本文介紹如何使用Table Store的統計彙總功能進行資料分析。您可以通過統計彙總功能實現求最小值、求最大值、求和、求平均值、統計行數、去重統計行數、百分位統計、按欄位值分組、按範圍分組、按地理位置分組、按過濾條件分組、長條圖統計、日期長條圖統計、擷取統計彙總分組內的行、巢狀查詢等;同時多個統計彙總功能可以組合使用,滿足複雜的查詢需求。
流程
統計彙總的完整執行流程如下圖所示。
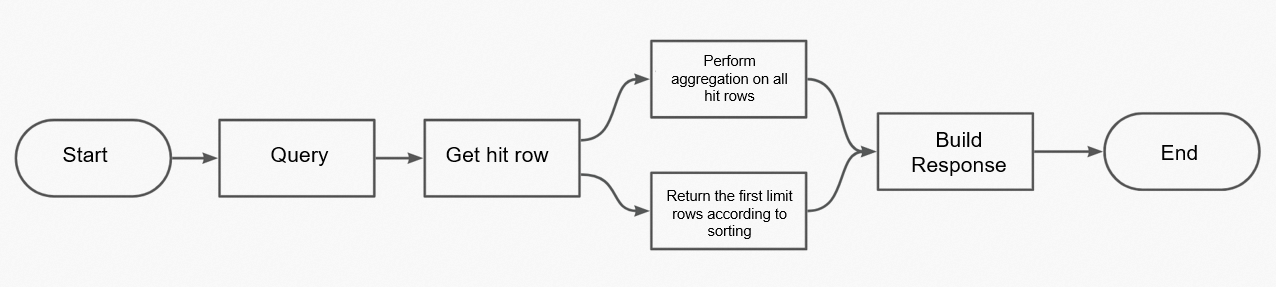
統計彙總是在服務端的“查詢”結束後執行,服務端會將“查詢”階段命中的所有文檔根據查詢請求進行統計彙總,因此統計彙總請求相比沒有統計彙總的請求會更複雜。
背景資訊
統計彙總的詳細功能請參見下表。
功能 | 說明 |
最小值 | 返回一個欄位中的最小值,類似於 SQL 中的 min。 |
最大值 | 返回一個欄位中的最大值,類似於 SQL 中的 max。 |
和 | 返回數值欄位的總數,類似於 SQL 中的 sum。 |
平均值 | 返回數值欄位的平均值,類似於 SQL 中的 avg。 |
統計行數 | 返回指定欄位值的數量或者多元索引資料總行數,類似於 SQL 中的 count。 |
去重統計行數 | 返回指定欄位不同值的數量,類似於 SQL 中的 count(distinct)。 |
百分位統計 | 百分位統計常用來統計一組資料的百分位分布情況,例如在日常系統營運中統計每次請求訪問的耗時情況時,需要關注系統請求耗時的 P25、P50、P90、P99 值等分布情況。 |
欄位值分組 | 根據一個欄位的值對查詢結果進行分組,相同的欄位值放到同一分組內,返回每個分組的值和該值對應的個數。 說明 按欄位值分組是並行計算,屬於非精確統計,可能會存在少量誤差。 |
多欄位分組 | 根據多個欄位對查詢結果進行分組,支援使用 token 進行翻頁。 |
分組嵌套 | 分組類型的統計彙總功能支援嵌套,其內部可以添加子統計彙總。 |
範圍分組 | 根據一個欄位的範圍對查詢結果進行分組,欄位值在某範圍內放到同一分組內,返回每個範圍中相應的 item 個數。 |
地理位置分組 | 根據距離某一個中心點的範圍對查詢結果進行分組,距離差值在某範圍內放到同一分組內,返回每個範圍中相應的 item 個數。 |
過濾條件分組 | 按照過濾條件對查詢結果進行分組,擷取每個過濾條件匹配到的數量,返回結果的順序和添加過濾條件的順序一致。 |
長條圖統計 | 按照指定資料間隔對查詢結果進行分組,欄位值在相同範圍內放到同一分組內,返回每個分組的值和該值對應的個數。 |
日期長條圖統計 | 對日期欄位類型的資料按照指定間隔對查詢結果進行分組,欄位值在相同範圍內放到同一分組內,返回每個分組的值和該值對應的個數。 |
擷取統計彙總分組中的行 | 對查詢結果進行分組後,擷取每個分組內的一些行資料,可實現和 MySQL 中 ANY_VALUE(field) 類似的功能。 |
多個統計彙總 | 多個統計彙總功能可以組合使用。 說明 當多個統計彙總的複雜度較高時可能會影響響應速度。 |
前提條件
已初始化 OTSClient。具體操作,請參見初始化 OTSClient。
已在資料表上建立多元索引。具體操作,請參見建立多元索引。
重要統計彙總功能支援的欄位類型屬於多元索引的欄位類型。關於多元索引的欄位類型介紹以及多元索引欄位類型和資料表欄位類型的映射關係的更多資訊,請參見資料類型。
最小值
返回一個欄位中的最小值,類似於 SQL 中的 min。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long、Double 和 Date 類型。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
樣本
/** * 商品庫中有每一種商品的價格,求產地為浙江省的商品中,價格最低的商品價格是多少。 * 等效的 SQL 陳述式是 SELECT min(column_price) FROM product where place_of_production="浙江省"。 */ public void min(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "浙江省")) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addAggregation(AggregationBuilders.min("min_agg_1", "column_price").missing(100)) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } //使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("浙江省")); query.setFieldName("place_of_production"); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.term("place_of_production", "浙江省").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MinAggregation aggregation = new MinAggregation(); aggregation.setAggName("min_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // MinAggregation aggregation2 = AggregationBuilders.min("min_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } }
最大值
返回一個欄位中的最大值,類似於 SQL 中的 max。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long、Double 和 Date 類型。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
樣本
/** * 商品庫中有每一種商品的價格,求產地為浙江省的商品中,價格最高的商品價格是多少。 * 等效的 SQL 陳述式是 SELECT max(column_price) FROM product where place_of_production="浙江省"。 */ public void max(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "浙江省")) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addAggregation(AggregationBuilders.max("max_agg_1", "column_price").missing(0)) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } //使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("浙江省")); query.setFieldName("place_of_production"); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.term("place_of_production", "浙江省").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MaxAggregation aggregation = new MaxAggregation(); aggregation.setAggName("max_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // MaxAggregation aggregation2 = AggregationBuilders.max("max_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } }
