Author: Jingsong Lee, Alibaba Cloud, Staff Engineer, PMC Chair of Apache Paimon, PMC member of Apache Flink
I have long been in the field of distributed computing and storage, with contributions to multiple open-source projects. In this article, I will review how the scenarios of stream computing gradually expanded over the years and introduces the evolution of Apache Paimon. 
(The closer to vertexes, the better)
I referenced this figure from Napa: Powering Scalable Data Warehousing with Robust Query Performance at Google in a long-ago article he published. The figure illustrates the observation that big data systems are always products of trade-offs (not to mention the factor of how much work is needed by developers). There is no silver bullet, only solutions tailored to specific scenarios. This also holds water for the solutions described in this article.
(The article is based on past experience of the author, and therefore may not be free from personal opinions and errors.)
About a decade ago, Apache Storm was open-sourced. This ingenious stream computing system consists of only 8,000 lines of Clojure code and is implemented at-least-once delivery smartly with the ACK mechanism. With Storm, users can create a functional data stream pipeline without worrying about data loss. However, as business expands, users started paying more attention to exactly-once guarantee and SQL API support.
Back when, distributed stream computing hadn't been devised, people tried implementing real-time computing by scheduling batch tasks. An example was Apache Hive, which enabled minute-level scheduling, but could not achieve shorter latency due to the high cost of scheduling and start/stop of processes. Another example was Apache Spark. With the outstanding design of resilient distributed datasets (RDDs), Spark provides Spark Streaming, process persistence, and mini-batch processing, delivering stream computing capabilities on top of batch processing with exactly-once guarantee. However, due to the high overhead in scheduling, it is not factually a stream processing engine, and the latency cannot go past the minute-level mark.
In 2014, Apache Flink was launched. It comes with built-in storage for states and global, consistent snapshots, therefore able to offer an exactly-once guarantee in early-fire mode and strike a balance between data consistency and low latency.
Also in 2014, I joined Alibaba's team of Galaxy (a stream computing architecture similar to Apache Flink), which specialized in the stream computing business within the company. Specifically, I handled the push of data streams to Tair, a KV store engine in-house to Alibaba. Our stream computing solution back then was a combination of a stream computing engine and a real-time KV store. 
This solution is centered around multi-dimensional data preprocessing. After data is preprocessed, it is written to a simple KV store like HBase or Redis or a small-sized relational database. What the stream computing engine does in the solution is process stream data, manage the data states, and push the data out to the KV store.
The solution has its pros and cons:
Nevertheless, is there a solution that is more flexible, relieving users of the need to create a new process for every new business scenario?
Developed by Yandex, ClickHouse was open-sourced in 2016. Though designed as a standalone OLAP engine, it can also serve as the building block of a distributed OLAP system. One of its major advantages is that it delivers outstanding query performance thanks to the use of vectorized computing. This extends its use cases beyond predefined computing, since users can put their business data in ClickHouse databases and perform queries based on their needs.
The popularity of ClickHouse inspired many excellent OLAP projects in China, such as Doris, StarRocks, and Hologres (by Alibaba Cloud). At Alibaba Group, teams for JStorm, Galaxy, and Blink have been merged to concentrate efforts for Blink. Developed on top of Flink, Blink has an advanced architecture, high-quality code, and a vibrant community.
The combination of Flink and Hologres gave birth to a new pipeline: preprocessing data with Flink without finalizing the business data and then passing the preprocessed data to Hologres, which in turn stores the data and provides high-performance query to data consumers. This solution delivers higher flexibility compared with the KV store solution. 
It has the following advantages:
The trade-off in this solution is as follows:
Is there a solution that lets us store all data at affordable cost?
People have been looking for a storage system that is less costly than OLAP systems, so that they can keep all the data in the storage and perform ad-hoc queries, even though the responses may not be as fast.
I started my work in the Blink team focusing on its batch processing capabilities. As time goes by, I started to look beyond integrating the compute modes for stream and batch processing, so as to deliver higher business value.
Therefore, my colleagues and I started the work on a Flink + Hive solution. 
A Hive Streaming Sink supports Parquet, ORC, and CSV formats, provides exactly-once guarantee, and supports partition-commit, allowing log data to be written into data warehouses in streams. Here are the pros and cons of this solution:
As Snowflake and Databricks gained growing popularity, data lake has been taking the place of traditional Hive-based data warehouses.
A typical data lake used in stream computing scenarios is Apache Iceberg. It provides the following advantages over Hive:
Scalable metadata management

