The Rise of AI Agents
AI agents evolved from chatbots to autonomous systems. Learn the production stack—ACS, ACK, OSS Vector Bucket—that powers secure, scalable agent deployments.
Executive Summary

AI agents have moved beyond single‑turn assistants into proactive, goal‑driven systems that plan, act, and coordinate across tools and data to complete multi‑step workflows.
The practical adoption of agents accelerated when real, usable agent products proved they could actually do things for people—clearing inboxes, scheduling, and automating cross‑system tasks.
This post explains why OpenClaw helped spark the agent wave, and how a production stack built from OpenClaw‑style agents, Alibaba Cloud ACS (secure agent sandboxes), ACK (Kubernetes orchestration), and OSS Vector Bucket / MetaQuery (semantic storage) can deliver secure, scalable, and cost‑efficient agent deployments.
Why OpenClaw Helped Spark the Rise of AI Agents

OpenClaw is a useful case study for how agents moved from research demos to everyday utility:
Practical utility: OpenClaw demonstrated that agents can be more than conversational toys. By combining persistent memory, plugin/skill extensibility, browser automation, and multi‑channel access (WhatsApp, Telegram, Slack, etc.), it made agentic workflows genuinely helpful for routine tasks. People adopt tools that save time and reduce friction; OpenClaw showed that agents could do both.
Low friction, high reach: Multi‑channel support lowered the barrier to use—agents that live in the apps people already use are easier to adopt than ones that require new UIs or workflows.
Privacy and local‑first options: OpenClaw’s ability to run locally or on private infrastructure illustrated a path for agents that respect data ownership while still offering powerful automation—an important trust signal for both consumers and enterprises.
These practical demonstrations created demand for production‑grade infrastructure that could run many agents safely, cheaply, and with enterprise controls—hence the focus on secure sandboxes, elastic compute, and semantic storage.
What a Production Agent Stack Looks Like

A reliable, production‑grade agent platform combines several layers. Below is a concise architecture and the role each layer plays.
Core components
LLM + Planner — the reasoning core that decomposes goals into tasks and decides when to call tools.
Agent Orchestrator — manages session lifecycle, multi‑agent coordination, retries, and policy enforcement.
Sandbox Runtime (ACS) — isolated execution environments for tool calls, code execution, and browser automation.
Kubernetes Orchestration (ACK) — cluster management, image caching, pre‑scheduling, and policy enforcement at scale.
Tool Connectors (MCPs) — secure adapters for email, databases, web UIs, and enterprise APIs.
Memory & Semantic Storage (OSS Vector Bucket + MetaQuery) — embeddings and raw objects for fast RAG retrieval and provenance.
Observability & Governance — tracing, replayable logs, and fine‑grained authorization for compliance and debugging.
How it flows
1. User or system issues a goal.
2. LLM/planner decomposes the goal into tasks and selects tools.
3. Orchestrator schedules tasks into sandboxes (ACS) with the right permissions.
4. Sandboxes execute tasks (browser automation, DB queries, file ops) and write results to storage.
5. Memory and vector retrieval (OSS Vector Bucket / MetaQuery) provide context for subsequent steps or final responses.
6. Observability captures the entire trace for audit and replay.
Compute: Secure, Elastic, and Stateful Sandboxes (ACS + ACK)

Agents introduce three compute challenges: security, elasticity, and statefulness. The right runtime patterns address all three.
Security: Agents may execute arbitrary code or interact with external systems. Use microVM‑style sandboxes (hardware‑level isolation) to prevent lateral movement and to contain malicious prompts or code. Enforce identity‑based permissions for every tool call. Each sandbox should have a minimal permission set (least privilege) and every external action should be auditable.
Elasticity: Agents spawn many short‑lived sandboxes concurrently. Image caching and pre‑scheduling reduce cold starts dramatically—image pull times can be reduced by over 90% with region‑level caches and prefetch strategies. ACK (Kubernetes) manages cluster resources and policies; ACS provides the microVM sandboxes. Together they enable thousands of sandboxes per minute with predictable latency.
Statefulness: Agents often run multi‑step, long‑horizon processes. Checkpoint & restore lets you snapshot memory and filesystem state so sessions can be forked, migrated, or resumed without reinitializing large contexts. Hibernation stops CPU/memory billing while preserving state on disk; rapid resume (seconds) keeps interactive latency low while reducing TCO.
Operational checklist for compute
1. Use microVM sandboxes for per‑agent isolation.
2. Implement image cache layers and prefetch strategies.
3. Provide checkpoint/restore and hibernate/resume APIs.
4. Instrument full tracing and audit logs for every sandbox action.
Semantic Storage and RAG: Grounding Agents with OSS Vector Bucket + MetaQuery

Agents need accurate, up‑to‑date context from unstructured corpora. Retrieval‑Augmented Generation (RAG) is the operational pattern that prevents hallucinations and grounds agent actions.
