在进行历史文件采集、数据迁移或批量数据处理等场景时,传统的增量日志采集方式无法满足一次性采集已有静态文件的需求。主机文本一次性采集功能支持通过控制台或API批量下发采集配置到机器组,一次性采集指定的静态文件内容,采集完成后任务自动结束。
适用范围
LoongCollector 3.3及以上版本。
仅支持Linux与Windows平台的主机采集场景,不支持容器场景采集。
采集配置创建流程
准备工作:创建Project和LogStore,Project是资源管理单元,用于隔离不同业务日志,而LogStore用于存储日志。
配置机器组(安装LoongCollector):根据服务器类型,安装LoongCollector,并将其加入到机器组。使用机器组统一管理采集节点,对服务器进行配置分发与状态管理。
查询与分析配置:系统默认开启全文索引,支持关键词搜索。建议启用字段索引,以便对结构化字段进行精确查询和分析,提升检索效率。
准备工作
在采集日志前,需规划并创建用于管理与存储日志的Project和LogStore。若已有可用资源,可跳过此步骤,直接进入配置机器组(安装LoongCollector)。
创建Project
创建LogStore
单击Project名称,进入目标Project。
在左侧导航栏,选择
 ,单击+。
,单击+。在创建LogStore页面,完成以下核心配置:
Logstore名称:设置一个在Project内唯一的名称,该名称创建后不可修改。
Logstore类型:根据规格对比选择标准型或查询型。
计费模式:
按使用功能计费:按存储、索引、读写次数等各项资源独立计费。适合小规模或功能使用不确定的场景。
按写入数据量计费:仅按原始写入数据量计费,提供30天免费存储,以及免费的数据加工、投递等功能。适合存储周期接近30天或数据处理链路复杂的业务场景。
数据保存时间:设置日志的保留天数(1~3650天,3650为永久保存),默认为30天。
其他配置保持默认,单击确定。如需了解其他配置信息,请参考管理LogStore。
步骤一:配置机器组(安装LoongCollector)
在完成准备工作后,为不同类型的服务器安装LoongCollector并将其加入机器组。
以下安装步骤仅适用于日志源为阿里云ECS实例,且该实例与日志服务Project属于同一阿里云账号和相同地域的场景。
如果您的ECS实例与Project不在同一账号或地域,或者日志源为自建服务器,请参考LoongCollector 安装与配置进行操作。
配置步骤:
在
 日志库页面,单击目标LogStore名称前的
日志库页面,单击目标LogStore名称前的 展开。
展开。单击,在Logtail一次性配置页签下,单击添加Logtail配置。
在快速数据接入弹框中,单击一次性文件采集 - 主机卡片上的立即接入。
在机器组配置页面,配置如下参数:
使用场景:主机场景
安装环境:ECS
配置机器组:根据目标服务器的LoongCollector安装情况与机器组配置状态,选择对应操作:
已安装LoongCollector且已加入某个机器组,直接在源机器组列表中勾选,将其添加至应用机器组列表,无需重复创建。
未安装LoongCollector,单击创建机器组:
以下步骤将引导您完成LoongCollector的一键自动安装并创建机器组。
系统会自动列出与 Project 同地域的 ECS 实例,勾选需要采集日志的一台或多台实例。
单击安装并创建为机器组,系统将自动在所选ECS实例上安装LoongCollector。
配置机器组名称并单击确定。
说明如果安装失败或一直处于等待中,请检查ECS地域是否与Project相同。
如需将已安装LoongCollector的服务器加入已有机器组,请参考常见问题如何将服务器加入到已有机器组?
