本文介绍近实时数仓解决方案可解决的业务痛点和主要架构功能。
背景信息
企业依赖大数据平台快速地从海量数据中获得洞察从而更及时和有效地决策的同时,也对处理数据的新鲜度和处理本身的实时性要求越来越高。大数据平台普遍采用离线、实时、流三种引擎组合的方式以满足用户实时性和高性价比的需求。但是很多业务场景并不要求延时秒级更新可见或者行级更新,更多的需求是分钟级或者小时级的近实时数据处理叠加海量数据批处理场景。
MaxCompute在原有的离线批处理引擎基础上升级架构,推出了近实时数仓解决方案。MaxCompute近实时数仓,基于Delta table实现了增全量数据一体化存储和管理,并且推出了丰富的增量计算能力,同时升级了MaxCompute短查询加速(MCQA2.0)以支持查询秒级返回。
现状分析
当前典型的数据处理业务场景中,对于时效性要求低的大规模数据全量批处理的单一场景,直接使用MaxCompute足以很好的满足业务需求,对于时效性要求很高的秒级实时数据处理或者流处理,则需要使用实时系统或流系统来满足需求。但对于综合业务场景,比如时效性要求为分钟级或者小时级的近实时数据处理场景和海量数据批处理场景的解决方案,使用单一或者联邦多引擎都会存在一些问题。
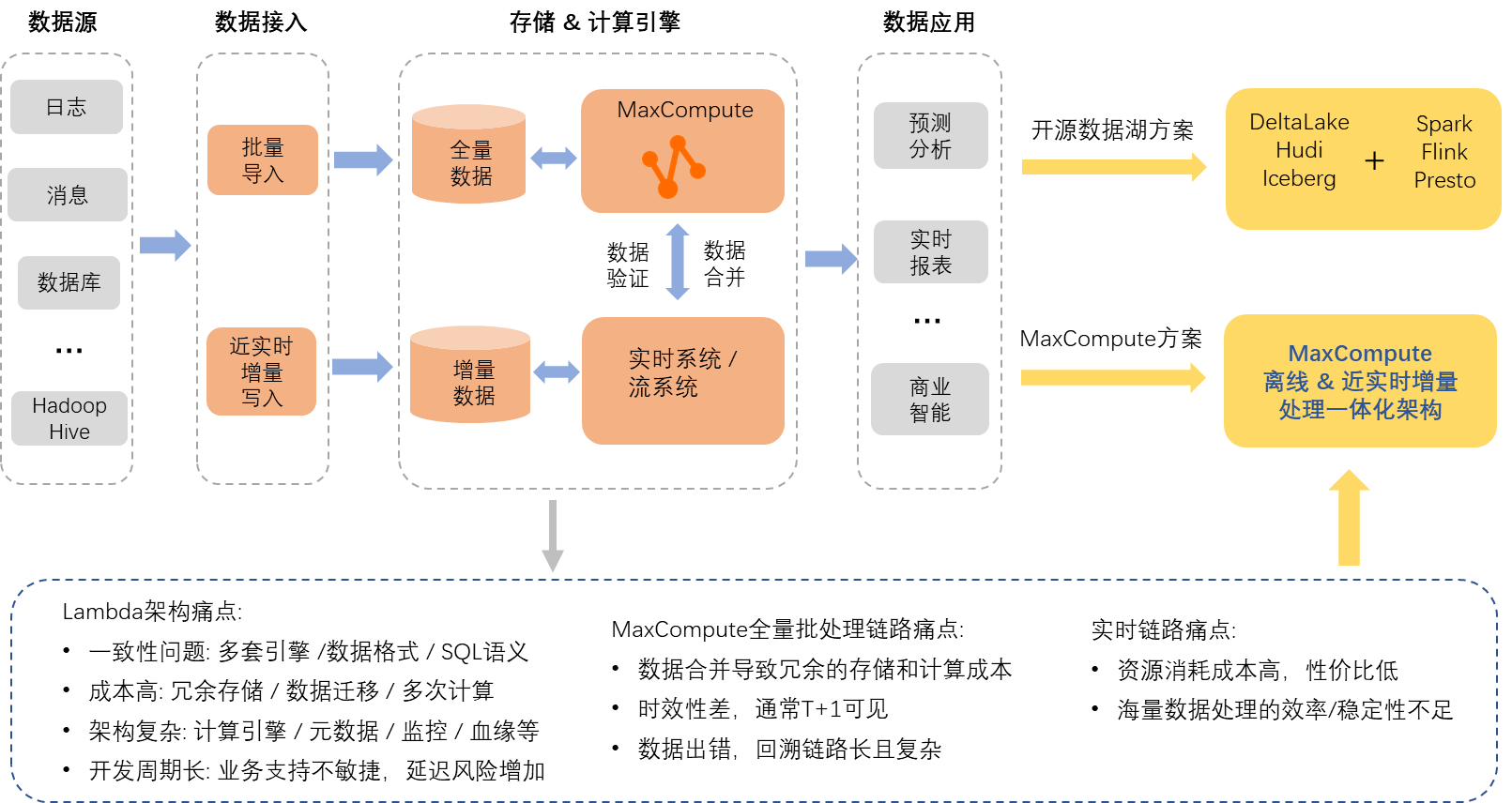
如上图所示,如果使用单一的MaxCompute离线批量处理链路,有些场景需持续将用户分钟级增量数据和全量数据做合并处理和存储,产生冗余的计算和存储成本,也有场景需要将各种复杂的一些链路和处理逻辑转化成T+1的批次处理,极大增加链路复杂度,且时效性也较差。但如果使用单一的实时系统,资源消耗的成本比较高,性价比也较低,并且大规模数据批处理的稳定性也不足。因此当前比较典型的解决方案是Lambda架构,全量批处理使用MaxCompute链路,时效性要求比较高的增量处理使用实时系统链路,但该架构也存在大家所熟知的一些固有缺陷,比如多套处理和存储引擎引发的数据不一致问题,多份数据冗余存储和计算引入的额外成本,架构复杂以及开发周期长等。
