知识库用于为大模型补充私有数据和最新信息。基于 RAG(检索增强生成)技术,大模型在生成回答前会先从知识库中检索相关内容,从而提升回答的准确性。
|
无专属知识库的应用 无专属知识库时,大模型无法准确回答特定领域的问题。
|
有专属知识库的应用 引入专属知识库后,大模型可准确回答特定领域的问题。
|


支持的模型
以下模型支持使用知识库。配置千问使用知识库教程
-
千问-Max/Plus/Turbo
-
千问VL-Max/Plus
-
千问-开源版(Qwen2.5等)
上述列表随时可能更新。请以在 应用管理 页面创建应用时实际可选的模型为准。
快速开始
本节介绍如何无需编写代码,快速构建一个能够回答特定领域问题(以"阿里云百炼手机"为例)的大模型问答应用。
1. 构建知识库
-
进入知识库页面,点击创建知识库。填写知识库名称和知识库描述,其余设置保持默认,点击下一步。
-
选择默认类目,上传阿里云百炼系列手机产品介绍.docx文件。点击下一步,然后点击完成。
2. 集成到业务应用
知识库创建后,可将其关联至同一业务空间下的阿里云百炼应用或外部应用,以处理检索请求。
集成到智能体应用
-
进入应用管理页面,找到目标智能体应用,点击卡片上的配置,并为应用选择模型。
-
点击页面上文档知识库右侧的 + 按钮,添加上一步创建的知识库。相似度阈值和权重可保持默认。
-
在页面右侧的输入框中输入问题,大模型将基于所构建的知识库进行回答。
例如:"请帮我挑选一款拍照效果最好的阿里云百炼手机,价格在3000元以内。"
集成到工作流应用
-
进入应用管理页面,找到目标工作流应用,点击卡片上的配置。将知识库节点拖入画布,连接在开始节点之后。
-
配置知识库节点:
-
输入:在变量名
content右侧的值下拉列表中,选择。下拉列表为树形结构,需展开"内置变量"分组后选择 query。 -
选择知识库:知识库节点支持以下两种选择方式。
-
选择固定知识库:从下拉菜单中选择上一步创建的知识库。适用于每次调用同一知识库的场景。
-
动态引入:配置
CodeList变量,根据上游节点的输出动态指定知识库。适用于需根据不同输入检索不同知识库的场景。
-
-
设置 TopK(可选):决定返回给下游节点(通常为大模型节点)的知识片段数量。
增大该值通常能提升大模型回答的准确性,但会相应增加大模型的输入 Token 消耗。
-
-
将大模型节点拖入画布,连接在知识库节点之后、结束节点之前。
-
配置大模型节点:
-
在模型配置列表中,为节点选择模型。
-
在提示词中,输入指示大模型使用知识库的提示词。输入"/"可插入
result变量(表示知识库检索返回的结果)。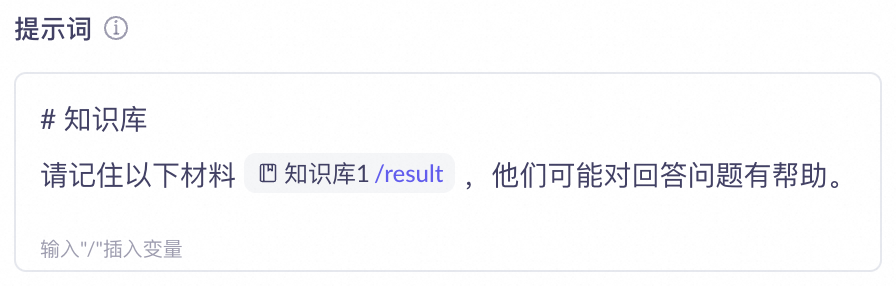
-
-
配置结束节点:输入
/,选择,输出大模型返回的结果。 -
点击页面右上角的测试,在页面右侧的输入框中输入问题,大模型将基于所构建的知识库进行回答。
例如:"请帮我挑选一款拍照效果最好的阿里云百炼手机,价格在3000元以内。"
集成到外部应用
除在阿里云百炼内构建应用外,也可通过阿里云百炼SDK调用知识库的检索能力,为外部 AI 应用提供检索服务。
具体集成步骤,请参见知识库API指南。
3. 优化知识库效果(可选)
若问答过程中出现知识召回不完整或内容不准确的情况,请参见知识库效果优化。
操作指南
知识库ID: 即每个知识库卡片上 ID 字段的值,用于API调用等场景。
创建知识库
点击创建知识库后,按三步完成创建:填写基础信息并选择知识库类型、配置数据来源、设置索引参数。
-
在知识库页面,点击创建知识库。
-
填写基础信息
根据应用场景选择合适的知识库类型(单一知识库不支持同时选择多个类型)。选择文档搜索类型后,还需选择使用场景(基础文档问答、图文并茂回复):
-
基础文档问答:适用于纯文本文档的语义检索。
-
图文并茂回复:适用于需要返回图文混排内容的场景。
创建后,知识库类型不可更改。
-
文档搜索(检索场景)
-
适用场景:
-
适用于企业内部文档、产品手册等非结构化数据(即未按预定义表结构组织的数据,包含文本、表格和图片)的检索。
-