检查心跳状态:单击下一步,如页面出现机器组心跳情况。查看心跳状态,若为OK表示机器组连接正常,单击下一步,进入Logtail配置页面。
若为FAIL,可能是初次建立心跳需要花费一些时间,请等待两分钟左右,再刷新心跳状态。若刷新后仍为FAIL,请参考机器组心跳连接为fail进一步排查。
步骤二:创建并配置一次性文件采集规则
完成LoongCollector安装和机器组配置后,进入Logtail配置页面,定义日志采集和处理规则。
1. 全局与输入配置
定义采集配置的名称及日志采集的来源和范围。
全局配置:
配置名称:自定义采集配置名称,在其所属Project内必须唯一。创建成功后,无法修改。命名规则:
仅支持小写字母、数字、连字符(-)和下划线(_)。
必须以小写字母或者数字作为开头和结尾。
执行超时时间:默认是600s(10分钟),范围600-604800 秒(10 分钟~7天),单位为秒。若未能在此时间内完成采集,任务会强制停止,不再继续采集未完成部分。
重要配置下发需注意:更新后配置有效期会重置,需确认机器组范围准确,且上次任务执行时间未超过执行超时时间,避免重复下发或非预期数据上报。
更新时强制重新运行任务:默认为关闭。
关闭:
更新执行超时时间或输入配置之外的采集配置参数时,系统将延续当前的采集进度,不会从头执行采集任务,保持采集的连续性。
若修改执行超时时间或输入配置,系统会重新执行采集任务。
开启:更新采集配置时强制重新执行采集任务,确保所有数据的处理与上报符合最新改动的要求。注意:更新前已经采集的部分数据不会消失,如需清理请参考日志服务软删除)。
输入配置:
类型:一次性文件采集(3.3及以上版本LoongCollector可用)。
文件路径:日志采集的路径。
说明一次性采集的文件列表以及每个文件的大小以LoongCollector拉取到配置时的状态为准,后续新增的文件或文件有追加写的情况均不会采集。
Linux:以“/”开头,如
/data/mylogs/**/*.log,表示/data/mylogs目录下所有后缀名为.Log的文件。Windows:以盘符开头,如
C:\Program Files\Intel\**\*.Log。
最大目录监控深度:文件路径中通配符
**匹配的最大目录深度。默认为0,表示只监控本层目录。
2. 日志处理与结构化
通过配置日志处理规则,将原始非结构化日志转换为结构化、可检索的数据,提升日志查询与分析效率。建议在配置前先添加日志样例:
在Logtail配置页面的处理配置区域,单击添加日志样例,输入待采集的日志内容。系统将基于样例识别日志格式,辅助生成正则表达式和解析规则,降低配置难度。
场景一:多行日志处理(如Java堆栈日志)
由于Java异常堆栈、JSON等日志通常跨越多行,在默认采集模式下会被拆分为多条不完整的记录,导致上下文信息丢失;为此,可启用多行模式,通过配置行首正则表达式,将同一日志的连续多行内容合并为一条完整日志。
效果示例:
未经任何处理的原始日志 | 默认采集模式下,每行作为独立日志,堆栈信息被拆散,丢失上下文 | 开启多行模式,通过行首正则表达式识别完整日志,保留完整语义结构。 |
| 查询结果中每条日志均携带重复元数据(IP | 日志服务控制台中,一条包含 |
配置步骤:在Logtail配置页面的处理配置区域,开启多行模式:
类型:选择自定义或多行JSON。
自定义:原始日志的格式不固定,需配置行首正则表达式,来标识每条日志的起始行。
行首正则表达式:支持自动生成或手动输入,正则表达式需要能够匹配完整的一行数据,如上述示例中匹配的正则表达式为
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*。自动生成:单击自动生成正则表达式,然后在日志样例文本框中,选择需提取的日志内容,单击生成正则。
手动输入:单击手动输入正则表达式,输入完成后,单击验证。
多行JSON:当原始日志均为标准JSON格式时,日志服务会自动处理单条JSON日志内部的换行。
切分失败处理方式:
丢弃:如果一段文本无法匹配行首规则,则直接丢弃。
保留单行:将无法匹配的文本按原始的单行模式进行切分和保留。
场景二:结构化日志
当原始日志为非结构化或半结构化文本(如 Nginx 访问日志、应用输出日志)时,直接进行查询和分析往往效率低下。日志服务提供多种数据解析插件,能够自动将不同格式的原始日志转换为结构化数据,为后续的分析、监控和告警提供坚实的数据基础。