In this solution, data can be injected to the data lake in real time, and data managed by Iceberg can be read in real time. This allows for higher flexibility over Hive-based data warehouses.
However, the solution has the following drawbacks in UPSERT operations:
Traditional Hive-based data warehouses use a combination of full tables and incremental tables to handle incoming change data, as shown in the following figure. 
Procedure:
In 2020, our team at Alibaba Cloud delved into three major lake house solutions: Iceberg, Hudi, and Delta. HU Zheng, my then colleague and currently an Iceberg PMC member, wrote an article comparing the three solutions. In that article, he drew an interesting house-building analogy to summarize their differences. 
After the community's efforts, we have developed a preliminary CDC (Change Data Capture) data writing solution with Flink + Iceberg, supporting near real-time data writing and reading.
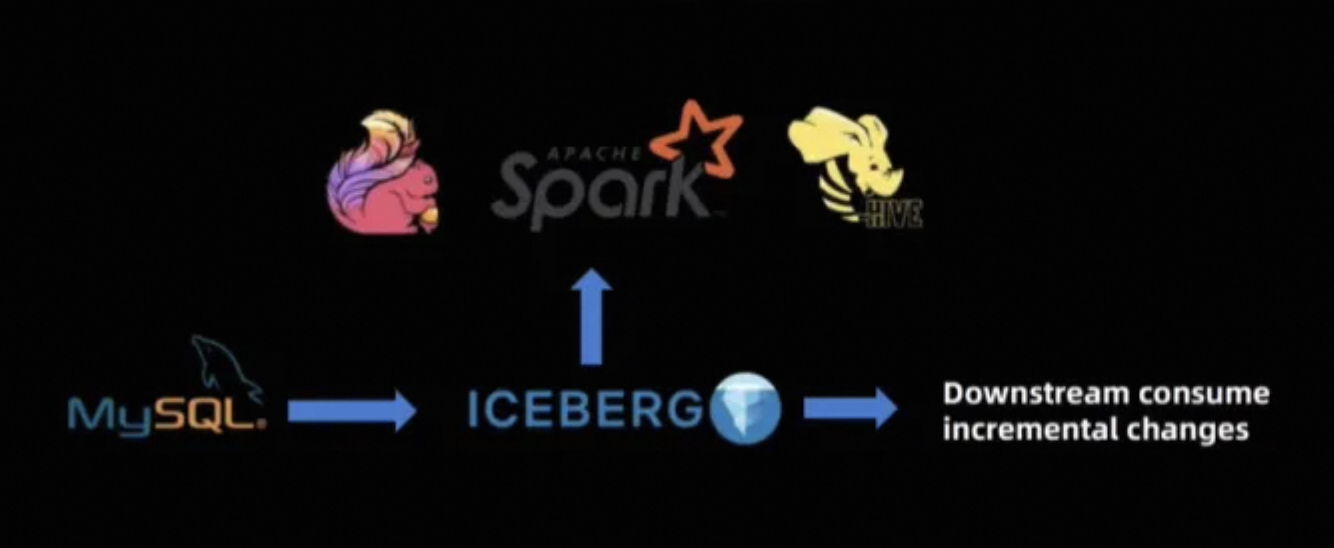
For now, the combination of Flink and Iceberg is able to be put into production environments, data processed by Flink can be stored in data lakes, and the stream of change data to data lakes is basically functional.
However, the streaming solution for change data is still far from ideal in terms of large-scale updates and near-real-time latency, not to mention reading data in streams. This discrepancy is caused by the following factors:
Another upsertable solution involves using Flink and Hudi. CHEN Yuzhao, my then colleague and currently a Hudi PMC member, created Flink + Hudi Connector with the Hudi community. 
By default, Huid uses a Flink state backend to store the indexes that map keys to file groups. This method is starkly different from that of Spark.

This is a simple but on-point solution. It stores data partitions in buckets based on hash algorithms. Each bucket corresponds to a file group.
There are also a lot of Alibaba Cloud users using Hudi. As the userbase continues to expand, issues start to emerge:
(2) Copy-on-Write or Merge-on-Read? One causes poor write throughput, and the other leads to underperformance.
Though Hudi has been much stabler in recent updates, if you take a look at the latest Hudi Roadmap (https://hudi.apache.org/roadmap), you may notice that little planning is made for Flink or data streams in general. Commonly, new Hudi features are supported only by Spark, not Flink. If Flink is to support a new feature, it has to go through heavy refactoring, and new bugs can easily be introduced in the process, not to mention the possibly substandard end result. Unquestionably, Hudi is an outstanding system, but it is not meant for real-time data lakes.
Then what are the characteristics of an ideal storage system?

