大模型服务启动时需加载较大的模型文件,若直接从 OSS 下载,可能因网络延迟和并发限制导致启动缓慢、弹性伸缩延迟。ossfs 2.0 提供高吞吐顺序写入与智能缓存能力,可显著缩短模型加载时间。本文针对 safetensors 等主流框架,在单 GPU 与多 GPU 场景下,提供基于PV/PVC 的部署方案。
准备工作
集群与组件版本:
已创建ACK托管集群且CSI组件版本不低于v1.35.1。
本文介绍的部分大模型性能优化参数(如
memory_data_cache_size)依赖 ossfs 2.0 为 v2.0.5 及以上。CSI组件自v1.34.4版本起,已内置ossfs 2.0 v2.0.5版本。资源准备:
已创建OSS Bucket,用于存储模型文件。推荐选择与集群同地域的 Bucket,以降低跨地域访问延迟。
已完成对OSS的访问授权配置。推荐使用RRSA鉴权方式进行认证,以通过 RAM 角色授予最小的必要权限。
阶段一:准备模型数据
将模型文件从 ModelScope 等外部仓库下载至 OSS,以便快速启动服务。ossfs 2.0 支持高吞吐顺序写入,配合 ECS 内网带宽,实测写入吞吐可达 20 Gbps(OSS 默认配置的上行带宽上限),大幅缩短模型入库时间。
1. 创建PV和PVC
以下 YAML 使用 RRSA 授权方式,将 OSS Bucket 挂载为 Kubernetes 静态存储卷。详见使用ossfs 2.0静态存储卷。
otherOpts中配置的-o memory_data_cache_size=16g参数主要用于阶段二:部署模型服务,对当前的模型下载任务无性能影响。
apiVersion: v1
kind: PersistentVolume
metadata:
# PV名称
name: deepseek-r1
spec:
capacity:
# 定义存储卷容量 (此值仅用于匹配PVC)
storage: 20Gi
# 访问模式
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
# 使用ossfs 2.0客户端时固定为此值
driver: ossplugin.csi.alibabacloud.com
# 与PV名称(metadata.name)保持一致
volumeHandle: deepseek-r1
volumeAttributes:
fuseType: ossfs2
# OSS Bucket名称
bucket: oss-models
# 挂载Bucket的根目录或指定子目录
path: /models/DeepSeek-R1-0528
# OSS Bucket所在地域的Endpoint
url: "http://oss-cn-hangzhou-internal.aliyuncs.com"
# ossfs 2.0客户端配置参数,memory_data_cache_size参数对模型下载场景无影响
# 该参数用于后续模型部署阶段使用
otherOpts: "-o memory_data_cache_size=16g"
authType: "rrsa"
# 此前创建或修改的RAM角色
roleName: "demo-role-for-rrsa"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
# PVC名称
name: deepseek-r1
namespace: default
spec:
# 以下配置需要与PV一致
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi
storageClassName: ""
# 待绑定的PV
volumeName: deepseek-r1 2. 创建Job下载模型
以下Job使用ModelScope官方镜像,通过 ossfs 2.0 将模型文件直接写入挂载的 OSS 目录,避免本地磁盘中转。
Job镜像为ModelScope社区的Python 3.11 CPU环境镜像。可按需在ModelScope社区获取其他镜像。
