本文以MySQL为源端,Hive为目标端场景为例,为您介绍如何把MySQL整个数据库的数据离线同步到Hive。
准备工作
-
数据源准备
-
已创建MySQL数据源和Hive数据源,详情请参见数据源配置。
-
-
资源组:已购买Serverless资源组。
-
网络连通:资源组与数据源之间需完成网络连通方案概述。
适用范围
整库离线同步任务支持在数据开发 (Data Studio) 与数据集成两大模块中进行配置,两者在功能上互通。
-
配置一致:无论是数据开发还是在数据集成模块中创建任务,其配置界面、参数设置和底层功能完全一致。
-
双向同步:在数据集成模块中创建的任务,会自动同步并显示在数据开发模块的
data_integration_jobs目录下。这些任务会按照源端类型-目的端类型的通道进行归类,便于统一管理。
配置同步任务
步骤一:新建同步任务
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
-
在左侧导航栏单击同步任务,然后在页面顶部单击新建同步任务,并配置任务信息:
-
数据来源类型:
MySQL。 -
数据去向类型:
Hive。 -
具体类型:
整库离线。 -
同步步骤:同步步骤与后续配置项全增量控制具有联动关系,可组合后形成不同的同步方案。
-
结构迁移:自动在目标端创建与源端匹配的数据库对象(如表、字段、数据类型等),但不包含数据。
-
全量同步(可选):一次性将源端指定对象(如表)中的所有历史数据完整地复制到目标端。通常用于首次数据迁移或数据初始化。
-
增量同步(可选):在全量同步完成后,根据增量条件持续地捕获源端新增的数据,并将其同步至目标端。
-
-
步骤二:配置数据源与运行资源
-
在来源数据源区域选择已添加至工作空间的
MySQL数据源,在去向数据源区域选择已添加的Hive数据源。 -
在运行资源区域,选择同步任务所使用的资源组,并为该任务分配资源组CU。如果您的同步任务因资源不足出现OOM现象,请适当调整资源组CU占用取值。
-
并确保来源数据源与去向数据源均通过连通性检查。
步骤三:同步方案配置
1. 配置数据来源
此步骤中,您可以在源端库表区域选择源端数据源下需要同步的表,并单击![]() 图标,将其移动至右侧已选库表。
图标,将其移动至右侧已选库表。
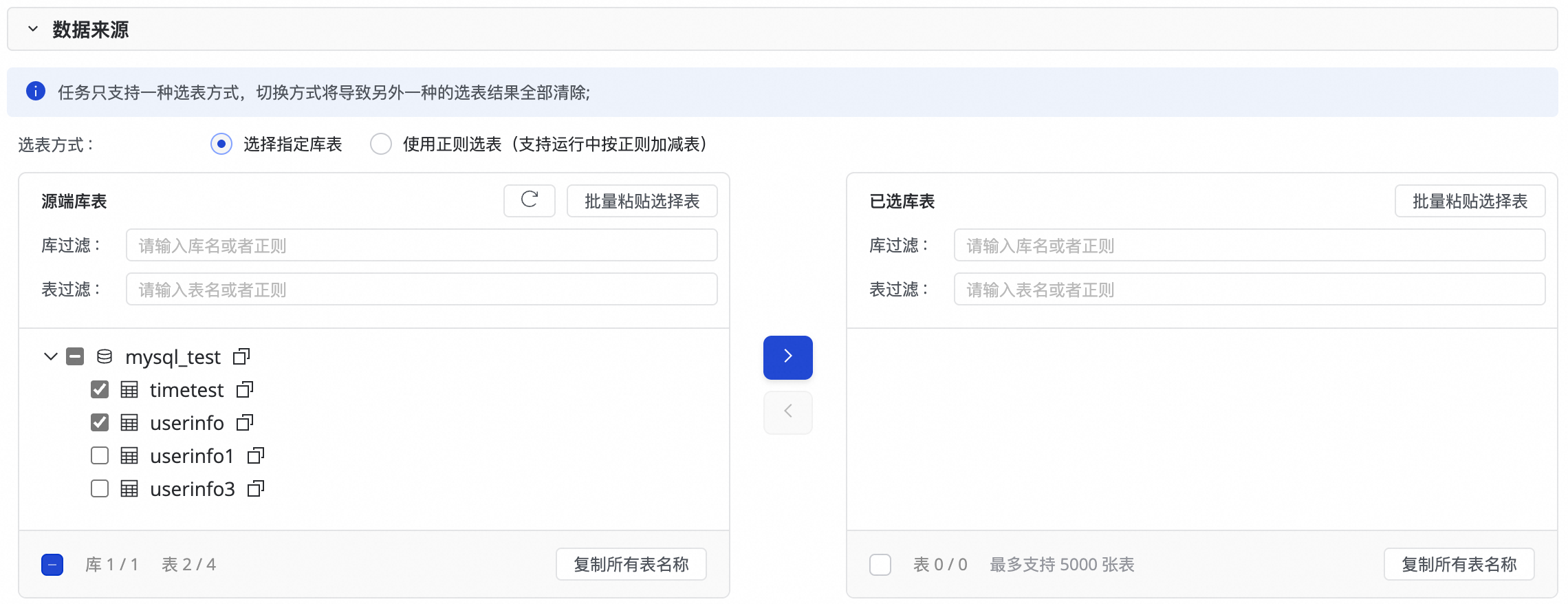
若库表数较多,可以使用库过滤或者表过滤,通过配置正则表达式来选择需要同步的表。