和
返回數值欄位的總數,類似於 SQL 中的 sum。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long 和 Double 類型。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
樣本
/** * 商品庫中有每一種商品的價格,求產地為浙江省的商品中,價格最高的商品價格是多少。 * 等效的 SQL 陳述式是 SELECT sum(column_price) FROM product where place_of_production="浙江省"。 */ public void sum(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "浙江省")) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addAggregation(AggregationBuilders.sum("sum_agg_1", "column_number").missing(10)) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } // 使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("浙江省")); query.setFieldName("place_of_production"); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.term("place_of_production", "浙江省").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); SumAggregation aggregation = new SumAggregation(); aggregation.setAggName("sum_agg_1"); aggregation.setFieldName("column_number"); aggregation.setMissing(ColumnValue.fromLong(100)); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // SumAggregation aggregation2 = AggregationBuilders.sum("sum_agg_1", "column_number").missing(10).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } }
平均值
返回數值欄位的平均值,類似於 SQL 中的 avg。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long、Double 和 Date 類型。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
樣本
/** * 商品庫中有每一種商品的售出數量,求產地為浙江省的商品中,平均價格是多少。 * 等效的 SQL 陳述式是 SELECT avg(column_price) FROM product where place_of_production="浙江省"。 */ public void avg(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "浙江省")) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addAggregation(AggregationBuilders.avg("avg_agg_1", "column_price")) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } //使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("浙江省")); query.setFieldName("place_of_production"); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.term("place_of_production", "浙江省").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); AvgAggregation aggregation = new AvgAggregation(); aggregation.setAggName("avg_agg_1"); aggregation.setFieldName("column_price"); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // AvgAggregation aggregation2 = AggregationBuilders.avg("avg_agg_1", "column_price").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } }
統計行數
返回指定欄位值的數量或者多元索引資料總行數,類似於 SQL 中的 count。
通過如下方式可以統計多元索引資料總行數或者某個 query 匹配的行數。
使用統計彙總的 count 功能,在請求中設定 count(*)。
使用 query 功能的匹配行數,在 query 中設定 setGetTotalCount(true);如果需要統計多元索引資料總行數,則使用 MatchAllQuery。
如果需要擷取多元索引資料某列出現的次數,則使用 count(列名),可應用於稀疏列的情境。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long、Double、Boolean、Keyword、Geo_point 和 Date 類型。
樣本