ECS 节点与 OSS 同地域时,默认通过内网进行传输,带宽充足。ossfs 2.0 利用多线程顺序写入机制,可将数据流持续写入 OSS,实测写入吞吐可达 20 Gbps(OSS 默认配置的上行带宽上限)。
关于支持内网传输的地域,请参见ModelScope社区。
使用ACS实例运行Job下载模型,还需在YAML中将环境变量
INTRA_CLOUD_ACCELERATION_REGION配置为当前地域。
apiVersion: batch/v1
kind: Job
metadata:
name: download-deepseek-r1
spec:
template:
spec:
containers:
- name: downloader
image: modelscope-registry.cn-hangzhou.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-py311-torch2.3.1-1.33.0
command: ["modelscope", "download"]
# 若使用ACS实例运行Job下载模型,需配置env:
#env:
# - name: INTRA_CLOUD_ACCELERATION_REGION
# value: cn-wulanchabu
args:
- "--model"
- "deepseek-ai/DeepSeek-R1-0528"
- "--local_dir"
- "/mnt/oss"
- "--max-workers=32"
volumeMounts:
- name: model-storage
mountPath: /mnt/oss
volumes:
- name: model-storage
persistentVolumeClaim:
# 引用已创建的 PVC
claimName: deepseek-r1
# Job 完成后不重启
restartPolicy: Never
# 不重试(成功或失败均只运行一次)
backoffLimit: 0 阶段二:部署模型服务
模型文件就绪后,服务启动时需在首次加载时高效读取大量小文件(如 safetensors 分片),同时兼顾内存开销与稳定性。
部署场景
当前 AI 模型种类丰富,文件格式多样,常见的包括 safetensors(安全高效)、PyTorch(通用性强)、GGUF(适用于本地推理)等。为充分发挥OSS上模型的加载性能,建议根据实际部署架构合理配置 ossfs 2.0。
在基于 GPU 数量划分的典型部署场景下,ossfs 2.0配置建议如下:
单 GPU 部署场景
对于单卡 GPU 的模型部署,ossfs 2.0 默认挂载配置已具备良好的加载性能。
单机多 GPU 并发部署场景
在单机多卡并发加载同一模型时,多个进程会同时读取同一模型文件的不同分片,易导致带宽放大问题。为解决此问题,ossfs 2.0 支持通过
--memory_data_cache_size挂载选项开启固定大小的内存缓存机制。启用后,模型文件仅从 OSS 下载一次,多进程共享本地缓存数据,能显著降低网络负载与加载延迟。说明ossfs 2.0 当前提供的内存缓存模式主要用于优化多进程并发访问同一文件时的带宽放大问题,进程内的缓存数据将在最后一个文件句柄关闭后同步释放。该模式不影响读取数据后加载到操作系统PageCache的缓存数据,这部分数据缓存行为和标准模式一致。详细说明参见挂载选项说明。
通过合理配置 ossfs 2.0,可提升各类大模型在云端的加载效率与部署稳定性。更多信息,请参见部署safetensors模型和部署其他格式模型。
部署safetensors模型
测试环境
本文中的性能数据和配置建议基于以下测试环境:
集群环境:ACK托管集群Pro版,灵骏节点池(8 GPU、192 vCPU、2 TiB内存),OSS下载带宽限制为100 Gbps。
软件版本:
CSI 版本v1.34.4(内置ossfs2 v2.0.5.ack.1)
镜像
registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/ossfs-public:demo-env-python3.12.7-sglang0.5.5-cuda12.8,包含Python v3.12.7,sglang v0.5.5。重要此镜像仅用于功能验证,请勿直接用于生产环境。
PV/PVC准备:
部署方案
ossfs 2.0 针对随机读密集型负载(如 safetensors 文件加载)提供两种部署模式,分别优化不同维度的性能瓶颈。
方案一(性能优先):PageCache预热部署
适用于节点内存充足的生产环境。通过
postStart,在容器启动前将全部模型文件顺序加载到节点的操作系统 PageCache,将网络随机读转化为高性能的“顺序读预加载 + 内存随机访问”,显著减少OSS网络请求和延迟。方案二(内存优化):直接部署
适用于内存受限或需精细化控制资源占用的场景。ossfs 2.0 利用主动预读与内存缓存(
memory_data_cache_size)协同加速,首次加载即生效,且不受系统 PageCache 回收策略影响。
PageCache预热部署
使用此方案时,需关注:
内存规划:此方案必须为Pod配置明确的
resources.limits.memory。该值需大于模型文件总大小 + 模型服务进程自身开销 + 操作系统及其他进程的冗余内存。若limit不足,系统内存压力会导致已预热的PageCache被回收,使预热失效。I/O隔离:请勿在模型服务节点上混部其他高 I/O 应用(如日志采集、备份任务),以防因系统内存竞争导致预热数据被提前回收。
部署配置与实现
预热实现:预热通过
postStart实现,会在主程序运行前执行脚本,通过cat操作强制系统将模型文件读入PageCache。相关参数:
env中新增的MODEL_DIR和PRELOADER_CONC环境变量用于向postStart脚本提供预热目录和并发数。PV复用:PageCache预热过程为顺序读,性能稳定且不受
memory_data_cache_size参数影响,可直接复用阶段一的创建的 PV/PVC,无需额外配置。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: demo-apply-deepseek-r1-with-prefetch
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: demo-apply-deepseek-r1-with-prefetch
template:
metadata:
labels:
app: demo-apply-deepseek-r1-with-prefetch
spec:
volumes:
- name: model-storage
persistentVolumeClaim:
# 引用此前创建的 PVC
claimName: deepseek-r1
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
containers:
- command:
- sh
- -c
# --tp为模型TP切分的数量,tp值非1时对应部署场景中的单机多 GPU 并发部署
- "python3 -m sglang.launch_server --model-path /models/DeepSeek-R1-0528 --tp 8"
env:
# 定义模型文件所在的目录路径。若未配置或目录不存在,脚本将跳过数据预热
- name: MODEL_DIR
value: /models/DeepSeek-R1-0528
# 定义预热脚本的并发数,默认为 4
- name: PRELOADER_CONC
value: "4"
image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/ossfs-public:demo-env-python3.12.7-sglang0.5.5-cuda12.8
