, which is a hot topic recently, employs a memory management idea similar to that of Flink.
How to Prevent WordPress Bounce Attacks with an Old yet Powerful Trick

2,593 posts | 795 followers
FollowAlibaba Clouder - November 15, 2019
Apache Flink Community China - November 6, 2020
Apache Flink Community China - August 8, 2022
Apache Flink Community China - January 9, 2020
Apache Flink Community - April 16, 2026
Apache Flink Community - October 12, 2024
2,593 posts | 795 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn MoreMore Posts by Alibaba Clouder