Storing embeddings alongside raw objects (documents, images, video) reduces retrieval latency and operational complexity. OSS Vector Bucket is an example of this pattern: embeddings live with the objects, enabling serverless vector search and lowering costs compared to dedicated vector DBs.
Ingest: chunk documents at semantic boundaries and generate embeddings at ingest time.
Index: store embeddings in OSS Vector Bucket or MetaQuery indexes.
Retrieve: fetch top‑K semantically relevant chunks for a query.
Inject: include retrieved chunks (with provenance metadata) in the LLM prompt.
Generate: produce a grounded answer and attach source citations.
Best practices
1. Attach provenance metadata (source, timestamp, confidence) to every chunk.
2. Use hybrid retrieval (sparse + dense) for cost/performance tradeoffs.
3. Cache hot retrievals for high‑QPS flows.
Agentic Execution Loop: Plan, Act, Observe, Learn
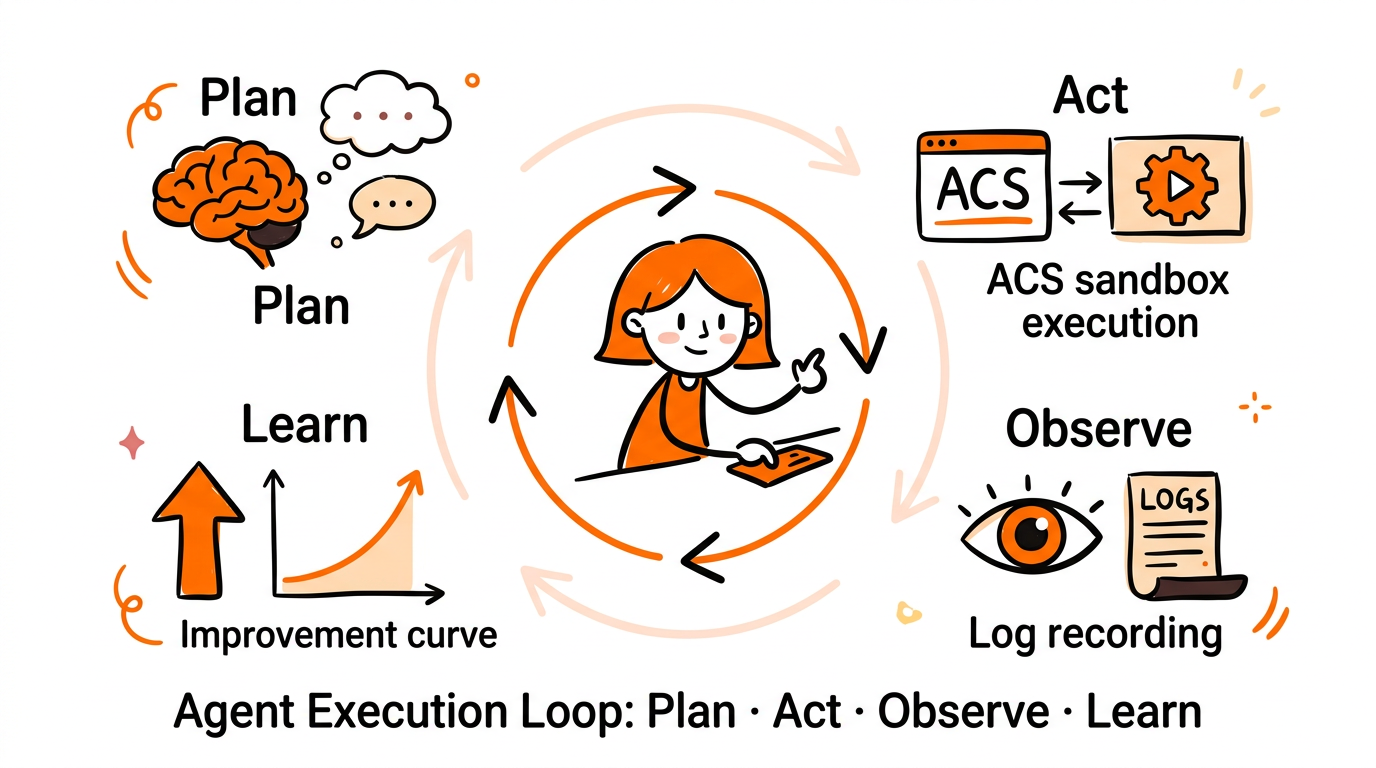
A robust agent loop includes planning, safe execution, observation, and learning:
Plan: LLM decides which tools to call and which context to use.