若文件包含图片,且需阿里云百炼应用在回答中返回,请选择文档搜索。
-
-
数据来源:支持本地上传文件或从阿里云对象存储OSS导入。
-
选择数据:为知识库指定数据来源(文件或内容)。数据源内容将导入知识库,用于后续检索。支持本地上传和云端导入(选择现有类目或文件)两种方式。
-
本地上传:直接从本地电脑上传文件。展开下方折叠面板了解如何选择解析方式。
-
云端导入:从对象存储OSS导入已有文件。
-
-
索引配置:定义导入数据的处理和存储方式,直接影响检索效果。
以下配置项中,仅"向量存储"选用 ADB-PG 时可能产生费用,其余配置均免费。
Meta信息抽取
metadata(元数据)是与非结构化数据关联的一组附加属性,以 key-value 键值对的形式集成到文本切片中。
-
作用:元数据为文本切片提供重要的上下文信息,可显著提升知识库检索的准确性。例如,知识库中包含上千个以产品名称命名的产品介绍文件。检索"A产品的功能概述"时,若所有文件正文都含有"功能概述"但均未提及"A产品",知识库可能召回大量无关文本切片。将产品名称作为元数据附加到所有文本切片后,知识库可精准过滤出与"A产品"相关且包含"功能概述"的切片,从而提高检索准确性,同时降低模型输入Token消耗。
-
用法:通过API调用应用时,可在请求参数
metadata_filter中指定metadata。应用检索知识库时,将先根据metadata筛选相关文件。 -
注意:知识库一旦创建,无法再配置metadata抽取。
开启Meta信息抽取,然后单击设置为该知识库中的所有文件附加统一或个性化的元数据。切分时,每个文件的元数据将集成到各自的文本切片中。下图为上方示例使用的meta信息模板:
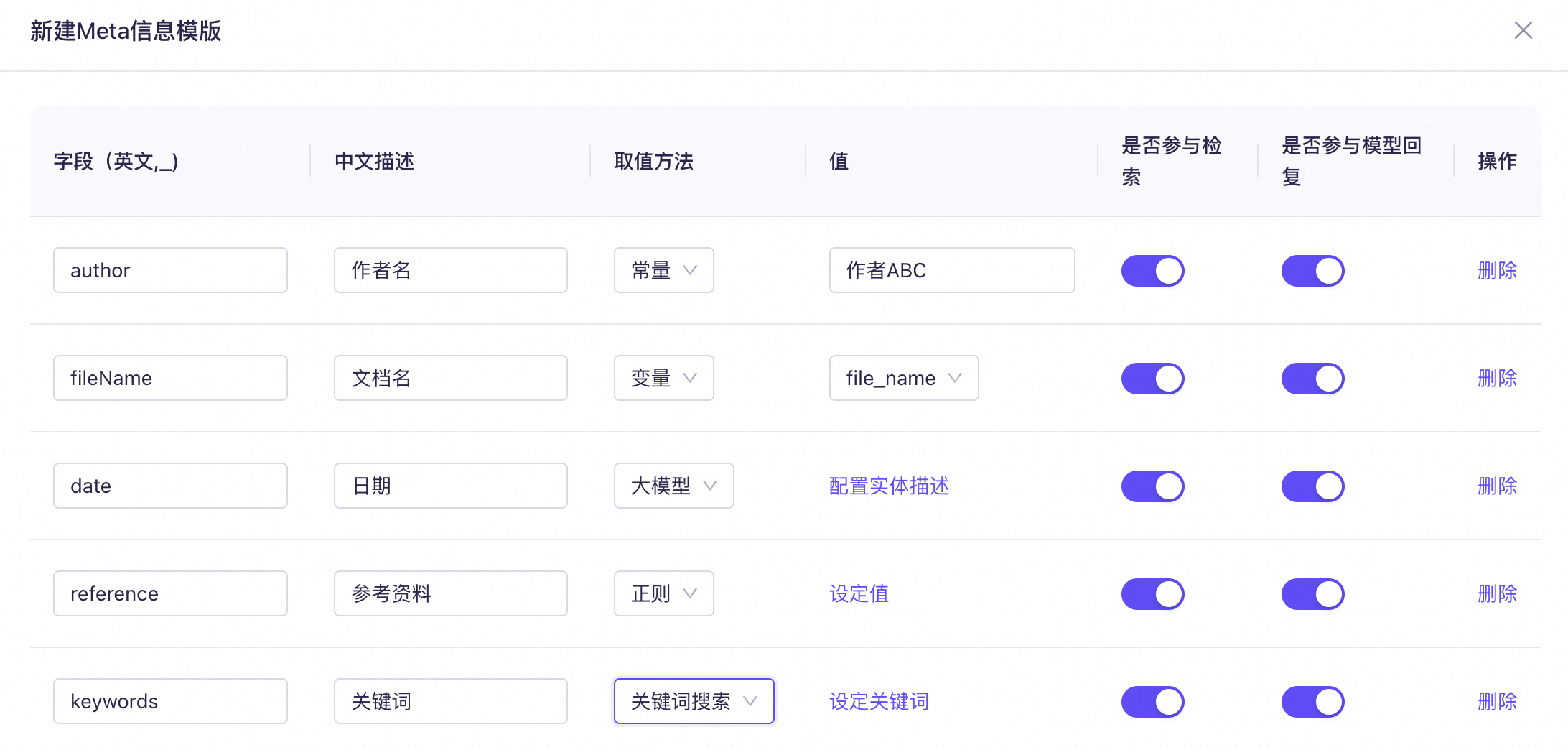
取值方法说明:
-
常量:为知识库中的所有文件附加固定属性。
如上方示例所示,若知识库中所有文件的作者相同,可统一设置字段名为
author的常量。 -
变量:为知识库中的每个文件附加可变属性。目前支持
file_name和cat_name。选择file_name时,阿里云百炼将文件名称附加到其元数据中,如上方示例所示。选择cat_name时,阿里云百炼将文件所在类目的名称附加到文件元数据中。 -
大模型:系统依据设定的实体描述规则,对知识库中每个文件的文本内容进行匹配,自动识别并提取相关信息,将其作为属性附加到文件元数据中。
如上方示例的meta信息模板所示,如需提取每个文件中所有出现过的年份信息作为文件属性,可设置名为
date的大模型字段,实体描述配置如下:
-
正则:系统依据设置的正则表达式,对知识库中每个文件的文本内容进行匹配,提取符合该表达式的内容,并将其作为属性添加到文件元数据中。
如上方示例的meta信息模板所示,如需提取每个文件中所有出现过的参考资料(假设规律为:以"《"开头、以"》"结尾),可设置名为
reference的正则字段,正则表达式配置如下:
-
关键词搜索:系统在每个文件中查找预设的关键词,并将匹配到的关键词作为属性添加至文件元数据中。
例如,在上述示例的meta信息模板中,预设的关键词为:

由于该文件中仅出现了"融资、产业、绿色、资本"这四个关键词,系统只提取了这四个关键词作为该文件
keywords属性的值。
是否参与检索:开启后,元数据字段和值将与文本切片内容一同参与知识库检索;关闭时,仅文本切片内容参与检索,元数据字段和值不参与。
是否参与模型回复:开启后,元数据字段和值将与文本切片内容一同参与大模型的回答生成;关闭时,仅文本切片内容参与大模型回答生成,元数据字段和值不参与。
Excel文件表头拼装
开启后,知识库将所有XLSX、XLS格式文件的首行数据视为表头,并自动拼接到每个文本切片(数据行)中,避免大模型将表头误识别为普通数据行。
若知识库中包含其他格式的文件(如PDF),无需开启该设置。
切片方式
选择智能切分(推荐)。
作用: 知识库将文件切分为文本切片,并通过向量模型转换为向量。文本切片和向量以键值对的形式存入向量数据库。知识库创建后,可查看或编辑每个文本切片的具体内容(文字和图片)。