/** * 商家庫中有每一種商家的懲罰記錄,求浙江省的商家中,有懲罰記錄的一共有多少個商家。如果商家沒有懲罰記錄,則商家資訊中不存在該欄位。 * 等效的 SQL 陳述式是 SELECT count(column_history) FROM product where place_of_production="浙江省"。 */ public void count(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "浙江省")) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addAggregation(AggregationBuilders.count("count_agg_1", "column_history")) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } //使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("浙江省")); query.setFieldName("place_of_production"); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.term("place_of_production", "浙江省").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); CountAggregation aggregation = new CountAggregation(); aggregation.setAggName("count_agg_1"); aggregation.setFieldName("column_history"); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // CountAggregation aggregation2 = AggregationBuilders.count("count_agg_1", "column_history").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } }
去重統計行數
返回指定欄位不同值的數量,類似於 SQL 中的 count(distinct)。
去重統計行數的計算結果是個近似值。
當去重統計行數小於 1 萬時,計算結果接近精確值。
當去重統計行數達到 1 億時,計算結果的誤差為 2% 左右。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long、Double、Boolean、Keyword、Geo_point 和 Date 類型。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
樣本
/** * 求所有商品的產地一共來自多少個省份。 * 等效的 SQL 陳述式是 SELECT count(distinct column_place) FROM product。 */ public void distinctCount(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addAggregation(AggregationBuilders.distinctCount("dis_count_agg_1", "column_place")) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } //使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); DistinctCountAggregation aggregation = new DistinctCountAggregation(); aggregation.setAggName("dis_count_agg_1"); aggregation.setFieldName("column_place"); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // DistinctCountAggregation aggregation2 = AggregationBuilders.distinctCount("dis_count_agg_1", "column_place").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } }
百分位統計
百分位統計常用來統計一組資料的百分位分布情況,例如在日常系統營運中統計每次請求訪問的耗時情況時,需要關注系統請求耗時的 P25、P50、P90、P99 值等分布情況。
百分位統計為非精確統計,對不同百分位元值的計算精確度不同,較為極端的百分位元值更加準確,例如 1% 或 99% 的百分位元值會比 50% 的百分位元值更準確。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long、Double 和 Date 類型。
percentiles
百分位分布例如 50、90、99,可根據需要設定一個或者多個百分位。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
樣本
/** * 分析系統請求耗時百分位元分布情況。 */ public void percentilesAgg(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("indexName") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addAggregation(AggregationBuilders.percentiles("percentilesAgg", "latency") .percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)) .missing(1.0)) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取結果。 PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } //使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); PercentilesAggregation aggregation = new PercentilesAggregation(); aggregation.setAggName("percentilesAgg"); aggregation.setFieldName("latency"); aggregation.setPercentiles(Arrays.asList(25.0d, 50.0d, 99.0d)); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // AggregationBuilders.percentiles("percentilesAgg", "latency").percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)).missing(1.0).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取結果。 PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } }
欄位值分組
根據一個欄位的值對查詢結果進行分組,相同的欄位值放到同一分組內,返回每個分組的值和該值對應的個數。
按欄位值分組是並行計算,屬於非精確統計,可能會存在少量誤差。
要實現多欄位分組,您可以通過嵌套分組或者多欄位分組方式實現。關於兩種實現方式的功能對比,請參見附錄:多欄位分組不同實現方式對比。
參數
參數
說明
groupByName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long、Double、Boolean、Keyword 和 Date 類型。
groupBySorter
分組中的 item 定序,預設按照分組中 item 的數量降序排序,多個排序則按照添加的順序進行排列。支援的排序類型如下。
groupKeySortInAsc:按照值的字典序升序排列。
