向量檢索
Table Store向量檢索(KnnVectorQuery)使用數值向量進行近似最近鄰查詢,可以在大規模資料集中找到最相似的資料項目。向量檢索功能適用於檢索增強產生(RAG)、推薦系統、相似性檢測、自然語言處理與語義搜尋等情境。
應用情境
向量檢索適用於推薦系統、映像與視頻檢索、自然語言處理與語義搜尋等情境。
檢索增強產生(RAG)
RAG是一種將檢索能力和大模型能力結合在一起的AI架構,通過檢索能力增強大模型輸出結果的準確性,尤其是在私域資料或者專業資料領域可以大幅提升大模型輸出結果的準確性。當前廣泛應用於知識庫情境。
推薦系統
在電商、社交媒體、視頻流媒體等平台中,使用者行為、偏好、內容特徵等內容可以編碼為向量進行儲存,然後通過向量檢索快速找到與使用者興趣相匹配的產品、文章或視頻,實現個人化推薦,提升使用者滿意度和留存率。
相似性檢測(映像、視頻和語音等)
在映像,視頻、語音、聲紋和Face Service等領域中,可以將這些非結構化的資料轉換為向量表示,然後通過向量檢索快速找到最相似的目標。例如,在電商平台中,使用者上傳一張圖片後,系統能迅速找出具有類似樣式、顏色或圖案的商品圖片。
自然語言處理與語義搜尋
在NLP領域,將文本轉換為向量表示(例如Word2Vec、BERT嵌入等),然後通過向量檢索理解查詢語句的語義,並找出語義上最相關的文檔、新聞、問答等內容,提升搜尋結果的相關性和使用者體驗。
知識圖譜與智能問答
知識圖譜節點和關係可以表示為向量,通過向量檢索能夠加速實體連結、關係推理以及智能問答系統的響應速度,使系統能夠更準確地理解和回回覆雜的問題。
產品核心優勢
低成本
核心引擎採用最佳化後的DiskAnn技術,相較於HNSW演算法,無需載入所有索引資料到記憶體,只需不到10%的記憶體即可達到HNSW圖演算法的高召回率和高效能,使整體成本顯著低於同類型系統。
簡單易用
向量檢索作為多元索引的一個子功能,也具備Serverless特性,使用者無需搭建部署系統,只需通過Table Store控制台建立執行個體即可開始使用。
使用過程中支援隨用隨付,無需關心水位和擴容,系統在儲存和計算上均支援水平擴充。向量檢索最大可以支援千億規模,非向量檢索最大可以支援十萬億規模。
向量檢索時內部引擎使用查詢最佳化工具自動選擇最佳演算法和執行路徑,無需進行眾多參數的調優即可達到高召回率和高效能,大幅降低使用門檻,有效縮短業務研發周期。
支援通過SQL、多種SDK(Java、Golang、Python和Node.js等語言)和開源架構(LangChain、LangChain4J和LlamaIndex)等方式使用向量檢索。
功能概述
向量檢索(KnnVectorQuery)使用數值向量進行近似最近鄰查詢,可以在大規模資料集中找到最相似的資料項目。
向量檢索繼承了多元索引的所有特性,無需部署搭建系統,即開即用,隨用隨付。支援多元索引的流式構建,資料寫入表後近即時可查詢;支援高吞吐的新增、更新和刪除;查詢效能和採用HNSW演算法的系統相當。
使用KnnVectorQuery功能查詢資料時,您可以需要指定要查詢相似性的向量、要匹配的向量欄位以及要查詢的最鄰近TopK個值,來擷取向量欄位中與要查詢相似性的向量最相似的TopK個值。您還可以組合使用其他非向量檢索的查詢功能來過濾查詢結果。
向量欄位說明
使用KnnVectorQuery功能前,您需要在建立多元索引時配置向量欄位並指定向量維度、向量資料類型和向量之間的距離度量演算法。
向量欄位在資料表中對應欄位的資料類型必須為字串類型,在多元索引中的資料類型必須為Float32數組字串。向量欄位的具體配置說明請參見下表。
配置項 | 說明 |
dimension | 向量維度,當前最大支援4096維。維度值必須和上遊向量產生(embedded)系統產生的向量維度一致。 向量欄位的數組長度與該欄位的dimension參數配置相等,例如向量欄位的值為 說明 當前僅支援稠密向量,多元索引中向量欄位的資料維度必須和建立索引時Schema中設定的維度保持一致。如果過多或者過少都會導致該行資料構建索引失敗。 |
dataType | 向量的資料類型。當前僅支援Float32,並且Float32不支援NaN和Infinite等極端值。 資料類型必須和上遊向量產生(embedded)系統產生的向量資料類型保持一致。 說明 如果有其他資料類型的向量使用需求,請提交工單聯絡我們。 |
metricType | 向量之間的距離度量演算法。取值範圍包括歐氏距離(euclidean)、餘弦相似性(cosine)、點積(dot_product)。 距離度量演算法必須和上遊向量產生(embedded)系統的建議演算法保持一致。更多資訊,請參見距離度量演算法說明。 |
向量產生(embedded)系統的不同模型或者不同版本產生的向量屬性不同,包括維度、資料類型和距離度量演算法。向量檢索系統中的向量欄位的屬性(維度、資料類型和距離度量演算法)必須和向量產生(embedded)系統中產生的向量屬性保持一致。關於向量產生的具體操作,請參見兩種產生向量的方式。
距離度量演算法說明