注意: 知识库一旦创建, 无法再更改文档切分chunk 。不合适的切分策略可能会降低检索和召回效果。
多轮对话改写
开启该功能后,系统将调用专用轻量级模型,结合对话历史将用户当前问题改写为独立的、上下文完整的新查询,再用于知识库检索。
向量模型
向量模型用于将原始输入Prompt和知识文本转化为数值向量,以便计算语义相似度。默认的官方向量(text-embedding-v2)除支持中英双语外,还支持多种语言,并对向量结果进行归一化处理(暂不支持更改)。
知识库使用的向量维度(无法修改):
-
官方向量(text-embedding-v2):1,536维
-
qwen3 多模态向量(qwen3-vl-embedding):使用场景选择「视觉理解」时自动启用,支持对图片和富文本文档进行视觉理解后生成向量
排序模型
排序模型位于知识库外部,对向量检索初步召回的候选切片进行二次排序,并返回相似度分数最高的前K个文本切片。qwen3-rerank(hybrid)官方排序(推荐)综合考量语义相关性与文本匹配特征(如BM25得分),能更好地处理需要精确关键词命中的查询;若只需语义排序,请选择qwen3-rerank。
排序模型模式
在创建知识库时,可以在「排序模型模式」配置项中选择以下三种模式之一:
-
问答模式(默认):根据查询与候选切片的"问答匹配度"评分,适合用户提出完整问题、期望从切片中找到答案的场景。
-
相似模式:根据查询与候选切片的"语义相似度"评分,适合查询与切片表述风格相近的场景。
-
自定义高级模式:填写一段不超过 200 个字符的自然语言指令来干预重排序过程,适合有特殊排序需求的场景。
警告排序模型模式仅在创建知识库时可选,创建完成后无法修改。配置前请确认以下限制:
-
知识库类型限制:仅适用于文档搜索类、数据查询类、音视频搜索类知识库。图片问答类知识库不支持。
-
使用场景限制:仅「基础文档问答」和「图文并茂回复」两种使用场景支持。「视觉理解(富文本文档)」和「极速问答」不支持。
相似度阈值
该阈值表示允许召回的文本切片的最低相似度分数,用于筛选排序模型返回的结果,只有分数超过此阈值的文本切片才会被召回。
说明此处设置的是知识库的默认相似度阈值。将知识库关联到具体阿里云百炼应用时,还可为该应用单独设置阈值(将覆盖知识库的默认相似度阈值)。
降低此阈值预期会召回更多文本切片,但可能召回相关度较低的内容;提高此阈值会减少召回的文本切片数量,若设置过高,将导致知识库丢弃相关切片。
可通过命中测试对相似度阈值进行调优,以平衡召回率与精确率。
最大召回数量
假设阿里云百炼应用关联了A1、A2和A3三个知识库,系统从这些库中检索与输入相关的切片,再通过排序模型重排序,选出最相关的前K条加入大模型的输入Token供回答参考。此K值即最大召回数量(上限为20),决定了排序模型提供给大模型参考的文本切片数量。
增大该值可提高大模型的回答准确性,但会相应增加大模型输入Token消耗。
向量存储
选择向量数据库存储文本向量。内置的向量数据库可满足知识库的基本功能需求。如需管理、审计或监控数据库等高级功能,建议选择ADB-PG(AnalyticDB for PostgreSQL)。
购买ADB-PG实例时请开启 向量引擎优化 ,否则阿里云百炼将无法使用此实例。
-
-
-
-
数据查询(Chatbot 或 NL2SQL 场景)
-
适用场景:
-
适合构建基于结构化数据(按预定义表结构组织的数据)的问答系统,例如 FAQ、商品数据、人员信息查询助手等。
-
若数据为完整的 FAQ 问答对,请选择数据查询。例如,Excel 文件包含两列,分别为
问题和答案。数据查询类知识库支持将问题列用于知识库检索,答案列用于大模型回答参考。文档搜索类知识库无法实现此效果。
-
支持导入多个Excel文件,但要求各文件的表结构完全一致。
-
-
数据源接入:支持本地上传 XLS 或 XLSX 文件。
-
选择数据:为知识库指定数据来源(含文件或内容)。数据源内容将导入知识库,用于后续检索。支持本地上传、云端导入两种方式。
说明知识库创建后数据源不可更改,且单个知识库不支持同时使用多个数据源。
-