name: sglang
ports:
- containerPort: 8000
name: http
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "CONC=${PRELOADER_CONC:-4}; if [ -d \"$MODEL_DIR\" ]; then find \"$MODEL_DIR\" -type f -print0 | xargs -0 -I {} -P \"$CONC\" sh -c 'cat \"{}\" > /dev/null'; fi"]
resources:
limits:
nvidia.com/gpu: "8"
# 需为Pod配置memory limit。请根据“模型文件总大小 + 服务进程开销 + 系统冗余”进行精确估算
# memory: "800Gi"
requests:
nvidia.com/gpu: "8"
volumeMounts:
- mountPath: /models/DeepSeek-R1-0528
name: model-storage
- mountPath: /dev/shm
name: dshm直接部署
该方案不依赖操作系统 PageCache,Pod 的 requests.memory 与 limits.memory 可按模型服务自身需求设置,内存占用更可控。
启用
memory_data_cache_size后,模型初次加载即可获得缓存加速,且该加速效果独立于系统 PageCache 状态,抗干扰能力强。为简化配置,本示例未设置内存限制。生产环境中,建议根据实际负载设置
limits.memory。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: demo-apply-deepseek-r1
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: demo-apply-deepseek-r1
template:
metadata:
labels:
app: demo-apply-deepseek-r1
spec:
volumes:
- name: model-storage
persistentVolumeClaim:
# 引用此前创建的 PVC
claimName: deepseek-r1
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
containers:
- command:
- sh
- -c
# --tp为模型TP切分的数量,tp值非1时对应部署场景中的单机多 GPU 并发部署场景
- "python3 -m sglang.launch_server --model-path /models/DeepSeek-R1-0528 --tp 8"
image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/ossfs-public:demo-env-python3.12.7-sglang0.5.5-cuda12.8
name: sglang
ports:
- containerPort: 8000
name: http
resources:
limits:
nvidia.com/gpu: "8"
requests:
nvidia.com/gpu: "8"
volumeMounts:
- mountPath: /models/DeepSeek-R1-0528
name: model-storage
- mountPath: /dev/shm
name: dshm部署时间
为量化 ossfs 2.0 在性能与稳定性上的双重优势,基准对比采用已启用 -o parallel_count=64 优化并发的 ossfs 1.0。测试数据可展开查看。
加载时间对比
该结果仅记录了部署过程中模型加载的时间(越小越好),测试结果中不包含服务初始化以及后续的模型预热等步骤。