Act: Orchestrator schedules tasks into ACS sandboxes; sandboxes execute with strict permissions.
Observe: Results are written to storage; observability captures traces and metrics.
Learn: Use logs and outcomes to refine policies, update retrieval indexes, and improve planner heuristics.
This loop supports both deterministic workflows (e.g., scheduled report generation) and exploratory workflows (e.g., forked RL experiments using checkpoint/restore).
Example Workflows and Use Cases
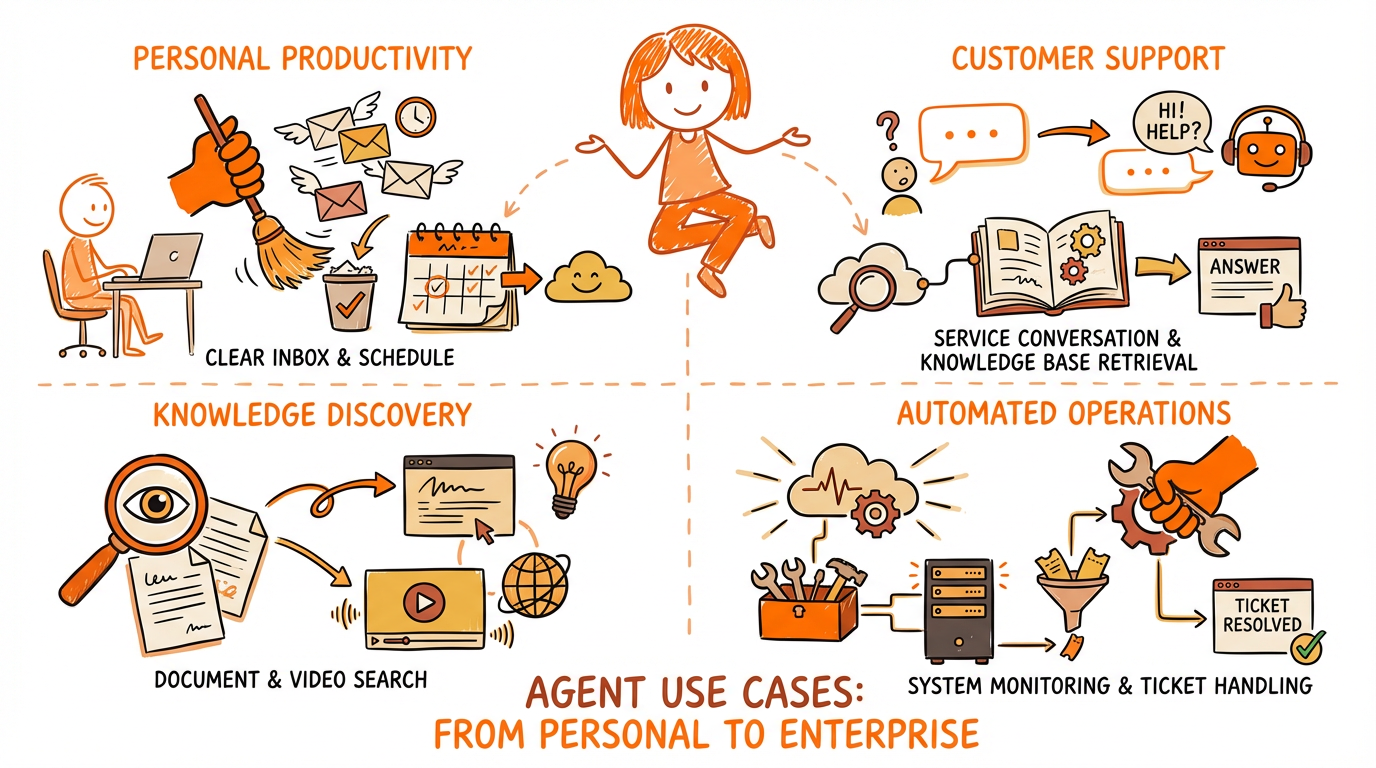
Personal productivity: OpenClaw‑style agents that clear inboxes, schedule meetings, and summarize daily priorities while keeping data local.
Customer support: Agents retrieve past tickets and product docs to draft accurate responses and escalate when needed.
Knowledge discovery: Natural‑language search across documents and video archives using MetaQuery for fast, sourced answers.
Automated operations: Agents that run cross‑system reconciliation, create tickets, and trigger human review only when exceptions occur.