groupKeySortInDesc:按照值的字典序降序排列。
rowCountSortInAsc:按照行數升序排列。
rowCountSortInDesc(預設):按照行數降序排列。
subAggSortInAsc:按照子統計彙總結果中值升序排列。
subAggSortInDesc:按照子統計彙總結果中值降序排列。
size
返回的分組數量。預設值為10,最大值為2000。
subAggregations
子統計彙總,對每個分組內的資料進行彙總計算(如最大值、和、平均值等)。
subGroupBys
子分組,在父級分組結果的基礎上,對分組內的資料進行二次分組操作。
樣本
按單欄位分組
/** * 所有商品中每一個類別各有多少個,且統計每一個類別的價格最大值和最小值。 * 返回結果舉例:"水果:5 個(其中價格的最大值為 15,最小值為 3),洗漱用品:10 個(其中價格的最大值為 98,最小值為 1),電子裝置:3 個(其中價格的最大值為 8699,最小值為 2300),其它:15 個(其中價格的最大值為 1000,最小值為 80)"。 */ public void groupByField(SyncClient client) { //使用 builder 模式構建查詢語句。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //如果只關心統計彙總結果,不關心具體資料,您可以將 limit 設定為 0 來提高效能。 .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //列印值。 System.out.println(item.getKey()); //列印個數。 System.out.println(item.getRowCount()); //列印價格的最小值。 System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //列印價格的最大值。 System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } //使用非 builder 模式構建查詢語句。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //下述注釋的 builder 寫法等效於上述 TermQuery 構建寫法。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); GroupByField groupByField = new GroupByField(); groupByField.setGroupByName("name1"); groupByField.setFieldName("column_type"); //設定子統計彙總。 MinAggregation minAggregation = AggregationBuilders.min("subName1", "column_price").build(); MaxAggregation maxAggregation = AggregationBuilders.max("subName2", "column_price").build(); groupByField.setSubAggregations(Arrays.asList(minAggregation, maxAggregation)); //下述注釋的 builder 寫法等效於上述 aggregation 構建寫法。 // GroupByBuilders.groupByField("name1", "column_type") // .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) // .addSubAggregation(AggregationBuilders.max("subName2", "column_price").build()); List<GroupBy> groupByList = new ArrayList<GroupBy>(); groupByList.add(groupByField); searchQuery.setGroupByList(groupByList); searchRequest.setSearchQuery(searchQuery); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //列印值。 System.out.println(item.getKey()); //列印個數。 System.out.println(item.getRowCount()); //列印價格的最小值。 System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //列印價格的最大值。 System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } }通過欄位分組嵌套進行多欄位分組
/** * 按照嵌套多欄位分組的樣本。 * 多元索引支援通過嵌套使用兩個 groupBy 實現與 SQL 中的 groupBy 多欄位相似的功能。 * 等效的 SQL 陳述式是 select a,d, sum(b),sum(c) from user group by a,d。 */ public void GroupByMultiField(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) //設定為 false 時,指定 addColumnsToGet,效能會高。 //.addColumnsToGet("col_1","col_2") .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) //此處相當於 SQL 中的 where 條件,可以通過 QueryBuilders.bool() 巢狀查詢實現複雜的查詢。 .addGroupBy( GroupByBuilders .groupByField("任意唯一名字標識_1", "field_a") .size(20) .addSubGroupBy( GroupByBuilders .groupByField("任意唯一名字標識_2", "field_d") .size(20) .addSubAggregation(AggregationBuilders.sum("任意唯一名字標識_3", "field_b")) .addSubAggregation(AggregationBuilders.sum("任意唯一名字標識_4", "field_c")) ) ) .build()) .build(); SearchResponse response = client.search(searchRequest); //查詢合格行。 List<Row> rows = response.getRows(); //擷取統計彙總結果。 GroupByFieldResult groupByFieldResult1 = response.getGroupByResults().getAsGroupByFieldResult("任意唯一名字標識_1"); for (GroupByFieldResultItem resultItem : groupByFieldResult1.getGroupByFieldResultItems()) { System.out.println("field_a key:" + resultItem.getKey() + " Count:" + resultItem.getRowCount()); //擷取子統計彙總結果。 