2. 数据去向
此操作会影响通过数据集成新建表的表结构,已有表的表结构不受影响。
-
新建表存储方式:可以选择内表、外表,决定新建目标表格式是内表还是外表。
-
新建表格式:可以选择parquet、orc、txt,决定新建目标表的存储格式。
-
写入方式:决定任务在写入时,是清空目标表还是保留历史数据。同步时首先会将数据写入HDFS文件,再将文件load至目标表中,通过该参数决定load时是否保留已有数据。
-
分区初始化设置:决定新建表的分区初始化值,默认只有一级分区,您可以通过配置按钮进行修改。
3. 方案配置(全增量控制)
配置任务的执行频率
若选择“全量同步”或“增量同步”:您可以自由选择任务的执行方式为一次性或周期性。
若同时选择“全量同步”和“增量同步”:系统将采用 “首次一次性全量,后续周期性增量” 的内置模式,此选项不可更改。
同步步骤
全增量控制
数据写入说明
应用场景
全量同步
一次性
任务启动后,可以将源表所有数据一次性同步至目标表或指定分区。
数据初始化、系统迁移
周期性
按设定的调度周期,将源表所有数据周期性地同步至目标表或指定分区。
数据对账、T+1全量快照
增量同步
一次性
任务启动后,根据您指定的增量条件,将增量数据一次性同步至指定分区。
手动修复某批次数据
周期性
任务启动后,按设定的调度周期与增量条件,将增量数据周期性同步至指定分区。
日常ETL、构建拉链表
全量同步&增量同步
(内置模式,不可选择)
首次运行:自动执行一次表结构初始化和历史数据全量同步。
后续运行:按设定的调度周期与增量条件,将增量数据周期性同步至指定分区。
一键式数据入仓/入湖
说明整库离线的周期调度实例生成方式等同发布后即时生成,详情参见:实例生成方式:发布后即时生成。
分区生成方式可在后续的目标表字段赋值中定义,可使用常量,或使用系统预置变量、周期调度参数动态生成。
调度周期、增量条件与分区生成方式的配置存在联动关系,详情参见:6. 增量条件。
配置周期调度参数。
如果您的任务涉及周期性同步,则可单击周期调度参数进行配置。此处的参数可在后续目标表映射中配置增量条件及字段赋值时使用。
4. 目标表映射
在此步骤,您需要定义源表与目标表的映射规则,并定义周期配置和增量条件来指定数据写入方式。

|
操作 |
说明 |
||||||||||||
|
刷新映射 |
系统会自动列出您选择的源端表,但目标表的具体属性需要您刷新确认后才能生效。
|
||||||||||||
|
编辑字段类型映射(可选) |