效果示例:
未经任何处理的原始日志 | 结构化解析后的日志 |
| |
配置步骤:在Logtail配置页面的处理配置区域
添加解析插件:单击添加处理插件,根据实际格式配置正则解析、分隔符解析、JSON 解析等插件。此处以采集NGINX日志为例,选择。
NGINX日志配置:将 Nginx 服务器配置文件(nginx.conf)中的
log_format定义完整地复制并粘贴到此文本框中。示例:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';重要此处的格式定义必须与服务器上生成日志的格式完全一致,否则将导致日志解析失败。
通用配置参数说明:以下参数在多种数据解析插件中都会出现,其功能和用法是统一的。
原始字段:指定要解析的源字段名。默认为
content,即采集到的整条日志内容。解析失败时保留原始字段:推荐开启。当日志无法被插件成功解析时(例如格式不匹配),此选项能确保原始日志内容不会丢失,而是被完整保留在指定的原始字段中。
解析成功时保留原始字段:选中后,即使日志解析成功,原始日志内容也会被保留。
3. 日志过滤
在日志采集过程中,大量低价值或无关日志(如 DEBUG/INFO 级别日志)的无差别收集,不仅造成存储资源浪费、增加成本,还影响查询效率并带来数据泄露风险。为此,可通过精细化过滤策略实现高效、安全的日志采集。
通过内容过滤降低成本
基于日志内容的字段过滤(如仅采集 level 为 WARNING 或 ERROR 的日志)。
效果示例:
未经任何处理的原始日志 | 只采集 |
| |
配置步骤:在Logtail配置页面的处理配置区域
单击添加处理插件,选择:
字段名:过滤的日志字段。
字段值:用于过滤的正则表达式,仅支持全文匹配,不支持关键词部分匹配。
通过黑名单控制采集范围
通过黑名单机制排除指定目录或文件,避免无关或敏感日志被上传。
配置步骤:在Logtail配置页面的区域,启用采集黑名单,并单击添加。
支持完整匹配和通配符匹配目录和文件名,通配符只支持星号(*)和半角问号(?)。
文件路径黑名单:需要忽略的文件路径,示例:
/home/admin/private*.log:在采集时忽略/home/admin/目录下所有以private开头,以.log结尾的文件。/home/admin/private*/*_inner.log:在采集时忽略/home/admin/目录下以private开头的目录内,以_inner.log结尾的文件。
文件黑名单:配置采集时需要忽略的文件名,示例:
app_inner.log:在采集时忽略所有名为app_inner.log的文件。
目录黑名单:目录路径不能以正斜线(/)结尾,示例:
/home/admin/dir1/:目录黑名单不会生效。/home/admin/dir*:在采集时忽略/home/admin/目录下所有以dir开头的子目录下的文件。/home/admin/*/dir:在采集时忽略/home/admin/目录下二级目录名为dir的子目录下的所有文件。例如/home/admin/a/dir目录下的文件被忽略,/home/admin/a/b/dir目录下的文件被采集。
4. 日志分类
当多个应用或实例的日志格式相同但路径不同时(如 /apps/app-A/run.log 和 /apps/app-B/run.log),采集日志难以区分来源。通过配置日志主题(Topic),对来自不同应用、服务或路径的日志进行逻辑区分,实现统一存储下的高效归类与精准查询。
配置步骤::选择Topic生成方式,支持如下三种类型:
机器组Topic:采集配置应用于多个机器组时,LoongCollector 会自动使用服务器所属的机器组名称作为
__topic__字段上传。适用于按主机划分日志场景。自定义:格式为
customized://<自定义主题名>,例如customized://app-login。适用于固定业务标识的静态主题场景。文件路径提取:从日志文件的完整路径中提取关键信息,动态标记日志来源。适用于多用户/应用共用相同日志文件名但路径不同的情况。当多个用户或服务将日志写入不同顶级目录,但下级路径和文件名一致时,仅靠文件名无法区分来源,例如:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.log此时您可以配置文件路径提取,并使用正则表达式从完整路径中提取关键信息,将匹配结果作为日志主题(Topic)上传至LogStore。