本地上传:从本地计算机上传数据表(XLS 或 XLSX 格式,首行必须为表头)。
-
云端导入(选择数据表):选择阿里云百炼的现有数据表。
-
-
索引配置:定义导入数据的处理和存储方式,直接影响检索效果。
以下配置项中,仅"向量存储"选用 ADB-PG 时可能产生费用,其余配置均免费。
是否参与检索/参与模型回复
-
是否参与检索:开启后,知识库将在该列数据中执行检索。
-
是否参与模型回复:开启后,该列的检索结果将作为大模型生成回答的输入信息。示例配置:对"姓名"、"性别"、"岗位"、"年龄"列开启是否参与检索,仅对"姓名"和"岗位"列开启是否参与模型回复后,知识库将在所有列中执行检索,但仅将"姓名"和"岗位"两列的检索结果提供给大模型作为回答依据。
如下图所示,由于"年龄"列未开启参与模型回复,关联该知识库的大模型仍无法回答"张三的年龄"。
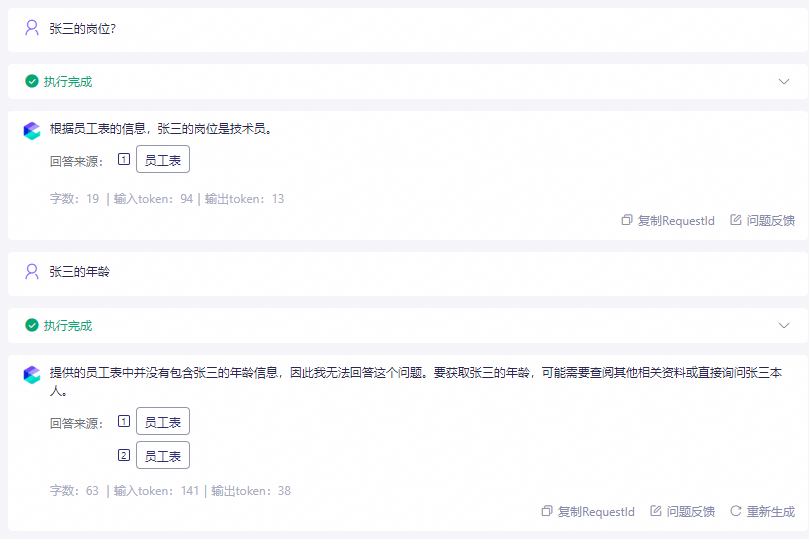
多轮对话改写
开启该功能后,系统将调用专用轻量级模型,结合对话历史将用户当前问题改写为独立的、上下文完整的新查询,再用于知识库检索。
向量模型
向量模型用于将原始输入Prompt和知识文本转化为数值向量,以便计算语义相似度。默认的官方向量(text-embedding-v2)除支持中英双语外,还支持多种语言,并对向量结果进行归一化处理(暂不支持更改)。
知识库使用的向量维度(无法修改):
-
官方向量(text-embedding-v2):1,536维
-
qwen3 多模态向量(qwen3-vl-embedding):使用场景选择「视觉理解」时自动启用,支持对图片和富文本文档进行视觉理解后生成向量
排序模型
排序模型位于知识库外部,对向量检索初步召回的候选切片进行二次排序,并返回相似度分数最高的前K个文本切片。qwen3-rerank(hybrid)官方排序(推荐)综合考量语义相关性与文本匹配特征(如BM25得分),能更好地处理需要精确关键词命中的查询;若只需语义排序,请选择qwen3-rerank。
排序模型模式
在创建知识库时,可以在「排序模型模式」配置项中选择以下三种模式之一:
-
问答模式(默认):根据查询与候选切片的"问答匹配度"评分,适合用户提出完整问题、期望从切片中找到答案的场景。
-
相似模式:根据查询与候选切片的"语义相似度"评分,适合查询与切片表述风格相近的场景。
-
自定义高级模式:填写一段不超过 200 个字符的自然语言指令来干预重排序过程,适合有特殊排序需求的场景。
警告排序模型模式仅在创建知识库时可选,创建完成后无法修改。配置前请确认以下限制:
-
知识库类型限制:仅适用于文档搜索类、数据查询类、音视频搜索类知识库。图片问答类知识库不支持。
-
使用场景限制:仅「基础文档问答」和「图文并茂回复」两种使用场景支持。「视觉理解(富文本文档)」和「极速问答」不支持。
相似度阈值
该阈值表示允许召回的文本切片的最低相似度分数,用于筛选排序模型返回的结果,只有分数超过此阈值的文本切片才会被召回。
说明此处设置的是知识库的默认相似度阈值。将知识库关联到具体阿里云百炼应用时,还可为该应用单独设置阈值(将覆盖知识库的默认相似度阈值)。
降低此阈值预期会召回更多文本切片,但可能召回相关度较低的内容;提高此阈值会减少召回的文本切片数量,若设置过高,将导致知识库丢弃相关切片。
可通过命中测试对相似度阈值进行调优,以平衡召回率与精确率。
最大召回数量
假设阿里云百炼应用关联了A1、A2和A3三个知识库,系统从这些库中检索与输入相关的切片,再通过排序模型重排序,选出最相关的前K条加入大模型的输入Token供回答参考。此K值即最大召回数量(上限为20),决定了排序模型提供给大模型参考的文本切片数量。
增大该值可提高大模型的回答准确性,但会相应增加大模型输入Token消耗。
向量存储
选择向量数据库存储文本向量。内置的向量数据库可满足知识库的基本功能需求。如需管理、审计或监控数据库等高级功能,建议选择ADB-PG(AnalyticDB for PostgreSQL)。
购买ADB-PG实例时请开启 向量引擎优化 ,否则阿里云百炼将无法使用此实例。