系统存在默认的源端字段类型与目标端字段类型映射,您可以单击表格右上角的编辑字段类型映射,自定义源端表与目标端表字段类型映射关系,配置完后单击应用并刷新映射。 编辑字段类型映射时,需要注意字段类型转换规则是否正确,否则会导致类型转换失败而产生脏数据,影响任务运行。 |
||||||||||||
|
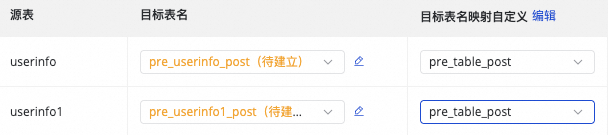
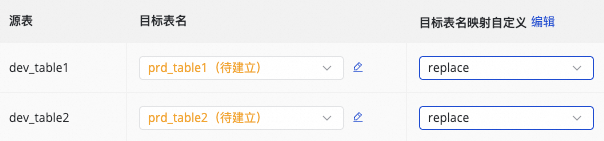
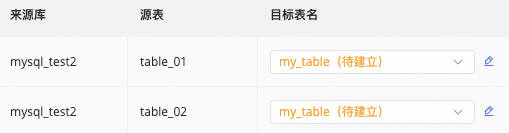
目标表名映射自定义(可选) |
系统存在默认的表名生成规则:
可实现如下场景:
|
||||||||||||
|
目标库名映射自定义(可选) |
部分目标数据源如Hologres,支持对目标库进行映射规则定义,配置方式可参考目标表名映射自定义的方式。 |
||||||||||||
|
目标Schema名映射自定义(可选) |
部分目标数据源如Hologres,支持对目标端的Schema进行映射规则定义,配置方式可参考目标表名映射自定义的方式。 |
||||||||||||
|
编辑目标表结构(可选) |
系统将基于源端表结构自动生成目标表结构,常规场景下无需人工干预。若需特殊处理,可通过以下方式自定义
|
||||||||||||
|
目标表字段赋值 |
普通字段会根据源端表和目标表的同名字段进行自动映射,分区字段和上述步骤中的新增字段需要手动赋值。操作如下:
在赋值时支持赋值常量与变量,可在表字段及分区字段的赋值方式中进行切换类型,支持方式如下:
变量和周期调度参数均会在任务调度时,自动根据日期替换代码中的参数。 |
||||||||||||
|
设置源端切分列 |
您可以在源端切分列中下拉选择源端表中的字段或选择不切分。同步任务执行时将根据该字段切分为多个task,以便并发、分批读取数据。 推荐使用表主键作为源端切分列,不支持字符串、浮点和日期等其他类型。 目前仅源端为MySQL时支持源端切分列。 |
||||||||||||
|
自定义高级参数 |
支持为子任务单独设置运行时配置,请在完全明白对应参数的含义情况下再进行修改,避免产生任务延时、资源占用过大导致阻塞其他任务、数据丢失等不可预料的问题。 |
 按钮,选择手动输入和内置变量进行拼接,生成目标表名。其中变量支持源端数据源名,源端数据库名和源端表名。