文件路径提取规则:基于正则表达式的捕获组
在配置正则表达式时,系统根据捕获组的数量和命名方式自动决定输出字段格式,规则如下:
文件路径的正则表达式中,需要对正斜线(/)进行转义。
捕获组类型
适用场景
生成字段
正则示例
匹配路径示例
生成字段示例
单捕获组(仅一个
(.*?))仅需一个维度区分来源(如用户名、环境)
生成
__topic__字段\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__:userA多捕获组-非命名(多个
(.*?))需要多个维度区分来源但无需语义标签
生成tag字段
__tag__:__topic_{i}__,其中{i}为捕获组的序号\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__userA;__tag__:__topic_2__svcA多捕获组-命名(使用
(?P<name>.*?)需要多个维度区分来源且希望字段含义清晰、便于查询与分析
生成tag字段
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
步骤三:查询与分析配置
在完成日志处理与插件配置后,单击下一步,进入查询分析配置页面:
配置完成后,单击下一步,完成整个采集流程的设置。
步骤四:验证采集结果
配置生效后,在目标LogStore的查询分析页面,单击查询 / 分析,查看采集到的日志数据。
常见问题
一次性采集配置的生命周期
一次性采集配置创建后,具有以下生命周期特性:

配置下发有效期:配置创建后5分钟内,LoongCollector 可以拉取到该配置。超过5分钟后,新的 LoongCollector 实例无法获取该配置。
配置自动删除:配置创建7天后自动删除。
任务执行:在执行超时时间内完成采集,超时后任务强制停止。
一次性文件采集相较于以往的历史文件采集,有什么区别?
旧版历史文件采集方式不再推荐使用,请优先选择新版功能进行历史数据导入。相较于旧版手动创建配置文件的采集方式,新版一次性文件采集在配置效率、可靠性和可观测性上均有显著提升。具体对比如下:
对比项 | 旧版历史文件采集 | 新版一次性文件采集 |
配置方式 | 主机上创建local_event.json文件,需要一台一台操作 | 控制台/api创建配置,机器组级别批量下发。 |
文件匹配 | 需要手动填写文件路径、文件名 | 类input_file方式快捷配置,支持黑名单过滤。 |
进度监控 | 无状态上报、无本地日志 | 有checkpoint,粒度精细至每个文件当前采集到的offset位置。 |
可靠性 | 低,单独流程,无资源控制,无checkpoint | 高,标准的Pipeline级别资源管控,支持流控,不影响其他采集,支持断点续传。 |
灵活性 | 低,需要使用已有的采集配置 | 高,自行编排采集配置,还支持中途修改 |
机器组心跳连接为fail
检查用户标识:如果您的服务器类型不是ECS,或ECS和Project属于不同阿里云账号,请检查指定目录下是否存在正确的用户标识,如不存在请参考如下命令手动创建。
Linux:执行
cd /etc/ilogtail/users/ && touch <uid>命令,创建用户标识文件。Windows:进入
C:\LogtailData\users\目录,创建一个名为<uid>的空文件。
检查机器组标识:如果您在创建机器组时使用了用户自定义标识,请检查指定目录下是否存在
user_defined_id文件,如果存在请检查该文件中的内容是否与机器组配置的自定义标识一致。Linux:
# 配置用户自定义标识,如目录不存在请手动创建 echo "user-defined-1" > /etc/ilogtail/user_defined_idWindows:在
C:\LogtailData目录下新建user_defined_id文件,并写入用户自定义标识。(如目录不存在,请手动创建)
如果用户标识和机器组标识均配置无误,请参考LoongCollector(Logtail)机器组问题排查思路进一步排查。
如何将服务器加入到已有机器组?