-
-
-
-
图片问答(图搜场景)
-
适用场景:
-
适合构建以图搜图、以图搜"图文"的多模态检索应用,如商品导购助手、视觉问答助手等。
-
-
数据源接入:支持本地上传 XLS 或 XLSX 文件。
XLS、XLSX 文件 中需包含 公开可访问 的图片 URL,以便构建图片索引。详见下方创建说明。
-
选择数据:为知识库指定数据来源(含文件或内容)。数据源内容将导入知识库,用于后续检索。支持本地上传、云端导入(选择数据连接器中已有数据表)两种方式。
说明知识库创建后数据源不可更改,且单个知识库不支持同时使用多个数据源。
-
本地上传:从本地计算机上传数据表(XLS 或 XLSX 格式)。
说明-
字段要求:数据表中至少需包含一个类型为
image_url的字段,用于生成图片索引。 -
构建过程:知识库将访问
image_url字段中的图片 URL,提取视觉特征并转换为向量存储。 -
检索过程:知识库将用户上传图片生成的向量与已存储的图片向量进行相似度比对,返回最相关的记录。
-
-
云端导入(选择数据表):选择阿里云百炼应用数据中的现有数据表。
-
-
索引配置:定义导入数据的处理和存储方式,直接影响检索效果。
以下配置项中,仅"向量存储"选用 ADB-PG 时可能产生费用,其余配置均免费。
是否参与检索/参与模型回复
-
是否参与检索:开启后,知识库将在该列数据中执行检索。
-
是否参与模型回复:开启后,该列的检索结果将作为大模型生成回答的输入信息。示例配置:对"姓名"、"性别"、"岗位"、"年龄"列开启是否参与检索,仅对"姓名"和"岗位"列开启是否参与模型回复后,知识库将在所有列中执行检索,但仅将"姓名"和"岗位"两列的检索结果提供给大模型作为回答依据。
如下图所示,由于"年龄"列未开启参与模型回复,关联该知识库的大模型仍无法回答"张三的年龄"。
多轮对话改写
开启该功能后,系统将调用专用轻量级模型,结合对话历史将用户当前问题改写为独立的、上下文完整的新查询,再用于知识库检索。
向量模型
向量模型用于将原始输入 Prompt、知识文本及图片转化为数值化向量,以便进行相似度比较。详情请参见文本与多模态向量化。
-
qwen2.5 多模态向量(qwen2.5-vl-embedding):将单模态或混合模态输入表征为统一向量,适用于跨模态检索、图搜等场景。例如,输入一张衬衫图片并附加文本"找相似风格但更显年轻的款式",模型能将图像与文本指令融合为一个向量进行理解。
-
多模态向量 v1(multimodal-embedding-v1):为每个输入部分(图片、文字)分别生成独立向量。
-
qwen3 多模态向量(qwen3-vl-embedding):qwen2.5-vl-embedding 的升级版本,在图文融合理解和跨模态检索精度方面进一步提升。
排序模型
排序模型位于知识库外部,对向量检索初步召回的候选切片进行二次排序,并返回相似度分数最高的前K个文本切片。qwen3-rerank(hybrid)官方排序(推荐)综合考量语义相关性与文本匹配特征(如BM25得分),能更好地处理需要精确关键词命中的查询;若只需语义排序,请选择qwen3-rerank。
排序模型模式
在创建知识库时,可以在「排序模型模式」配置项中选择以下三种模式之一:
-
问答模式(默认):根据查询与候选切片的"问答匹配度"评分,适合用户提出完整问题、期望从切片中找到答案的场景。
-
相似模式:根据查询与候选切片的"语义相似度"评分,适合查询与切片表述风格相近的场景。
-
自定义高级模式:填写一段不超过 200 个字符的自然语言指令来干预重排序过程,适合有特殊排序需求的场景。
警告排序模型模式仅在创建知识库时可选,创建完成后无法修改。配置前请确认以下限制:
-
知识库类型限制:仅适用于文档搜索类、数据查询类、音视频搜索类知识库。图片问答类知识库不支持。
-
使用场景限制:仅「基础文档问答」和「图文并茂回复」两种使用场景支持。「视觉理解(富文本文档)」和「极速问答」不支持。
相似度阈值
该阈值表示允许召回的文本切片的最低相似度分数,用于筛选排序模型返回的结果,只有分数超过此阈值的文本切片才会被召回。