按钮,选择手动输入和内置变量进行拼接,生成目标表名。其中变量支持源端数据源名,源端数据库名和源端表名。
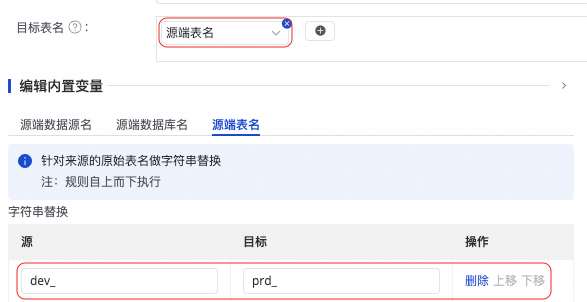

 按钮添加字段。
按钮添加字段。 提示中查看变量的具体含义。
提示中查看变量的具体含义。5. 周期配置
若增量同步配置为周期性,需要在目标表完成周期配置。包括调度周期、调度时间、调度资源组等。当前同步的调度配置与数据开发中节点的调度配置一致,参数详情可参见节点调度配置。
如果一次性同步的表数量过多,建议配置调度时间时分批执行,防止任务堆积,造成资源挤兑。
6. 增量条件
若任务需要同步增量数据,必须配置增量条件。该条件决定了每个调度周期批次的实例具体同步哪些数据。
-
作用与语法
-
作用:增量条件本质上是对源端数据进行筛选的
WHERE子句。 -
语法:配置时,您只需填写
WHERE后面的条件表达式,无需写入WHERE关键字。
-
-
配合调度参数实现增量同步
为了实现周期性的增量同步,您可以在增量条件中使用调度参数。例如,配置为
STR_TO_DATE('${bizdate}', '%Y%m%d') <= columnName AND columnName < DATE_ADD(STR_TO_DATE('${bizdate}', '%Y%m%d'), INTERVAL 1 DAY)即可同步前一天新产生的数据。 -
写入指定分区
通过将增量条件与目标表的分区字段相结合,可以实现每个批次的增量数据精确写入对应的分区。
例如,在步骤2的增量条件下,您可以将分区字段设为
ds=${bizdate},将目标表设为按天分区。这样每天的实例只会同步源端对应日期的数据,并写入目标表的同名分区。
增量条件指定的时间区间,与分区生成的时间间隔,配合周期配置的调度周期,三者组合成合理配置后,可实现一套自动化的、业务规则与物理分区严格对齐的T+n增量ETL管道。
步骤四:高级配置
同步任务提供部分参数可供修改,您可以按需对该参数值进行修改,例如通过最大连接数上限限制,避免当前同步方案对数据库造成过大的压力从而影响生产。
请在完全了解对应参数含义的情况下再进行修改,以免产生不可预料的错误或者数据质量问题。
单击界面右上方的高级参数配置,进入高级参数配置页面。
在高级参数配置页面修改相关参数值。
步骤五:发布并执行任务
完成所有配置后,单击页面底部的保存,完成任务配置。
整库同步任务不支持直接调试,需要发布至运维中心运行。因此新建或者编辑任务均需执行发布操作后方可生效。