当您已有配置好的机器组,希望将新的服务器(如新部署的 ECS 或自建服务器)加入其中并继承其采集配置时,可通过以下步骤完成绑定。
配置创建5分钟后,新加入机器组中的机器不会接收采集配置,具体时间可以参考采集配置页面上方的倒计时提示。
操作前提:
已存在一个配置完成的机器组。
新服务器已安装LoongCollector。
操作步骤:
查看目标机器组标识:
在目标Project页面,单击左侧导航栏
 。
。进入机器组页面,单击目标机器组名称。
在机器组配置页面,查看机器组标识。
根据标识类型执行对应操作:
说明同一机器组中不允许同时存在Linux服务器、Windows服务器,请勿在Linux和Windows服务器上配置相同的用户自定义标识。一个服务器可配置多个用户自定义标识,标识之间以换行符分隔。
类型一:机器组标识为IP地址
在服务器上,执行如下命令打开
app_info.json文件,查看ip值。cat /usr/local/ilogtail/app_info.json在目标机器组配置页面,单击修改,填写服务器的IP地址,多个IP之间使用换行符分隔。
配置完成后,单击保存,并确认心跳状态。心跳为OK后,服务器将自动应用机器组的采集配置。
若心跳状态为FAIL,请参考常见问题机器组心跳连接为fail进一步排查。
类型二:机器组标识为用户自定义标识
根据操作系统,向指定文件写入与目标机器组一致的用户自定义标识字符串:
若目录不存在需手动创建。文件路径和名称由日志服务固定,不可自定义。
Linux:向
/etc/ilogtail/user_defined_id文件写入自定义字符串 。Windows:向
C:\LogtailData\user_defined_id写入自定义字符串。
附录:原生解析插件详解
正则解析
通过正则表达式提取日志字段,并将日志解析为键值对形式,每个字段都可以被独立查询和分析。
效果示例:
|
未经任何处理的原始日志 |
使用正则解析插件 |
|
|
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
-
正则表达式:用于匹配日志,支持自动生成或手动输入:
-
自动生成:
-
单击自动生成正则表达式。
-
在日志样例中划选需要提取的日志内容。
-
单击生成正则。

-
-
手动输入:根据日志格式手动输入正则表达式。
配置完成后,单击验证,测试正则表达式是否能够正确解析日志内容。
-
-
日志提取字段:为提取的日志内容(Value),设置对应的字段名(Key)。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
分隔符解析
通过分隔符将日志内容结构化,解析为多个键值对形式,支持单字符分隔符和多字符分隔符。
效果示例:
|
未经任何处理的原始日志 |
按指定字符 |
|
|
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
-
分隔符:指定用于切分日志内容的字符。
示例:对于CSV格式文件,选择自定义,输入半角逗号(,)。
-
引用符:当某个字段值中包含分隔符时,需要指定引用符包裹该字段,避免错误切割。
-
日志提取字段:按分隔顺序依次为每一列设置对应的字段名称(Key)。规则要求如下:
-
字段名只能包含:字母、数字、下划线(_)。
-
必须以字母或下划线(_)开头。
-
最大长度:128字节。
-
其他参数请参考场景二:结构化日志中的通用配置参数说明。
标准JSON解析
将Object类型的JSON日志结构化,解析为键值对形式。
效果示例:
|
未经任何处理的原始日志 |
标准JSON键值自动提取 |
|
|
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
-
原始字段:默认值为content(此字段用于存放待解析的原始日志内容)。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
嵌套JSON解析
通过指定展开深度,将嵌套的JSON日志解析为键值对形式。
效果示例:
|
未经任何处理的原始日志 |
展开深度:0,并使用展开深度作为前缀 |
展开深度:1,并使用展开深度作为前缀 |
|
|
|
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
-
原始字段:需要展开的原始字段名,例如
content。 -