说明此处设置的是知识库的默认相似度阈值。将知识库关联到具体阿里云百炼应用时,还可为该应用单独设置阈值(将覆盖知识库的默认相似度阈值)。
降低此阈值预期会召回更多文本切片,但可能召回相关度较低的内容;提高此阈值会减少召回的文本切片数量,若设置过高,将导致知识库丢弃相关切片。
可通过命中测试对相似度阈值进行调优,以平衡召回率与精确率。
最大召回数量
假设阿里云百炼应用关联了A1、A2和A3三个知识库,系统从这些库中检索与输入相关的切片,再通过排序模型重排序,选出最相关的前K条加入大模型的输入Token供回答参考。此K值即最大召回数量(上限为20),决定了排序模型提供给大模型参考的文本切片数量。
增大该值可提高大模型的回答准确性,但会相应增加大模型输入Token消耗。
向量存储
选择向量数据库存储文本向量。内置的向量数据库可满足知识库的基本功能需求。如需管理、审计或监控数据库等高级功能,建议选择ADB-PG(AnalyticDB for PostgreSQL)。
购买ADB-PG实例时请开启 向量引擎优化 ,否则阿里云百炼将无法使用此实例。
-
-
-
使用场景可根据需求选择基础文档问答、图文并茂回复。
-
在请求高峰时段,创建过程可能需要数小时(取决于数据量),请耐心等待。
更新知识库
知识库内容的任何变更均会实时同步到所有引用该知识库的应用中。
文档搜索类知识库
-
自动更新(推荐)
可通过整合对象存储 OSS、函数计算 FC 以及阿里云百炼知识库相关API实现。操作步骤如下:
-
手动更新
在知识库页面,找到目标知识库,单击卡片上的查看详情。
-
如何新增文件:单击上传数据,勾选数据连接器中的已有文件。
-
如何删除文件:找到目标文件后,单击其右侧的删除。
-
如何修改文件内容:当前不支持文件的原地更新或覆盖上传。需先删除知识库中的旧版本文件,再将修改后的新版本文件重新导入知识库。
注意:保留旧版本文件可能导致过时内容被检索和召回。
-
数据查询、图片问答类知识库
说明 :图片问答类知识库的详情页没有直接的 上传数据 按钮,需通过 查看数据源 链接跳转到连接器详情页进行数据更新操作。
-
自动更新
不支持。
-
手动更新
当知识库的数据源为应用数据中的数据表时,只能手动更新,分为以下两步。
-
步骤一:更新数据表
进入应用数据页签,在左侧列表中选择目标数据表,单击上传数据。
-
如何插入新数据:导入类型选择增量上传。需上传一个仅包含表头和新增数据行的Excel文件。
文件表头须与当前表结构一致。可使用页面上的 下载模板 功能获取标准表头文件,并在该文件中直接填写新数据。
-
如何删除数据:导入类型选择覆盖上传。需上传一个包含表头及最新完整数据(已移除待删除记录)的Excel文件。
如何获取全量数据:单击页面上的
 下载XLSX格式数据。
下载XLSX格式数据。 -
如何修改数据:导入类型选择覆盖上传。需上传一个包含表头及最新完整数据(已包含相应修改)的Excel文件。
-
-
步骤二:将变更同步至知识库
返回知识库列表,找到目标知识库,单击卡片上的查看详情。单击数据表左上方的
 图标,确认后即可将数据表的最新内容同步至知识库。
图标,确认后即可将数据表的最新内容同步至知识库。每次更新后仍需手动重复以上步骤 。
-
音视频搜索类知识库
编辑知识库
知识库创建后,仅支持修改知识库名称、知识库描述和相似度阈值,其他配置均无法更改(如需更改,须删除并重新创建知识库)。编辑操作仅支持通过控制台进行,无对应API。
操作步骤:在知识库页面,找到目标知识库,单击卡片上的![]() ,再单击编辑。注意:同一知识库每个自然日最多允许变配1次,超出后操作将被静默拒绝(无错误提示)。
,再单击编辑。注意:同一知识库每个自然日最多允许变配1次,超出后操作将被静默拒绝(无错误提示)。
删除知识库
删除操作不可逆,请谨慎操作。
删除知识库前,建议先解除其与所有已发布的阿里云百炼应用的关联。
已关联的未发布应用不影响删除操作。
变更配置
旗舰版提供RCU以保障高QPS下的检索性能,并支持更大的存储容量;标准版适合开发测试或低并发场景。
标准版与旗舰版支持互转。旗舰版的RCU数量支持修改。