发布时,若勾选发布后直接启动运行,则在发布时会同步启动任务。否则,发布完成后,需要进入界面,在目标任务的操作列,手动启动任务。
单击任务列表中对应任务的名称/ID,查看任务的详细执行过程。
步骤六:配置报警规则
整库离线同步任务的报警规则需在运维中心找到对应的子任务配置。
在列,获取目标任务ID。
在列,根据集成任务的ID,找到对应的整库离线子任务,如集成任务ID为
34862,增量同步周期子任务名称为offline_odps_cyc_sync_mysql_test_timetest_to_mysql_test_timetest_34862,单击该任务的,进入规则管理页。在新建自定义规则,设置规则对象、触发方式和报警行为等,更多信息,请参见规则管理。
您可以在规则对象中搜索已获取的子任务ID,找到目标任务并为其设置报警。
管理同步任务
任务重跑
在某些特殊情况下,如果您需要增减表、修改目标表Schema信息或者表名信息时,您还可以单击同步任务操作列的重跑,系统会将新增的表或有变更的表进行同步,之前同步过的表或者未修改的表将不会再进行同步。
直接单击重跑操作,重新运行一次性任务和周期性任务。
编辑任务,进行增减表操作后,保存任务并发布。这个时候任务的操作列会显示应用更新,单击应用更新会直接触发修改后的任务重跑。新增或变更的表才会进行同步,之前同步过的表不会再同步。
查看任务
创建完成同步任务后,您可以在同步任务页面查看当前已创建的同步任务列表及各个同步任务的基本信息。

-
您可以在操作列启动或停止同步任务,在更多中可以对同步任务进行编辑、查看等操作。
-
已启动的任务您可以在执行概况中看到任务运行的基本情况,也可以单击对应的概况区域查看执行详情。
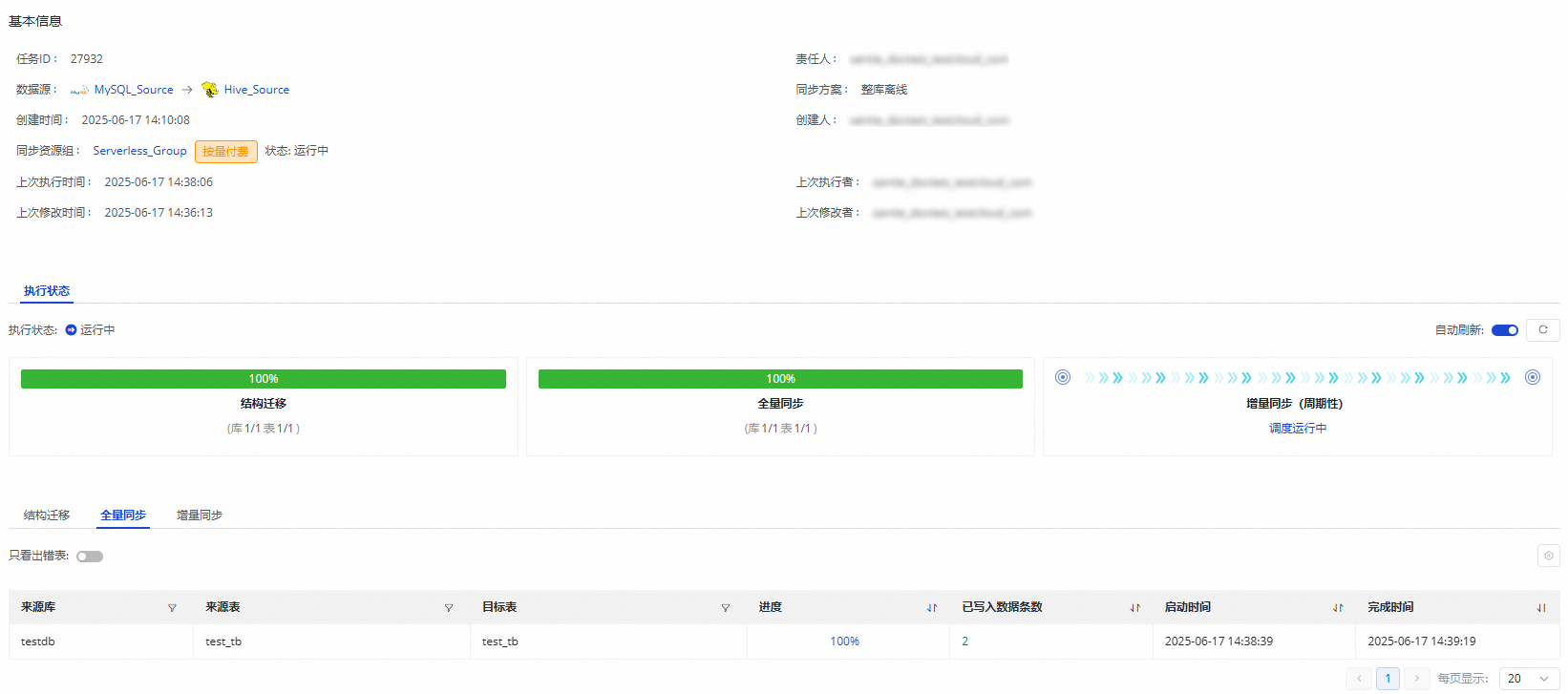
MySQL到Hive的整库离线同步任务中:
-
如果您的任务同步步骤为全量同步,此处展示结构迁移以及全量同步。
-
如果您的任务同步步骤为增量同步,此处展示结构迁移以及增量同步。
-
如果您的任务同步步骤为全量同步+增量同步,此处展示结构迁移、全量同步以及增量同步。
-
数据开发相关场景
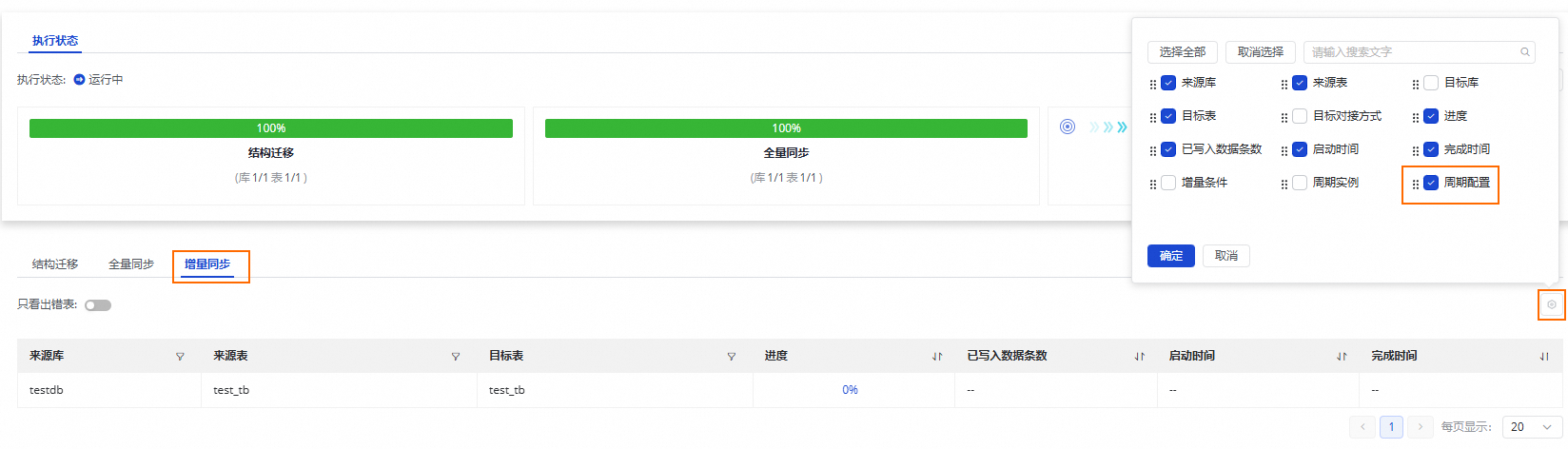
如果您有下游数据依赖,需要进行数据开发操作的场景,可以参考节点调度配置,进行节点上下游的设置,对应的周期任务节点信息可以在此处周期配置列中查看。
后续步骤
任务启动后,您可以点击任务名称,查看运行详情,进行任务运维和调优。