针对这些问题近几年大数据开源生态也推出了各种解决方案,最流行的就是Spark/Flink/Presto开源数据处理引擎,深度集成开源数据湖Hudi、Delta Lake和Iceberg三剑客,践行统一的计算引擎和统一的数据存储思想来综合提供解决方案,解决Lambda架构带来的一系列问题。而MaxCompute在离线批处理计算引擎架构上,自研设计开发的增量数据存储和处理架构,同样可提供离线与近实时增量处理一体化解决方案,在保持经济高效的批处理优势下,同时具备分钟级的增量数据读写和处理的业务需求,另外,可提供Upsert,Time travel等一系列实用功能来扩展业务场景,可有效地节省数据计算,存储和迁移成本,切实提高用户体验。
MaxCompute近实时架构
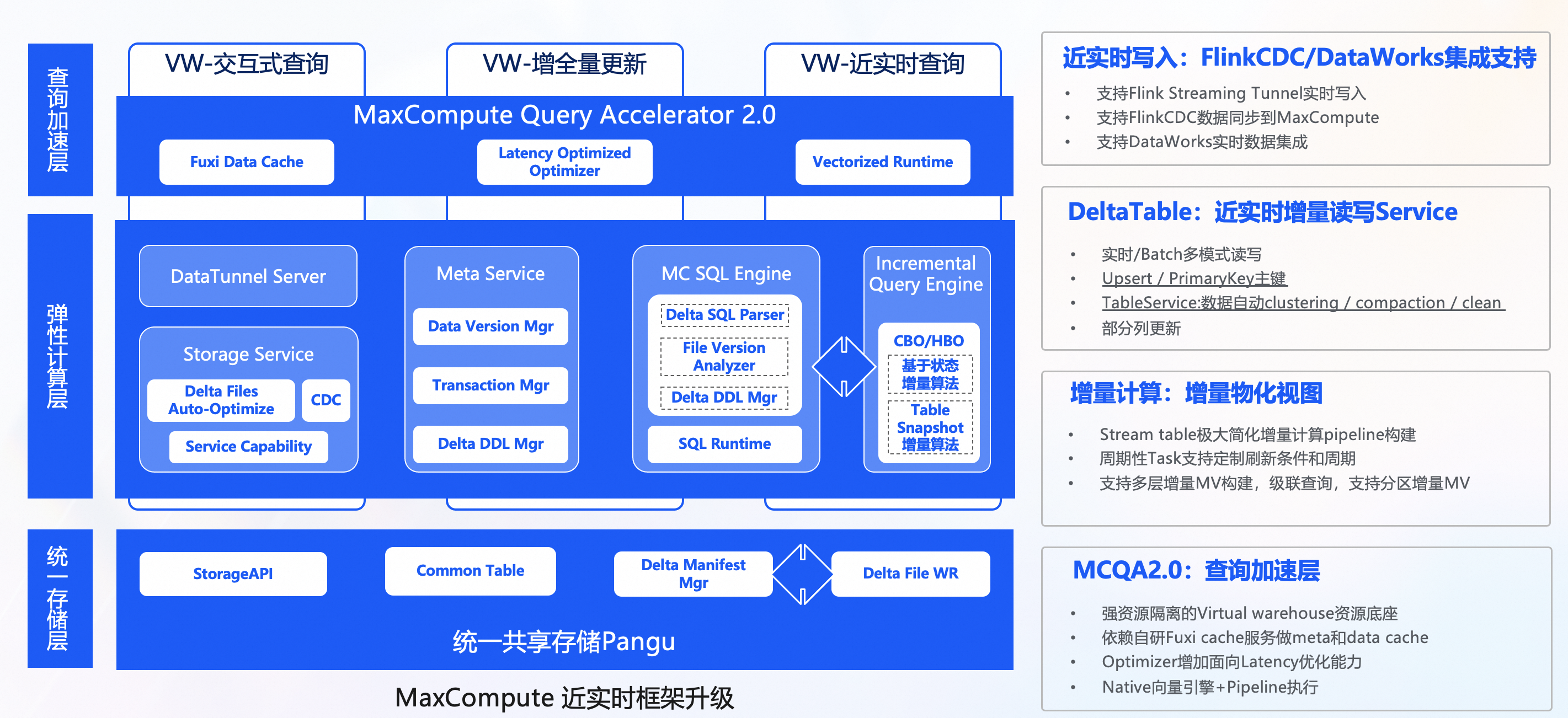
上图所示即为MaxCompute高效支持上述综合业务场景的全新架构,支持丰富的数据源方便地通过定制开发的接入工具实现增量和离线批量数据导入到统一的存储中,由后台数据管理服务自动优化编排数据存储结构,使用统一的计算引擎支持近实时增量处理链路和大规模离线批量处理链路,而且由统一的元数据服务支持事务和文件元数据管理。它带来的优势非常显著,比如,可有效解决纯离线系统处理增量数据导致的冗余计算和存储、时效低等问题,也能避免实时或流系统高昂的资源消耗成本,同时可消除Lambda架构多套系统的不一致问题和减少冗余多份存储成本以及系统间的数据迁移成本。SQL Optimizer针对增量查询也做了针对性的优化,尤其是MV增量刷新场景,Optimizer基于Cost估计刷新操作选取基于状态的增量算法、还是基于表快照的增量算法。查询加速层(MCQA2.0)基于VW强隔离的资源底座,提升查询性能的同时也能很好的保证查询性能的稳定性。依赖自研的FDC,加速层做了全链路的Cache优化,Optimizer增加了面向Latency优化模式,Runtime也进一步优化向量化执行以避免执行阶段Codegen相关的开销。
总体而言,使用该全链路一体化架构既可以满足增量处理链路的计算存储优化以及分钟级的时效性,又能保证批处理的整体高效性,还能有效节省资源使用成本。
核心功能
MaxCompute近实时数仓主要提供以下三个方面功能:支持分钟级导入的MC Delta Table,更好平衡Latency和Throughput的增量计算功能,全新升级的支持查询秒级返回的MCQA2.0。

三部分核心功能如下:
Delta Table增量表格式:支持分钟级数据导入,这种表格式底层使用 AliORC 作为文件格式,支持 UPSERT 语义,并能够提供标准的 CDC(Change Data Capture)方式读写增量数据。它依赖于 MC 存储服务和元数据服务,自动进行数据管理。
增量计算:基于Delta Table增量表格式,MaxCompute增加了增量物化视图(Materialized View)、Time Travel 以及 Stream Table 等一系列的增量计算能力。同时增量 MV 和周期性调度Task提供了不同的触发频率,从而为用户提供更多手段来平衡延迟(Latency)和吞吐量(Throughput)。
MCQA2.0查询加速:是对MaxCompute 查询加速的全新升级,通过强隔离环境提升了性能的稳定性,并将 MCQA 1.0 仅支持 DQL SELECT 查询扩展到了支持 SQL 全功能,包括 DDL 和 DML 等。此外,通过全链路缓存(Cache)以及将作业提交链路多个步骤异步化等优化手段,进一步提升了性能。
最重要的是,这些新能力都是基于 MaxCompute 原有的 SQL 引擎建设实现的。MaxCompute 用户无需改变开发习惯,就能够以更高的性价比分析海量数据。
优势
新架构会尽量覆盖开源数据湖(HUDI / Iceberg)的一些通用功能,方便相关业务链路之间的迁移,此外,作为完全自研设计的新架构,在功能,性能,稳定性,集成等方面也具备很多独特亮点:
统一的存储、元数据、计算引擎一体化设计,做了非常深度和高效的集成,具备存储成本低,数据文件管理高效,查询效率高,并且Time travel / 增量查询可复用MaxCompute批量查询的大量优化规则等优势。
全套统一的SQL语法支持所有功能,非常便于用户使用。
深度定制优化的数据导入工具,支持很多复杂的业务场景。
无缝衔接MaxCompute现有的业务场景,可以减少迁移、存储、计算成本。
完全自动化管理数据文件,保证更好的读写稳定性和性能,自动优化存储效率和成本。
基于MaxCompute平台完全托管,用户可以开箱即用,没有额外的接入成本,功能生效只需要创建一张Delta Table即可。
作为完全自研的架构,需求开发节奏完全自主可控。