同一知识库每个自然日最多允许变配1次。
RCU: RCU(Retrieval Compute Unit)是知识库检索并发能力的度量单位。1 RCU ≈ 支撑在线检索最高50 QPS。RCU越大,可支撑的并发数越高。
-
注意:
-
如果知识库(旗舰版)使用平台存储,降级为标准版前,需将已用存储空间降至80 GB以下。
可通过删除知识库内的文件或数据来释放存储空间。
-
-
操作步骤:
-
在知识库页面,找到目标知识库,单击卡片上的
 ,再单击编辑。
,再单击编辑。 -
根据当前版本,在弹出的窗口中选择相应操作:
-
标准版:选择升级。
-
旗舰版:选择降级或变更RCU数量。
-
-
按照界面提示完成操作,单击确定保存后配置即时生效。
-
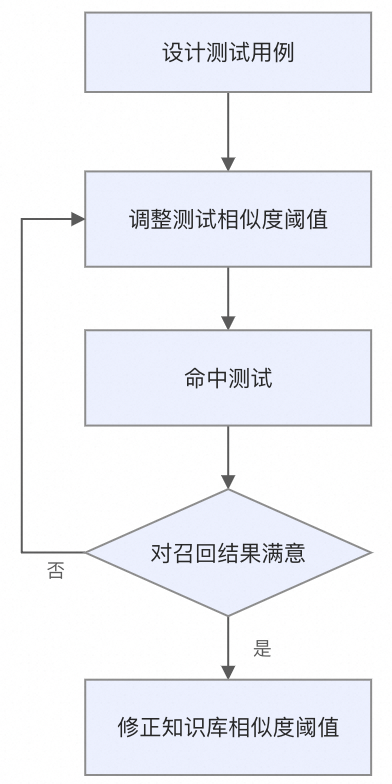
命中测试
命中测试用于验证知识库能否为AI应用提供准确的知识输入。通过模拟用户提问,检查知识库的召回结果并调优相似度阈值。
命中测试中的排序模型支持三种模式:问答模式(默认,适合用户提问与文档内容不完全匹配的场景)、相似模式(适合查询与文档内容高度相似的场景)和自定义高级模式。不同模式下,同一查询的排序得分可能存在显著差异(例如,同一切片在问答模式下得分47%,在相似模式下可达69%)。
通过命中测试,可以:
-
验证知识库能否为AI应用提供有效的知识输入
-
调优相似度阈值,平衡召回率与准确性
-
发现知识库中的内容缺失或质量问题
场景示例
-
场景1:客户咨询产品价格
测试输入:"你们的阿里云百炼手机多少钱?" 期望结果:能够召回包含价格信息的相关文本切片。 -
场景2:技术问题排查
测试输入:"设备连不上WiFi怎么办?" 期望结果:能够召回WiFi连接故障排除的相关文本切片。 -
场景3:视觉理解文档检索(视觉理解知识库)
视觉理解知识库支持纯文字、纯图片和图文组合三种查询模式: 模式1(纯文字):输入"Object Storage Service",召回文档和图片中的相关切片。 模式2(纯图片):上传一张产品截图,系统通过视觉理解匹配语义相近的切片。 模式3(图+文字):同时上传图片并输入描述文字,组合查询可提升召回相似度。 -
场景4:极速问答(极速问答知识库)
极速问答知识库仅支持文本查询(不支持图片输入),适合结构化文档的快速检索: 测试输入:"千问Pro 8的价格是多少?" 期望结果:快速召回包含价格信息的 FAQ 切片。
操作步骤
-
在知识库页面,找到目标知识库,单击卡片上的命中测试。
-
在测试界面输入问题(建议收集用户常见问题),观察召回结果。
-
召回结果:即本次测试的命中结果(已按相似度降序排列),单击任一切片即可查看其具体内容。
-
 图标:若为图片问答类知识库,系统会先将输入图片转为向量并检索相关记录,再将这些记录与提问一起交由大模型生成回答;若为文档搜索、数据查询类知识库,上传的图片不参与检索;若为使用场景选择「视觉理解」的文档搜索类知识库,上传图片同样参与检索,支持纯文字、纯图片和图文组合三种查询模式,图文组合查询可提升召回相似度。
图标:若为图片问答类知识库,系统会先将输入图片转为向量并检索相关记录,再将这些记录与提问一起交由大模型生成回答;若为文档搜索、数据查询类知识库,上传的图片不参与检索;若为使用场景选择「视觉理解」的文档搜索类知识库,上传图片同样参与检索,支持纯文字、纯图片和图文组合三种查询模式,图文组合查询可提升召回相似度。
-
-
确认相关文本切片是否被正确召回。如未召回,需调整相似度阈值并重复上一步。
-
单击查看历史召回记录,可对比不同阈值设置下的历史召回效果。
配额与限制
-
关于知识库支持的数据源与容量等信息,请参见知识库配额与限制。
-
单个阿里云百炼应用可关联的知识库数量:
-
文档搜索类:最多5个
-
数据查询类:最多5个
-
图片问答类:最多1个
不同类型知识库可同时关联,总数最多为11个。
-
计费说明
知识库功能本身免费,但调用引用了知识库的阿里云百炼应用时,可能产生相应费用。
|
步骤 |
计费情况 |
|
|
|
不收费。 |
|
|
|