Engineering Checklist Before Production
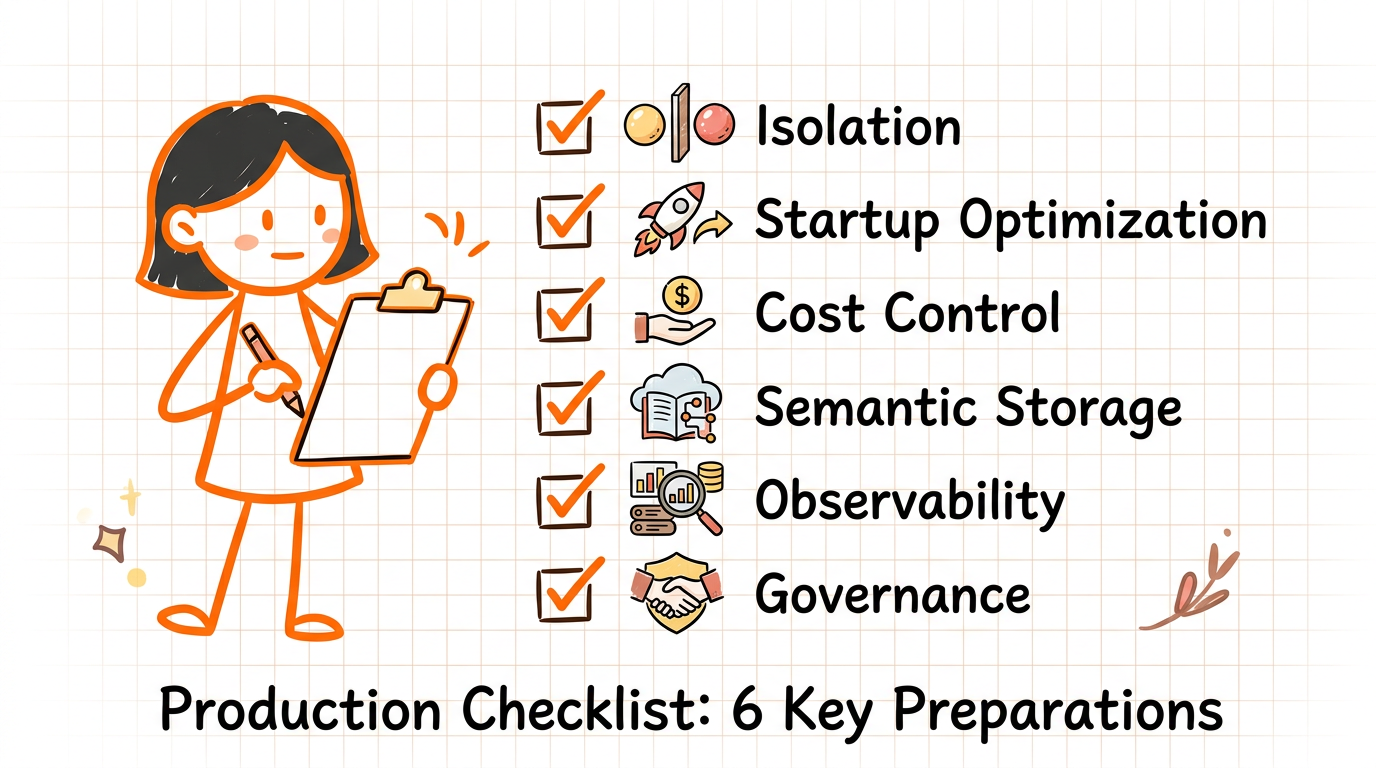
Isolation: microVM sandboxes per agent task; no east‑west lateral movement.
Startup: image cache + pre‑scheduling to reach second‑level readiness.
Cost control: hibernation + checkpoint/restore to avoid paying for idle compute.
Semantic storage: embed at ingest time and co‑store embeddings with objects in OSS.
Observability: end‑to‑end tracing, replayable logs, and action provenance.
Governance: policy engine for allowed tool calls, rate limits, and human‑in‑the‑loop gates.
Security and Compliance Considerations
Input sanitization and prompt filtering to reduce injection risk.
Tool whitelisting and runtime policies to prevent unauthorized external actions.
Audit trails and replayability for forensic analysis and regulatory compliance.
Data residency and encryption for regulated workloads; OSS and ACK can be configured for VPC and on‑prem scenarios.
Conclusion
OpenClaw’s practical, multi‑channel agent model helped prove the value of agentic workflows. To move from prototypes to production, teams need a stack that combines secure, stateful sandboxes (ACS), orchestration and policy (ACK), and semantic storage (OSS Vector Bucket + MetaQuery)—all tied together by a planner/LLM and robust observability. Prioritize isolation, fast startup, state persistence, and semantic retrieval to build agent experiences that are useful, safe, and cost‑efficient.
-

-
12 posts | 2 followers
Follow
You may also like
 Container Service for Kubernetes
Container Service for Kubernetes
 Container Registry
Container Registry

