在Kubernetes 1.27及更早的版本中,如需在Pod运行的过程中临时修改容器参数,只能更新PodSpec后重新提交,这种方式会触发Pod的删除和重建。ACK提供基于Cgroups文件动态修改Pod资源参数的功能,支持在不重启Pod的情况下,临时修改Pod的CPU、内存、磁盘IO等单机隔离参数。
本功能仅适用于临时性的调整,例如当Pod内存使用率逐渐升高,为避免触发OOM(Out Of Memory)Killer,希望在不重启Pod的前提下提高内存的Limit。对于正式的常规性运维操作,建议您使用启用CPU Burst性能优化策略、启用CPU拓扑感知调度、资源画像等功能。
前提条件
-
已通过kubectl工具连接集群。具体操作,请参见获取集群KubeConfig并通过kubectl工具连接集群。
-
已安装ack-koordinator组件,且组件版本为0.5.0及以上,请参见ack-koordinator(ack-slo-manager)。
费用说明
ack-koordinator组件本身的安装和使用免费,但在以下场景中可能产生额外费用。
ack-koordinator是非托管组件,安装后将占用Worker节点资源。您可以在安装组件时配置各模块的资源申请量。
ack-koordinator默认会将资源画像、精细化调度等功能的监控指标以Prometheus的格式对外透出。若您配置组件时开启了ACK-Koordinator开启Prometheus监控指标选项并使用了阿里云Prometheus服务,这些指标将被视为自定义指标并产生相应费用。具体费用取决于您的集群规模和应用数量等因素。建议您在启用此功能前,仔细阅读阿里云PrometheusPrometheus 实例计费,了解自定义指标的免费额度和收费策略。您可以通过用量查询,监控和管理您的资源使用情况。
修改内存Limit
当Pod内存使用率逐渐升高,为避免触发OOM Killer,您可以通过Cgroups文件临时、动态地修改容器的内存Limit。本示例将创建初始内存Limit为1 GB的容器,验证在Pod不重启的情况下通过Cgroups可以成功修改容器的内存Limit。
若您在1.22以上版本的集群中使用本功能,请确保ack-koordinator组件版本为v1.5.0-ack1.14及以上;其他组件版本仅支持1.22及以下版本的集群。
对于常规调整CPU Limit的场景,建议您使用CPU Burst性能优化策略功能,自动调整Pod的CPU资源弹性,请参见启用CPU Burst性能优化策略。若您仍需要临时调整CPU Limit的能力,请参见从resource-controller迁移至ack-koordinator中的流程来实现。
-
使用以下YAML内容,创建pod-demo.yaml文件。
apiVersion: v1 kind: Pod metadata: name: pod-demo spec: containers: - name: pod-demo image: registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4 resources: requests: cpu: 1 memory: "50Mi" limits: cpu: 1 memory: "1Gi" # 容器内存Limit为1 GB。 command: ["stress"] args: ["--vm", "1", "--vm-bytes", "256M", "-c", "2", "--vm-hang", "1"] -
执行以下命令,将pod-demo部署到集群中。
kubectl apply -f pod-demo.yaml -
执行以下命令,查看当前容器的初始内存限制值。
# 具体路径可根据Pod的UID以及Container的ID拼接得到。 cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podaf44b779_41d8_43d5_a0d8_8a7a0b17****.slice/memory.limit_in_bytes预期输出:
# 对应为1 GB,即1*1024*1024*1024=1073741824。 1073741824预期输出表明,当前容器的初始内存Limit为1 GB,与步骤1的
spec.containers.resources.limits.memory描述一致。 -
使用以下YAML内容,指定需要动态修改容器的内存Limit,创建cgroups-sample.yaml文件。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-sample spec: pod: name: pod-demo namespace: default containers: - name: pod-demo memory: 5Gi # 指定Pod的内存Limit为5 GB。 -
执行以下命令,将cgroups-sample.yaml部署到集群中。
kubectl apply -f cgroups-sample.yaml -
执行以下命令,查看修改后容器的内存限制值。