JSON展开深度:JSON对象的展开层级。0表示完全展开(默认值),1表示当前层级,以此类推。
-
JSON展开连接符:JSON展开时字段名的连接符,默认为下划线 _。
-
JSON展开字段前缀:指定JSON展开后字段名的前缀。
-
展开数组:开启此项可将数组展开为带索引的键值对。
示例:
{"k":["a","b"]}展开为{"k[0]":"a","k[1]":"b"}。如果需要对展开后的字段进行重命名(例如,将 prefix_s_key_k1 改为 new_field_name),可以后续再添加一个重命名字段插件来完成映射。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
JSON数组解析
使用json_extract函数,从JSON数组中提取JSON对象。
效果示例:
|
未经任何处理的原始日志 |
提取JSON数组结构 |
|
|
配置步骤:在Logtail配置页面的处理配置区域,将处理模式切换为SPL,配置SPL语句,使用 json_extract函数从JSON数组中提取JSON对象。
示例:从日志字段 content 中提取 JSON 数组中的元素,并将结果分别存储在新字段 json1和 json2 中。
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Apache日志解析
根据Apache日志配置文件中的定义将日志内容结构化,解析为多个键值对形式。
效果示例:
|
未经任何处理的原始日志 |
Apache通用日志格式 |
|
|
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
-
日志格式:combined。
-
APACHE配置字段:系统会根据日志格式自动填充配置。
重要请务必核对自动填充的内容,确保与服务器上 Apache 配置文件(通常位于/etc/apache2/apache2.conf)中定义的 LogFormat 完全一致。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
IIS日志解析
根据IIS日志格式定义将日志内容结构化,解析为多个键值对形式。
对比示例:
|
原始日志 |
微软IIS服务器专用格式适配 |
|
|
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
-
日志格式:选择您的IIS服务器日志采用的日志格式。
-
IIS:Microsoft IIS日志文件格式。
-
NCSA:NCSA公用日志文件格式。
-
W3C:W3C扩展日志文件格式。
-
-
IIS配置字段:选择IIS或NCSA时,日志服务已默认设置了IIS配置字段,选择W3C时,设置为您的IIS配置文件中
logExtFileFlags参数中的内容。例如:logExtFileFlags="Date, Time, ClientIP, UserName, SiteName, ComputerName, ServerIP, Method, UriStem, UriQuery, HttpStatus, Win32Status, BytesSent, BytesRecv, TimeTaken, ServerPort, UserAgent, Cookie, Referer, ProtocolVersion, Host, HttpSubStatus"
其他参数请参考场景二:结构化日志中的通用配置参数说明。
数据脱敏
对日志中的敏感数据进行脱敏处理。
效果示例:
|
未经任何处理的原始日志 |
脱敏结果 |
|
|
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
时间解析
对日志中的时间字段进行解析,并将解析结果设置为日志的__time__字段。
效果示例:
|
未经任何处理的原始日志 |
时间解析 |
|
|
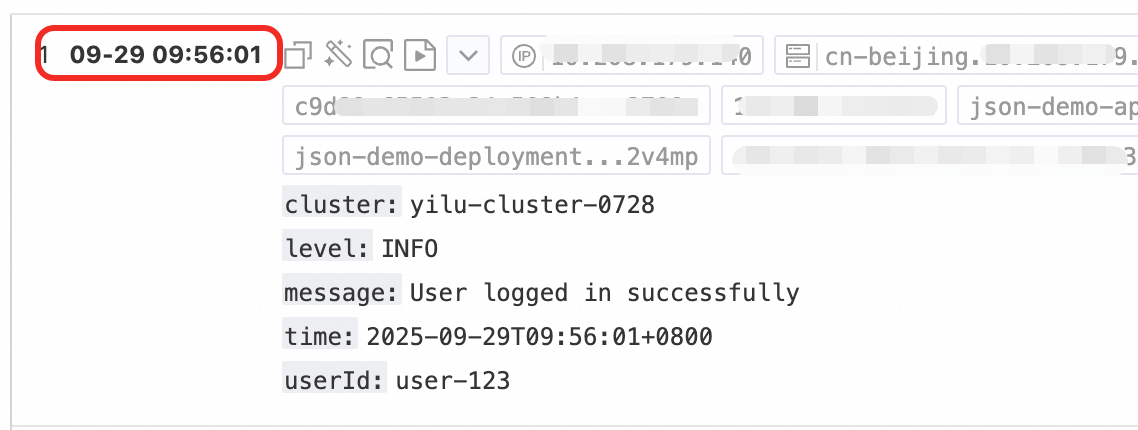
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
-
原始字段:解析日志前,用于存放日志内容的原始字段。
-
时间格式:根据日志中的时间内容设置对应的时间格式。
-
时区:选择日志时间字段所在的时区。默认使用机器时区,即LoongCollector(Logtail)进程所在环境的时区。