Start of Flink Table Store (FTS): Database or Data Lake
In 2021, I started a discussion on the Flink community: FLIP-188: Introduce Built-in Dynamic Table Storage (https://cwiki.apache.org/confluence/display/FLINK/FLIP-188%3A+Introduce+Built-in+Dynamic+Table+Storage), raising the idea of a Flink-oriented storage system named Flink Table Store (FTS). It addresses issues like those in real-time processing, near-real-time processing, queueing, and table formats. The combination of Flink and FTS will be able to achieve automated stream processing of materialized views and provide queries. It will be a full-fledged "StreamingDB". 
The project sounds rosy, but it's easier said than done.
After several months of development, we formulated a roadmap. We decided to start from a data lake architecture and create a full-fledged data pipeline that addresses pain points in real-world scenarios together with tools from the ecosystem. In May 2021, we released version 0.1. It was an unusable version, but a preliminary demo of this starting-from-scratch project.
In September, version 0.2 was released. It provided better functionalities. Some community members took notice and put FTS in their production environments. 
(Compared with the current architecture of Paimon, log systems are no longer a preferred choice. With the exception of response latency, a data lake provides much better capabilities then a log system.)
FTS is a data lake system, used for the real-time writes of change logs in streams (such as those from Flink CDC) and high-performance queries. It combines lake storage and the LSM structure, boasts high compatibility with Flink, and supports real-time data updates. It can handle influx of change data with high throughput, while delivering excellent query performance.
Then, FTS 0.3 was released. 
Till version 0.3, a lakehouse solution designed for streaming had taken shape, and we could comfortably recommend FTS for production use.
In addition to supporting writing data to data lakes, FTS also supports features like partial-update, which offers users more flexibility in finding the balance between latency and cost.
After three versions, FTS has gained decent maturity, but as part of the Apache Flink community, it cannot work with other ecosystems, such as Spark. To put it on a bigger stage, Flink PMC decided to donate it to Apache Software Foundation as an independent project. On March 12, 2023, FTS was officially adopted by the Apache Incubator and got its name changed to Apache Paimon.
After being included in the Apache Incubator, Paimon attracted widespread attention from the public, including renowned companies like Alibaba Cloud, ByteDance, BiliBili, Autohome, and Ant Group. 
Meanwhile, we are constantly improving Paimon's compatibility with Flink. It comes with Flink CDC and supports fully automated synchronization of data, schemas, and databases, thereby improving the performance, cost-efficiency, and user experience. The following image illustrates its architecture. 
What exactly are the benefits of Apache Paimon?
Apache Paimon: Real-time Streaming of Change Data to Data Lakes
As mentioned above, when handling the transfer of change data to data lakes, a traditional data warehouse solution involves both full data tables and incremental data tables. In contrast, a solution with Paimon is much simpler, as shown in the following figure. 
Overview:
Paimon is not only a technology for writing change data to data lakes, but a data lake solution that is designed for data stream scenarios, delivering features like near-real-time partial-update and changelog-based data reads.
Paimon supports the partial-update table type. Multiple stream jobs can write to the same partial update table and update different columns. The column updates can even be performed on a version-specific basis. The consumers of data can query all columns of the table.
In future updates, Paimon is expected to have better computational capabilities in near-real-time scenarios by providing addition of columns to tables based on foreign keys. Stream engines and OLAP systems have never been good at handling joins. Hopefully, streaming data lakes can serve as a solution on this front. 
When there is data update, there is a need for changlog-based data reads. If downstream consumers require complete rows after the table is updated, the change logs need to be generated by the storage system.
The full-compaction changelog-producer may cause rewrite of all data, and therefore is a very costly change log production mode. Sometimes, even Avro, the more performant format for full data read/write, cannot meet the requirements.
Thanks to the LSM file structure, Paimon also provides the lookup changelog-producer, which generates complete change logs based on original values. 
The lookup mode allows you to build a real-time data stream pipeline while ensuring the integrity of stream processing.
You can also specify consumer IDs in Paimon, which is similar to group-id in Kafka:
SELECT * FROM t /*+ OPTIONS('consumer-id' = 'myid') */;When tables in Paimon are read in streams, the ID of the involved snapshot is recorded. This is beneficial in the following ways:
The greatest benefit is actually the lack of burden. Moving forward from scratch, there are still many problems to be solved in designing a streaming data lake today. If you are dragging a heavy cart forward, progress is slow and difficult. However, Paimon has only one mission: streaming data lake.
Summary and Future Considerations
This article roughly outlines the history and development of stream computing + lake storage through my experiences.

These are what we want to achieve with the streaming lakehouse:
If you are interested in learning more about Apache Paimon, please follow Apache Paimon on GitHub.
To experience Apache Paimon firsthand on Alibaba Cloud, visit Realtime Compute for Apache Flink and start your free trial here.
Understand Flink SQL: Real-Time SQL Query Execution for Stream and Batch Data
In-depth Application of Flink in Ant Group Real-time Feature Store

207 posts | 58 followers
FollowApache Flink Community - July 5, 2024
Apache Flink Community - May 10, 2024
Alibaba EMR - April 15, 2024
Apache Flink Community - November 21, 2025
Apache Flink Community - January 31, 2024
Apache Flink Community - September 30, 2025
207 posts | 58 followers
Follow Big Data Consulting for Data Technology Solution
Big Data Consulting for Data Technology Solution
Alibaba Cloud provides big data consulting services to help enterprises leverage advanced data technology.
Learn More Big Data Consulting Services for Retail Solution
Big Data Consulting Services for Retail Solution
Alibaba Cloud experts provide retailers with a lightweight and customized big data consulting service to help you assess your big data maturity and plan your big data journey.
Learn More Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More ApsaraMQ for RocketMQ
ApsaraMQ for RocketMQ
ApsaraMQ for RocketMQ is a distributed message queue service that supports reliable message-based asynchronous communication among microservices, distributed systems, and serverless applications.
Learn MoreMore Posts by Apache Flink Community