# 具体路径可根据Pod的UID拼接得到。 cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podaf44b779_41d8_43d5_a0d8_8a7a0b17****.slice/memory.limit_in_bytes预期输出:
# 对应为5 GB,即5*1024*1024*1024=5368709120 5368709120预期输出表明,容器的内存限制值为5 GB,与步骤4的
spec.pod.containers.memory描述一致,即本次修改成功。 -
执行以下命令,查看Pod运行情况。
kubectl describe pod pod-demo预期输出:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 36m default-scheduler Successfully assigned default/pod-demo to cn-hangzhou.192.168.0.50 Normal AllocIPSucceed 36m terway-daemon Alloc IP 192.XX.XX.51/24 took 4.490542543s Normal Pulling 36m kubelet Pulling image "registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4" Normal Pulled 36m kubelet Successfully pulled image "registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4" in 2.204s (2.204s including waiting). Image size: 7755078 bytes. Normal Created 36m kubelet Created container pod-demo Normal Started 36m kubelet Started container pod-demo预期输出表明,Event列表中不存在Pod重启的相关信息,Pod运行正常。
修改CPU绑核范围
如果您的应用程序对CPU性能要求较高,期望实现更好的资源隔离,您可以修改CPU Core的绑定范围,指定Pod可使用的CPU编号。
本示例将创建一个未绑定CPU Core的Pod,验证在Pod不重启的情况下通过Cgroups文件可以成功修改Pod的CPU绑核范围。
对于常规的CPU绑核场景,更推荐您使用CPU拓扑感知调度功能,为CPU敏感型的工作负载提供更好的性能。更多信息,请参见启用CPU拓扑感知调度。
-
使用以下YAML内容,创建pod-cpuset-demo.yaml。
apiVersion: v1 kind: Pod metadata: name: pod-cpuset-demo spec: containers: - name: pod-cpuset-demo image: registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4 resources: requests: memory: "50Mi" limits: memory: "1000Mi" cpu: 0.5 command: ["stress"] args: ["--vm", "1", "--vm-bytes", "556M", "-c", "2", "--vm-hang", "1"] -
执行以下命令,将pod-cpuset-demo.yaml部署到集群中。
kubectl apply -f pod-cpuset-demo.yaml -
执行以下命令,查看当前容器的CPU核心绑定情况。
# 实际路径可根据Pod的UID以及Container的ID拼接得到。 cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podf9b79bee_eb2a_4b67_befe_51c270f8****.slice/cri-containerd-aba883f8b3ae696e99c3a920a578e3649fa957c51522f3fb00ca943dc2c7****.scope/cpuset.cpus预期输出:
0-31预期输出表明,未绑定CPU前,可使用的CPU编号范围为0~31,表示CPU目前没有约束。
-
使用以下YAML内容,指定CPU的绑核信息,创建cgroups-sample-cpusetpod.yaml文件。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-sample-cpusetpod spec: pod: name: pod-cpuset-demo namespace: default containers: - name: pod-cpuset-demo cpuset-cpus: 2-3 # 指定将Pod绑定到CPU2和CPU3上。 -
执行以下命令,将cgroups-sample-cpusetpod.yaml部署到集群中。