ossfs 1.0在加载DeepSeek-R1-0528模型时会写满系统盘导致系统卡死,需额外配置800 GiB的本地磁盘以支持写入。
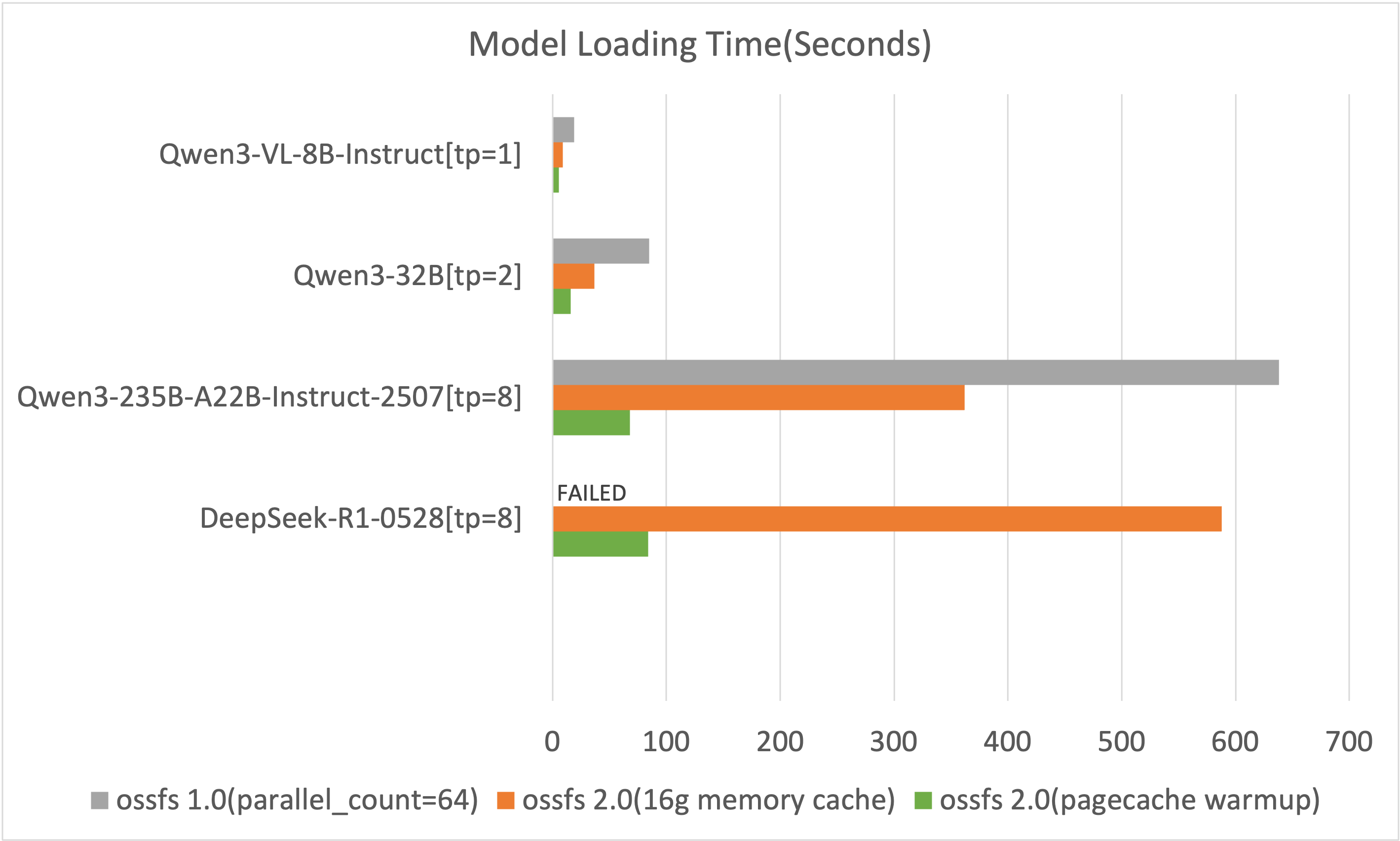
由上图可知,ossfs 2.0相比1.0版本在模型加载时间上有显著提升。
部署其他格式模型
GGUF模型部署
ossfs 2.0 在文件打开时会预分配内存进行数据预取,并在文件关闭后归还。但llama.cpp等框架在读取GGUF模型时可能无法及时关闭已读取的文件句柄,导致预取内存被持续占用而无法释放,影响后续文件的加载效率。
优化方案:
预热部署方案(推荐):参见PageCache预热部署,将模型完整加载到系统内存,规避文件句柄和预取内存问题。
不限制预取内存方案:在PV的
otherOpts字段中增加-o prefetch_chunks=-1。该配置会产生约
模型文件数量 × 1.5 GiB的额外内存开销,请在资源规划时为此预留空间,确保节点有足够的冗余内存。PV配置示例:
# ... PV spec... csi: volumeAttributes: fuseType: ossfs2 bucket: your-model-bucket path: /models/Your-GGUF-Model-Path url: "http://oss-cn-hangzhou-internal.aliyuncs.com" # 为GGUF模型解除预取内存限制 otherOpts: "-o prefetch_chunks=-1" # ... 其他认证相关配置 ...
备选方案:
若所用的GGUF模型较大且无法使用上述两种方案,建议使用OSS Connector for AI/ML进行模型加载。
PyTorch模型部署
在多GPU场景下(如使用EasyRec部署PyTorch模型),每个GPU进程可能会独立、顺序地全量加载一次模型文件,继而导致对OSS的重复读取,降低整体加载效率。
优化方案:
在PV的otherOpts字段中增加-o memory_data_cache_size=4g(可根据模型大小调整)。ossfs 2.0 的共享缓存机制可让后续GPU进程直接从缓存中读取数据,从而有效避免对OSS的重复请求,加快整体模型加载速度。PV配置示例:
# ... PV spec... csi: volumeAttributes: fuseType: ossfs2 bucket: your-model-bucket path: /models/Your-PyTorch-Model-Path url: "http://oss-cn-hangzhou-internal.aliyuncs.com" # 为PyTorch多GPU场景配置4GB共享缓存 otherOpts: "-o memory_data_cache_size=4g" # ... 其他认证相关配置 ...
生产环境使用建议
客户端选型:相较于ossfs 1.0,ossfs 2.0在顺序读写性能上有显著提升,更适合大模型部署场景。切换前请了解其使用限制,详见ossfs 2.0。
内存资源规划:本文介绍直接部署(
memory_data_cache_size)和PageCache预热部署两种加速方式均会占用节点内存。生产环境中请务必提前规划节点内存,确保有足够资源供模型服务、ossfs 2.0进程及缓存使用,避免因内存不足导致性能下降或Pod被驱逐。避免I/O干扰:为保证PageCache预热效果,请避免在模型服务节点上混部其他有大量文件读写操作的应用,防止因系统内存竞争导致预热数据被提前回收。
数据安全:删除PV/PVC资源不会删除OSS Bucket中的原始模型数据。但在操作时,请谨慎处理挂载路径,避免因误操作导致模型数据被意外覆盖。
相关文档
通过静态PV和PVC将OSS Bucket 挂载为 ossfs 2.0 存储卷,详见使用ossfs 2.0静态存储卷。
如遇读写性能(如时延、吞吐)未达到预期的情况,可参见OSS存储卷性能调优最佳实践定位并解决性能问题。