向量檢索支援的距離度量演算法包括歐氏距離(euclidean)、餘弦相似性(cosine)、點積(dot_product)。具體說明請參見下表。評分公式的值越大表示兩個向量的相似性越大。
MetricType | 評分公式 | 效能 | 說明 |
歐氏距離 (euclidean) |
| 較高 | 多維空間中兩個向量之間的直線距離。出於效能考慮,Table Store中的歐氏距離演算法未進行最後的平方根計算。歐氏距離的評分越大表示兩個向量的相似性越大。 |
點積 (dot_product) |
| 最高 | 維度相同的兩個向量的對應座標相乘,然後將結果相加。點積的評分越高表示兩個向量的相似性越大。 重要 Float32向量必須在寫入表前進行歸一化(例如使用L2範數進行歸一化),否則會出現查詢效果差、構建向量索引慢、查詢效能差等潛在問題。向量歸一化樣本請參見附錄2:向量歸一化樣本。 |
餘弦相似性 (cosine) |
| 較低 | 向量空間中兩個向量間夾角的餘弦值。餘弦相似性的評分越高表示兩個向量的相似性越大。常用於文本資料的相似性計算。 由於0無法作為除數,無法完成餘弦相似性的計算,因此Float32向量的平方和不允許為0。 重要 餘弦相似性計算複雜,推薦您在寫入資料到表之前進行向量的歸一化,然後使用點積(dot_product)作為向量距離的度量演算法。向量歸一化樣本請參見附錄2:向量歸一化樣本。 |
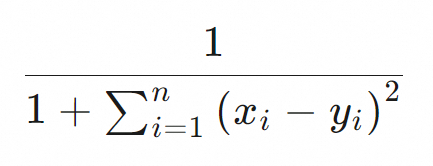
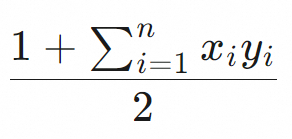

注意事項
使用向量檢索時,請注意如下事項:
向量欄位類型的個數、維度等存在限制。更多資訊,請參見多元索引使用限制。
由於多元索引服務端是多分區的,多元索引服務端的每個分區均會返回自身最鄰近的TopK個值並在協調節點進行匯總,因此如果要使用Token翻頁擷取所有資料,則擷取到的總行數與多元索引服務端的分區數有關。
目前支援使用向量檢索功能的地區包括華東1(杭州)、華東2(上海)、華北1(青島)、華北2(北京)、華北3(張家口)、華北6(烏蘭察布)、華南1(深圳)、華南3(廣州)、西南1(成都)、中國香港、日本(東京)、新加坡、馬來西亞(吉隆坡)、印尼(雅加達)、菲律賓(馬尼拉)、泰國(曼穀)、德國(法蘭克福)、英國(倫敦)、美國(維吉尼亞)、美國(矽谷)、沙特(利雅得)。
使用流程
計費說明
公測期間,使用向量索引不引入額外的向量索引專用計費項目,當前按照已有模式進行計費。
使用多元索引查詢資料時會消耗讀輸送量。更多資訊,請參見多元索引計量計費。
附錄1:與BoolQuery組合使用說明
KnnVectorQuery可以和BoolQuery自由組合使用,不同的組合使用方式會有不同的效果,以下對兩種常見的使用方式進行說明。此處以一個Filter命中資料量較少的情境為例進行介紹。
假設表中有1億張圖片,其中使用者“a”總計有5萬張圖片,但是近7天內僅有50張圖片,使用者“a”希望以圖搜圖的方式找到7天內最相似的10張圖片。由下表說明可知KnnVectorQuery的Filter內部使用BoolQuery的組合使用方式能滿足使用者“a”的查詢需求。
組合使用方式 | 查詢條件圖示 | 說明 |
KnnVectorQuery的Filter內部使用BoolQuery |
| KnnVectorQuery命中的行資料為在滿足BoolQuery條件下返回最相似的TopK個行資料,SearchRequest返回的結果為TopK行數中的前Size個。 在此樣本中,KnnVectorQuery首先通過Filter篩選出該使用者“a”在7天內的所有50張圖片,然後再從這50張圖片中找到最相似的10張圖片返回給使用者。 |
BoolQuery中使用KnnVectorQuery |
| BoolQuery的每一個子查詢條件會首先進行查詢,然後對所有子查詢求交集。 在此樣本中,KnnVectorQuery會返回表中1億張圖片中最相似的前TopK=500張圖片,然後再按照順序找出使用者“a”在7天內的10張圖片。但是由於所有圖片的TopK=500張圖片中不一定包含使用者“a”近7天內所有的50張圖片,因此該查詢方式不一定能找到近7天內的10張圖片,甚至找不到任何資料。 |


附錄2:向量歸一化樣本
向量歸一化的範例程式碼如下:
public static float[] l2normalize(float[] v, boolean throwOnZero) {
double squareSum = 0.0f;
int dim = v.length;
for (float x : v) {
squareSum += x * x;
}
if (squareSum == 0) {
if (throwOnZero) {
throw new IllegalArgumentException("can't normalize a zero-length vector");
} else {
return v;
}
}
double length = Math.sqrt(squareSum);
for (int i = 0; i < dim; i++) {
v[i] /= length;
}
return v;
}