kubectl apply -f cgroups-sample-cpusetpod.yaml -
执行以下命令,查看当前容器修改后的CPU核心绑定情况。
# 实际路径可根据Pod的UID以及Container的ID拼接得到。 cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podf9b79bee_eb2a_4b67_befe_51c270f8****.slice/cri-containerd-aba883f8b3ae696e99c3a920a578e3649fa957c51522f3fb00ca943dc2c7****.scope/cpuset.cpus预期输出:
2-3预期输出表明,容器已成功绑定到CPU2和CPU3上,与步骤4的
spec.pod.containers.cpuset-cpus描述一致,即本次修改成功。 -
执行以下命令,查看Pod运行情况。
kubectl describe pod pod-cpuset-demo预期输出:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 7m7s default-scheduler Successfully assigned default/pod-cpuset-demo to cn-hangzhou.192.XX.XX.50 Normal AllocIPSucceed 7m5s terway-daemon Alloc IP 192.XX.XX.56/24 took 2.060752512s Normal Pulled 7m5s kubelet Container image "registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4" already present on machine Normal Created 7m5s kubelet Created container pod-cpuset-demo Normal Started 7m5s kubelet Started container pod-cpuset-demo Normal CPUSetBind 84s koordlet set cpuset 2-3 to container pod-cpuset-demo success预期输出表明,Event列表中不存在Pod重启的相关信息,Pod运行正常。
修改磁盘IOPS参数
如果您需要控制磁盘IOPS,请使用操作系统为Alibaba Cloud Linux的Worker节点。
本示例将创建一个IO密集型的测试应用,验证在Pod不重启的情况下通过Cgroups文件可以对Pod的吞吐量进行限制,修改容器的磁盘IO限制。
在cgroup v1环境下使用blkio限制时,操作系统内核只会限制容器的Direct I/O,无法限制Buffered I/O。如需对Buffered I/O进行限制,请在Alibaba Cloud Linux启用cgroup v1的控制群组回写(cgroup writeback)功能,请参见开启cgroup writeback功能。该功能当前不支持在cgroup v2环境下使用。
-
使用以下YAML,创建一个IO密集型的测试应用。
将宿主机目录/mnt挂载至Pod内部使用,对应磁盘设备名称为/dev/vda1。
apiVersion: apps/v1 kind: Deployment metadata: name: fio-demo labels: app: fio-demo spec: selector: matchLabels: app: fio-demo template: metadata: labels: app: fio-demo spec: containers: - name: fio-demo image: registry.cn-zhangjiakou.aliyuncs.com/acs/fio-for-slo-test:v0.1 command: ["sh", "-c"] # 使用Fio工具对磁盘IOPS进行写测试。 args: ["fio -filename=/data/test -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=12000 -group_reporting -name=mytest"] volumeMounts: - name: pvc mountPath: /data # 挂载在/data的路径下。 volumes: - name: pvc hostPath: path: /mnt -
执行以下命令,将fio-demo部署到集群中。
kubectl apply -f fio-demo.yaml -
部署控制磁盘IOPS的Cgroups文件,对Pod的吞吐量进行限制。
-
