AI应用是AnalyticDB Ray平台提供的一套标准化应用运行与管理框架,旨在帮助用户快速搭建并部署面向特定AI场景的解决方案。推理服务是该框架的核心能力之一,支持将训练好的模型(如DeepSeek、Qwen等)快速部署为高性能在线API服务,该服务具备低延迟、高并发、自动扩缩容等特性,适用于自然语言处理、计算机视觉等典型AI推理场景。本文为您介绍创建推理服务以及使用该服务执行训练任务的操作过程。
前提条件
集群的产品系列为企业版、基础版或湖仓版。
费用说明
创建Ray Cluster资源组,会产生如下费用:
Head磁盘空间与Worker磁盘空间计费一致,均会按照设置的存储空间大小计费。
Head资源类型与Worker资源类型为CPU时,会按照所使用ACU弹性资源组计费。
Head资源类型与Worker资源类型为GPU时,会按照GPU的规格、数量计费。
操作步骤
步骤一:创建推理服务
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏,单击AI应用。
单击创建推理服务。
在创建推理服务面板配置如下参数:
基本配置:
参数
说明
应用名称
AI应用名称。您可以自定义。
开源LLM大模型
支持如下选项:
Deepseek-R1。
Qwen32B。
登录模式
支持如下选项:
资源配置:
存储配置(可选):
参数
说明
存储类型
支持如下选项:
OSS。
NAS。
存储名称
在下拉列表中选择已有的存储卷。若无存储卷,可单击点击创建,创建存储卷。
挂载路径
AI应用数据的挂载路径。
说明若需要挂载多个存储,可单击添加存储,并配置对应参数。
网络配置(可选):
参数
说明
是否挂载用户网卡(ENI)
若挂载了存储卷,则必须打开开关,以确保可以成功访问挂载的存储卷。
参数配置完成后,单击确定。
步骤二:访问推理服务
获取AI应用的调用信息。
在AI应用页面单击应用管理页签。
单击目标应用服务调用列调用信息。
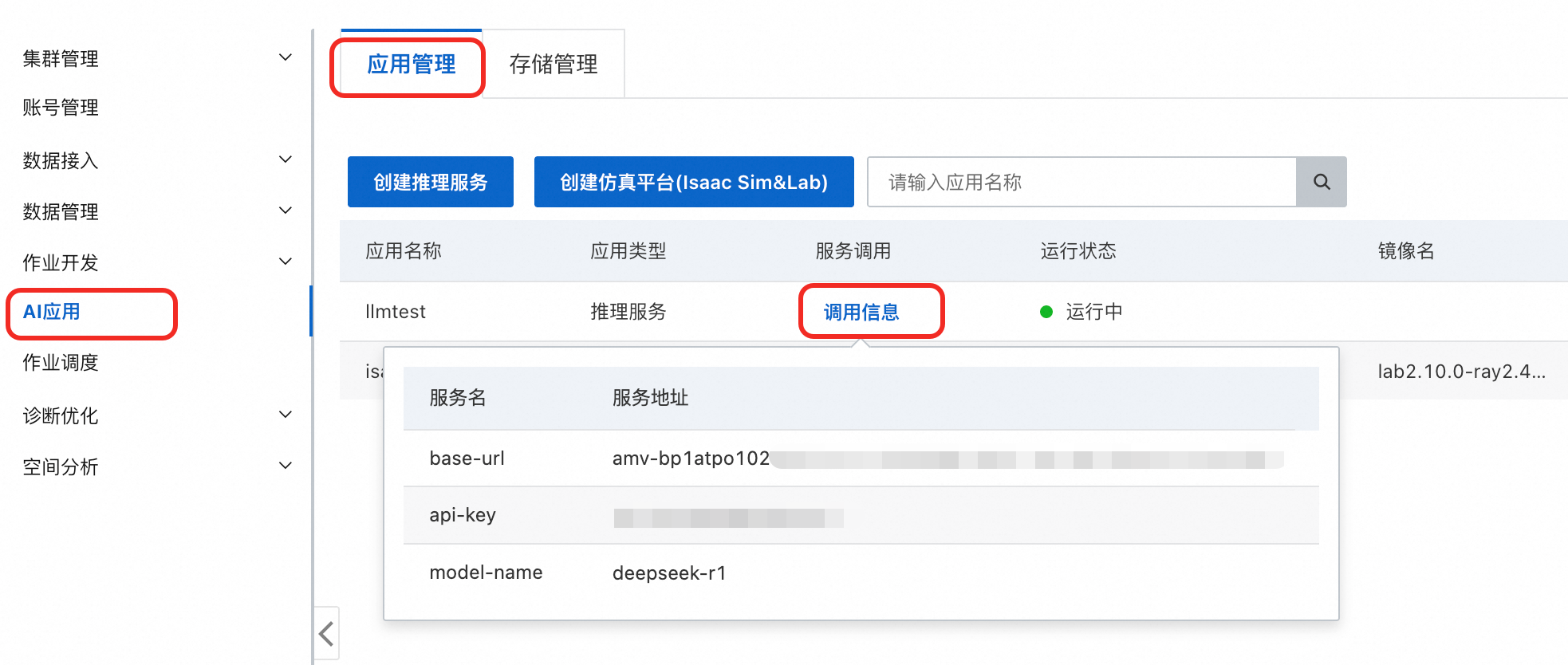
使用OpenAI兼容的方式调用推理服务。
调用示例如下,需将以下相关配置替换为获取到的实际值。
import os from openai import OpenAI client = OpenAI( # 步骤1中获取的调用信息中的api-key,建议配置环境变量读取,不建议在生产环境中直接将API Key硬编码到代码中,以减少API Key泄露风险。 api_key="<api-key>", # 步骤1中获取的调用信息中的base-url base_url="https://<base-url>", ) completion = client.chat.completions.create( model="<model-name>", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello"}, ] ) print(completion.model_dump_json())