为了支持增全量存储和处理一体化架构,Delta Table(简称DT)设计了统一的表数据组织格式,既可支持MaxCompute普通表的所有功能,同时也能很好的支持增量处理链路的新场景,包括time travel查询、upsert操作等。本文为您介绍DT的表数据格式详情。
Delta Table的表关键属性
Delta Table目前只支持主键表,您可以在执行建表命令Create Table时设置关键属性:primary key (PK)及tblproperties ("transactional"="true" )。
primary key (PK):设置本属性后,可高效支持Upsert数据导入功能,PK值相同的多行记录在快照查询或者COMPACTION操作后会merge成一行数据,只保留最新状态。
tblproperties ("transactional"="true" ):transactional属性代表满足ACID事务特性,保障快照隔离和读写并发控制,写入的每行数据会附加事务属性字段,比如事务timestamp,用来支持Time travel查询,过滤出正确数据版本的记录。
此外还可设定其他一些重要的表属性,比如write.bucket.num用来配置数据写入的并发度,acid.data.retain.hours用来配置历史数据的有效查询时间范围等。更多属性可参见Delta Table表参数。
Delta Table数据文件类型
Delta Table支持多种数据文件组织格式,来高效支持全量读写和近实时增量读写等多种场景,主要包含BaseFile和DeltaFile两种形态。
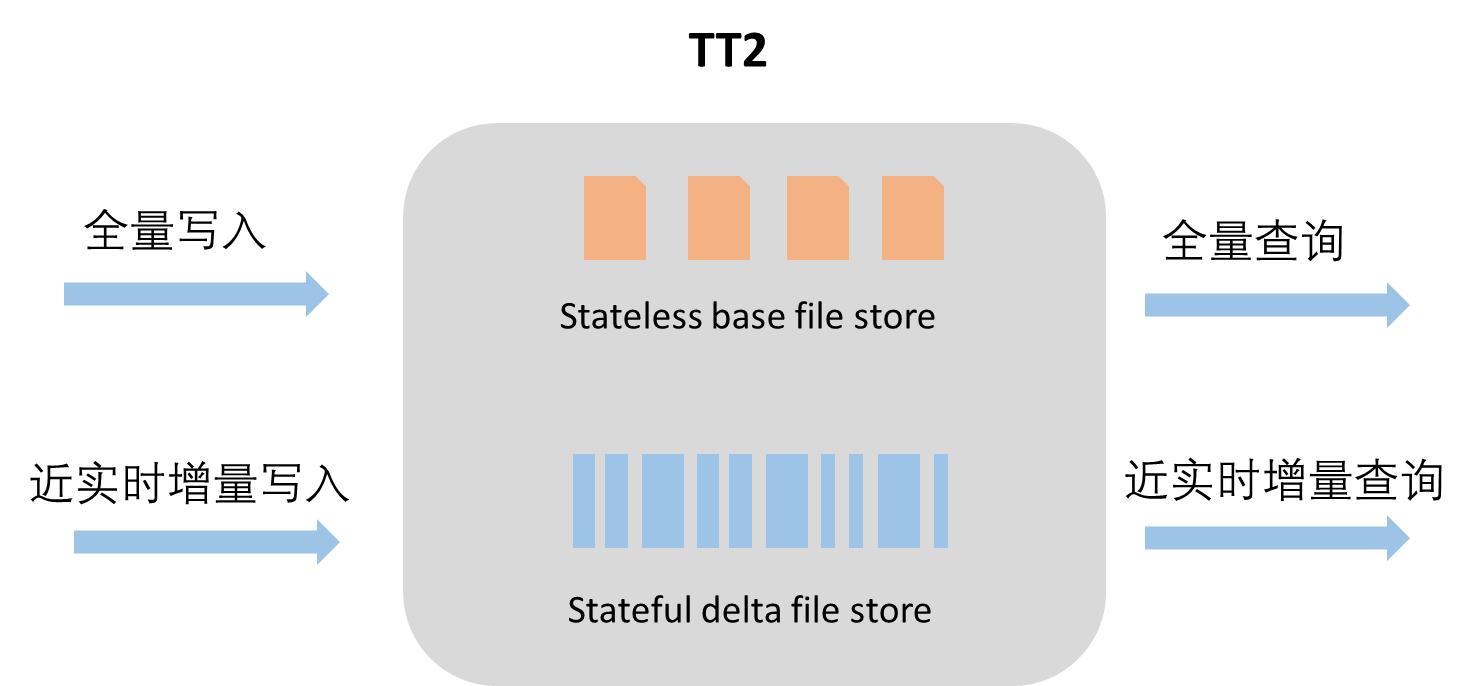
其中:
DeltaFile:每次事务Commit写入(Update/Delete)的数据文件类型,会保存每行数据的中间历史状态,用于满足近实时增量读写需求。Clustering(小文件合并)合并操作也会生成DeltaFile,按照列式压缩存储。
BaseFile:DeltaFile经过COMPACTION合并操作后生成的数据文件类型,会消除中间历史状态,PK值相同的记录只会保留一行,按照列式压缩存储,用来支撑高效的全量数据查询需求。
进行数据查询时:
每次快照查询会先找到最新生成的BaseFile,然后查找在BaseFile之后写入所有符合要求的DeltaFile一起Merge之后输出,因此查询模式属于Merge On Read。更多查询细节请参见Time travel查询。
所有数据文件会按照PK列进行排序,可有效提升Merge的效率,并有助于DataSkipping查询优化。数据文件会按照列式压缩存储,可有效减少存储的数据量,节省成本,也可有效地提升IO读写效率。
数据存储分桶
为了进一步优化读写效率,Delta Table支持按照BucketIndex对数据进行切分存储,BucketIndex数据列默认复用PK列,bucket数量可通过配置表属性write.bucket.num指定,因此对同一张表或分区的数据,写入数据会按PK列值对数据进行切分,相同PK值的记录会落在同一个bucket中。
数据的近实时增量导入可通过bucket数量水平扩展来支持高并发,因此需根据数据写入的流量以及表数据总存储大小来评估设置合理的bucket数量。Bucket数量过多,容易产生过多的小文件,影响数据读写效率和存储的稳定性,Bucket数量过少,则不容易满足高流量高速度的近实时导入需求。
此特性也有助于提升数据查询效率,如果过滤条件为Bucket数据列,也可有效地进行Bucket裁剪,减少查询的数据量。并且如果GroupBY或者Join的Key列和Bucket数据列相同,则可直接进行Local Join或者GroupBy操作,减少Shuffle,节省计算资源和提升查询性能。
数据优化管理操作例如小文件clustering、compaction等都可按照Bucket粒度来并发执行计算,提高执行效率,缩短运行时间。
记录类型
目前记录只支持upsert、delete两种数据类型进行写入和存储,upsert包含insert / update两种隐含语义,如记录不存在就代表insert,如已存在就代表update。