使用以下YAML,指定设备/dev/vda1的BPS(Bit Per Second)限制信息,创建cgroups-sample-fio.yaml文件。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-sample-fio spec: deployment: name: fio-demo namespace: default containers: - name: fio-demo blkio: # BPS限制,例如1048576、2097152、3145728。 device_write_bps: [{device: "/dev/vda1", value: "1048576"}] -
执行以下命令,查看当前容器修改后的磁盘IO限制情况。
# 实际路径可根据Pod的UID以及Container的ID拼接得到。 cat /sys/fs/cgroup/blkio/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod0840adda_bc26_4870_adba_f193cd00****.slice/cri-containerd-9ea6cc97a6de902d941199db2fcda872ddd543485f5f987498e40cd706dc****.scope/blkio.throttle.write_bps_device预期输出:
253:0 1048576预期输出表明,当前磁盘的限速配置为
1048576。
-
-
查看对应节点的磁盘监控。
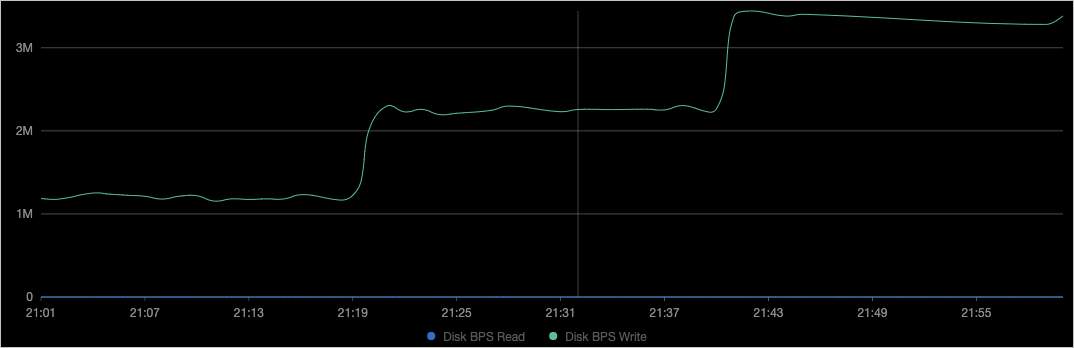
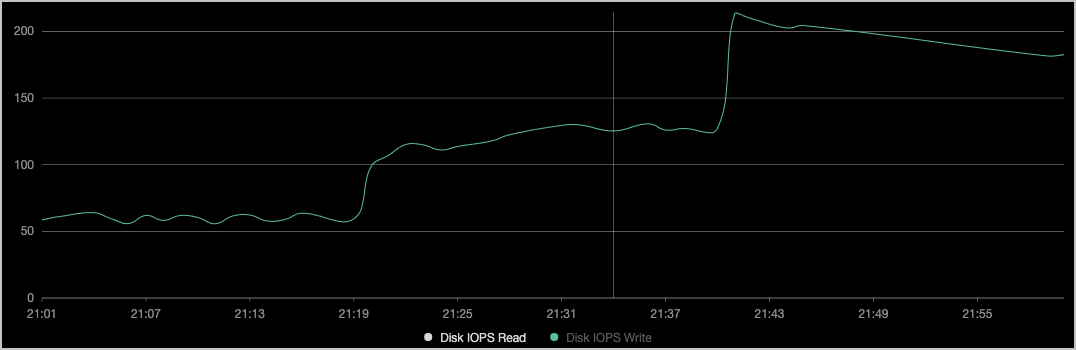
如上图所示,容器的吞吐BPS(File System Write)和步骤3的
device_write_bps限制一致,且修改过程中Pod没有被重启。说明您也可以参见接入与配置阿里云Prometheus监控启用阿里云Prometheus大盘,并在运维管理 > Prometheus 监控的应用监控页签下筛选示例应用,查看其磁盘数据。
在Deployment维度动态修改Pod资源参数
前文介绍的Pod维度的资源参数动态修改同样支持在Deployment维度生效。Pod维度的修改通过Cgroups文件的spec.pod字段内容生效;Deployment维度的修改通过spec.deployment字段内容生效。下文以修改CPU绑核范围为例,介绍如何在Deployment完成修改。其他场景操作类似。
-
使用以下YAML内容,创建go-demo.yaml文件。
Deployment中包含两个实例的压测程序,每个实例使用的资源为0.5个CPU。
apiVersion: apps/v1 kind: Deployment metadata: name: go-demo labels: app: go-demo spec: replicas: 2 selector: matchLabels: app: go-demo template: metadata: labels: app: go-demo spec: containers: - name: go-demo image: registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4 command: ["stress"] args: ["--vm", "1", "--vm-bytes", "556M", "-c", "1", "--vm-hang", "1"] imagePullPolicy: Always resources: requests: cpu: 0.5 limits: cpu: 0.5 -
执行以下命令,将go-demo部署到集群中。
kubectl apply -f go-demo.yaml -
使用以下YAML内容,指定CPU的绑定信息,创建cgroups-cpuset-sample.yaml文件。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-cpuset-sample spec: deployment: # 此处为Deployment。 name: go-demo namespace: default containers: - name: go-demo cpuset-cpus: 2,3 # 将Pod绑定到CPU2和CPU3上。 -
执行以下命令,将cgroups-cpuset-sample部署到集群中。
kubectl apply -f cgroups-cpuset-sample.yaml -
执行以下命令,查看当前容器修改后的CPU核心绑定情况。
#具体路径可根据Pod的UID以及Container的ID拼接得到。 cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod06de7408_346a_4d00_ba25_02833b6c****.slice/cri-containerd-733a0dc93480eb47ac6c5abfade5c22ed41639958e3d304ca1f85959edc3****.scope/cpuset.cpus预期输出:
2-3预期输出表明,容器绑定在CPU2和CPU3上,与Cgroups文件中的
spec.deployment.containers.cpuset-cpus描述一致。