调用阿里云百炼应用时,知识库召回的文本切片会增加大模型输入 Token 数量,从而可能增加模型推理(调用)费用。详情请参见计费项与定价。 注意:若仅通过调用Retrieve 接口在知识库中检索,不经过阿里云百炼应用生成回答,则不产生费用。 |
|
|
|
不收费。 |
|
API参考
-
如需获取最新完整的知识库API列表及输入输出参数,请参见API 目录(知识库)。
-
如需了解相关API的具体用法和代码示例,请参见知识库API指南。
常见问题
构建知识库
处理图片及多模态内容
-
使用文档搜索类知识库
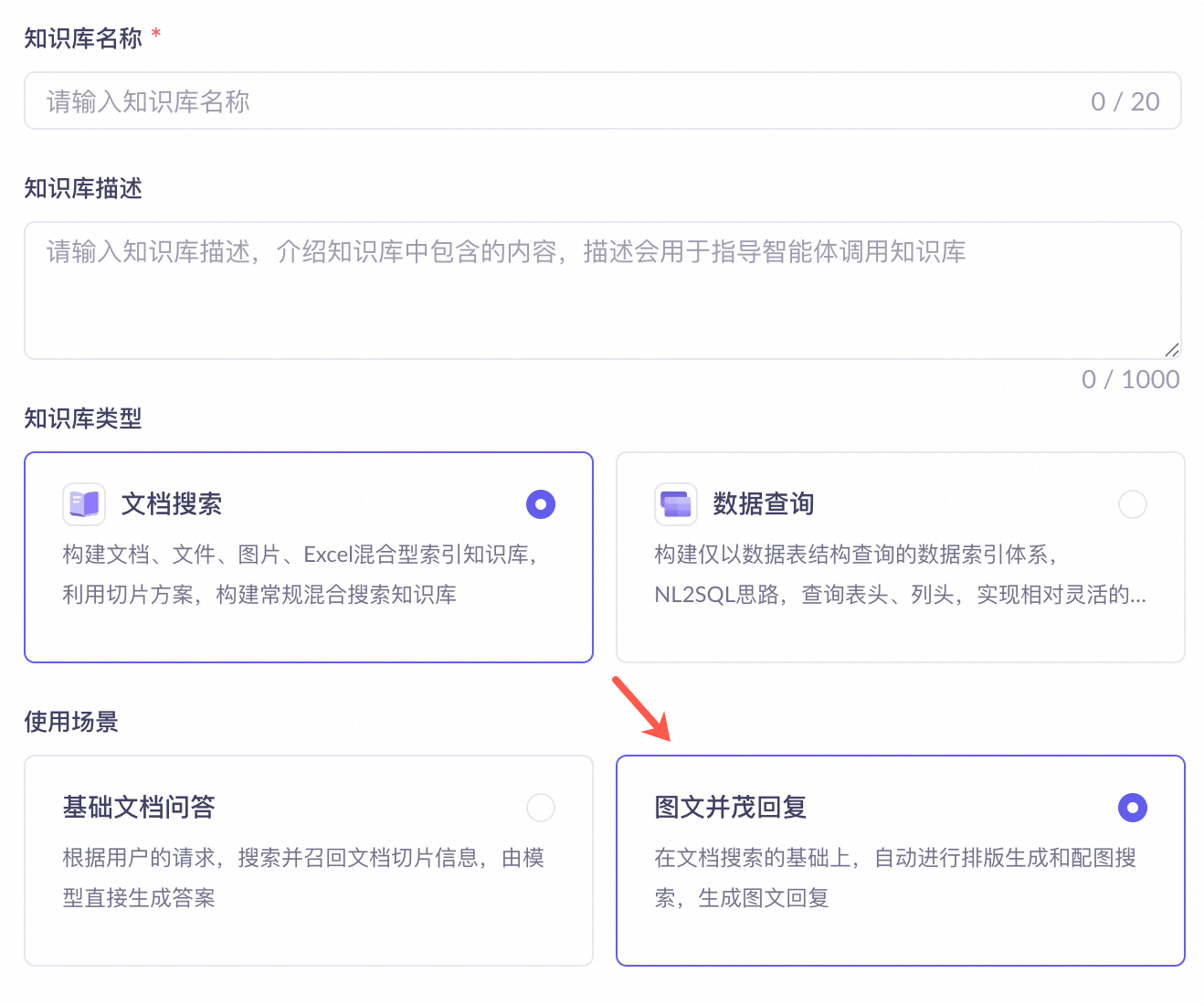
-
在构建知识库时,知识库类型选择文档搜索,使用场景选择图文并茂回复。
选择图文并茂回复后,知识库将从文件插图中提取摘要,大模型根据摘要与问题的相关性自主决定是否插入图片。
重要上传文档时不能选择电子文档解析,否则无法获取图片内容。电子文档解析不识别文档中的图片,会导致图文并茂回复功能无法正常使用。
-
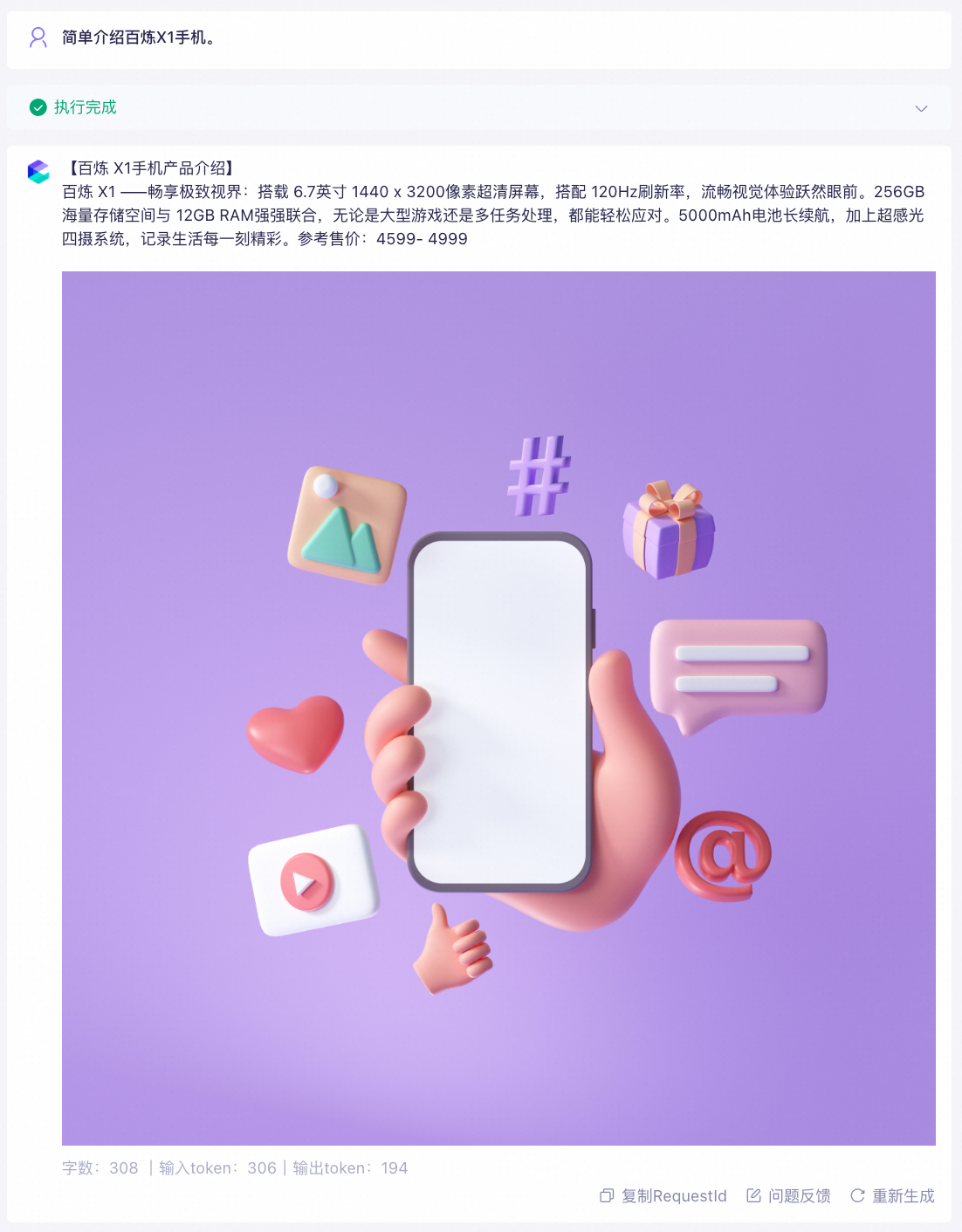
创建或编辑智能体应用时,选择千问-Plus或千问-Plus-Latest模型(经测试,两款模型效果最佳)。点击文档知识库右侧的+按钮,添加上一步构建的知识库。
说明召回长度须小于文档实际长度。若召回长度超过文档实际长度,系统将直接返回完整文档内容,不执行图文并茂的逻辑判断。
注意:当前"图文并茂回复"与"展示回答来源"功能暂不支持同时开启。
-
实际问答效果:
-
将图片上传至公网可访问位置并获取完整 URL。推荐使用 OSS,具体操作请参见将图片上传至OSS并使用其文件URL。
-
在文件中插入完整 URL(不支持相对路径)。不支持直接在文档中嵌入图片文件(如通过复制粘贴或菜单插入本地图片),必须使用公网可访问的URL链接引用图片。
若已按说明操作但图片仍无法显示,请检查文本切片中的URL是否完整,确认是否存在多余空格或特殊字符(可能被系统误解析),如有问题可直接编辑修正。
文件正确引用图片示例
提示词模板示例
实际问答效果

# 知识库 请记住以下材料,他们可能对回答问题有帮助。 ${documents} # 要求 如果有图片,请展示图片。文件错误引用图片示例
提示词模板示例
实际问答效果

# 知识库 请记住以下材料,他们可能对回答问题有帮助。 ${documents} # 要求 如果有图片,请展示图片。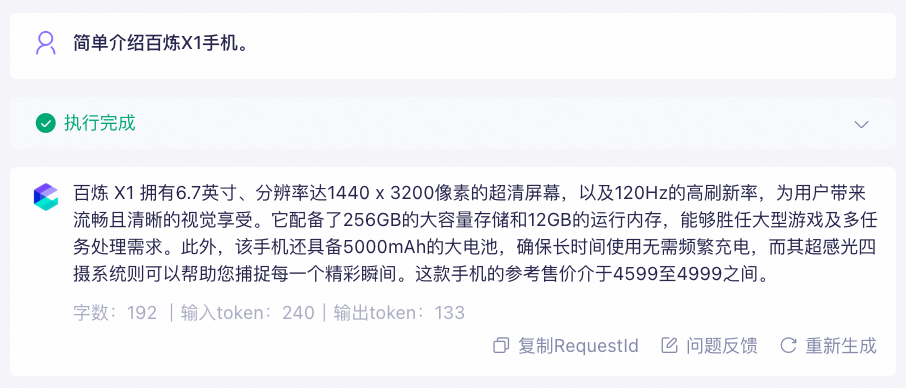
解释:直接在文件中嵌入图片时,阿里云百炼应用不会在回答中展示该图片。
使用图片问答类知识库
-
将图片上传至公网可访问位置并获取完整 URL。推荐使用 OSS,具体操作请参见将图片上传至OSS并使用其文件URL。
-
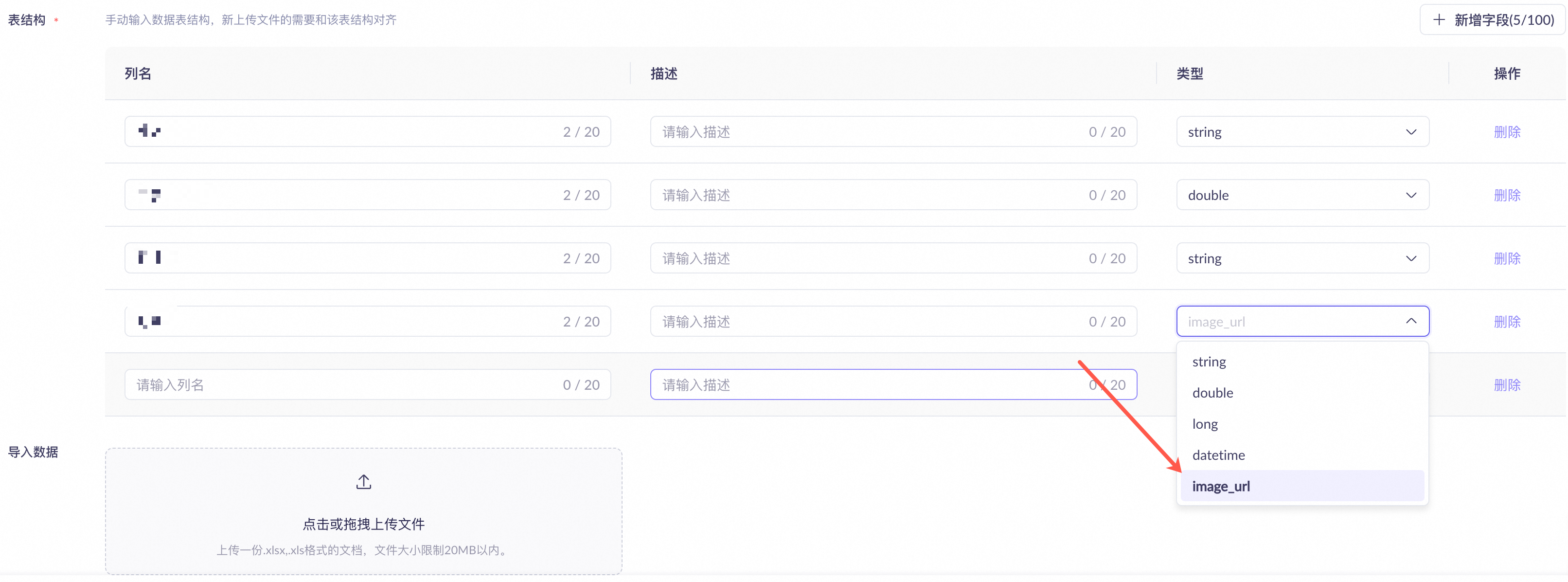
在表格页签中新建数据表,并添加 image_url 类型字段用于存储图片的完整 URL。
说明-
image_url 字段不支持存储相对路径。
-
单个 image_url 字段不支持存储多个图片 URL。若单条记录需关联多张图片,须为每张图片分别创建独立的
image_url字段(如image_1、image_2等)。 -
数据表中每个 image_url 指向的图片大小不得超过 3 MB,超出限制将导致知识库创建失败。
-
数据表创建后无法新增或修改 image_url 类型字段,请在初次设计表结构时预留所有所需的图片字段。
-
-
构建知识库时,知识库类型选择图片问答。
-
创建或编辑智能体应用时,点击图片(图片问答类知识库)右侧的+按钮,添加上一步构建的知识库,并将提示词模板修改为:
# 知识库 请记住以下材料,他们可能对回答问题有帮助。 ${documents} # 要求 如果有图片,请展示图片。 -
在页面右侧的输入框中发起提问。
例如:"简单介绍百炼X1手机。"
正确引用图片示例
提示词模板示例
用户提示词和阿里云百炼应用返回的结果

# 知识库 请记住以下材料,他们可能对回答问题有帮助。 ${documents} # 要求 如果有图片,请展示图片。
-