GroupByFieldResult subGroupByResult = resultItem.getSubGroupByResults().getAsGroupByFieldResult("任意唯一名字標識_2"); for (GroupByFieldResultItem item : subGroupByResult.getGroupByFieldResultItems()) { System.out.println("field_a " + resultItem.getKey() + " field_d key:" + item.getKey() + " Count:" + item.getRowCount()); double sumOf_field_b = item.getSubAggregationResults().getAsSumAggregationResult("任意唯一名字標識_3").getValue(); double sumOf_field_c = item.getSubAggregationResults().getAsSumAggregationResult("任意唯一名字標識_4").getValue(); System.out.println("sumOf_field_b:" + sumOf_field_b); System.out.println("sumOf_field_c:" + sumOf_field_c); } } }按欄位分組時使用統計彙總排序
/** * 使用統計彙總排序的樣本。 * 使用方法:按順序添加 GroupBySorter 即可,添加多個 GroupBySorter 時排序結果按照添加順序生效。GroupBySorter 支援升序和降序兩種方式。 * 預設排序是按照行數降序排列,即 GroupBySorter.rowCountSortInDesc()。 */ public void groupByFieldWithSort(SyncClient client) { //構建查詢語句。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") //.addGroupBySorter(GroupBySorter.subAggSortInAsc("subName1")) //按照子統計彙總結果中的值升序排序。 .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) //按照統計彙總結果中的值升序排序。 //.addGroupBySorter(GroupBySorter.rowCountSortInDesc()) //按照統計彙總結果中的行數降序排序。 .size(20) .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); }
分組嵌套
分組類型的統計彙總功能支援嵌套操作,允許在父級分組結果的基礎上,進一步添加子級的統計彙總。
為了綜合考慮效能、複雜度等因素,嵌套層級僅開放至一定層數,詳情請參見多元索引使用限制。
情境案例
多級分組(GroupBy + SubGroupBy)
對資料進行第一層級分組後,再進行第二層級分組。例如,先按省份進行分組,然後再按城市分組,以擷取每個省份下各個城市的資料。
分組後彙總計算(GroupBy + SubAggregation)
在對資料進行第一層級的分組後,對每個分組內的資料進行彙總計算(如最大值、平均值等)。例如,在對資料進行省份分組後,擷取每個省份分組內某一指標的最大值。
樣本
以下樣本用於按照省份和城市進行嵌套分組,並計算各省份的訂單總數以及各城市的訂單總數和最大訂單金額。
public static void subGroupBy(SyncClient client) { //構建查詢語句。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()).limit(20) //第一層級分組:按照省份分組,統計省份訂單ID的行數(即省份訂單總數)。 //第二層級分組:按照城市分組,統計城市訂單ID的行數(即城市訂單總數)、計算城市最大的訂單金額。 .addGroupBy(GroupByBuilders.groupByField("provinceName", "province") .addSubAggregation(AggregationBuilders.count("provinceOrderCounts", "order_id")) .addGroupBySorter(GroupBySorter.rowCountSortInDesc()) .addSubGroupBy(GroupByBuilders.groupByField("cityName", "city") .addSubAggregation(AggregationBuilders.count("cityOrderCounts", "order_id")) .addSubAggregation(AggregationBuilders.max("cityMaxAmount", "order_amount")) .addGroupBySorter(GroupBySorter.subAggSortInDesc("cityMaxAmount")))) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取第一層級分組(各省份的訂單總數) GroupByFieldResult results = resp.getGroupByResults().getAsGroupByFieldResult("provinceName"); for (GroupByFieldResultItem item : results.getGroupByFieldResultItems()) { System.out.println("省份:" + item.getKey() + "\t訂單總數:" + item.getSubAggregationResults().getAsCountAggregationResult("provinceOrderCounts").getValue()); //擷取第二層級分組(各城市的訂單總數和最大訂單金額) GroupByFieldResult subResults = item.getSubGroupByResults().getAsGroupByFieldResult("cityName"); for (GroupByFieldResultItem subItem : subResults.getGroupByFieldResultItems()) { System.out.println("\t(城市)" + subItem.getKey() + "\t訂單總數:" + subItem.getSubAggregationResults().getAsCountAggregationResult("cityOrderCounts").getValue() + "\t最大訂單金額:" + subItem.getSubAggregationResults().getAsMaxAggregationResult("cityMaxAmount").getValue()); } } }
多欄位分組
根據多個欄位對查詢結果進行分組,支援使用 token 進行翻頁。
參數
參數
說明
groupByName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
sources
多列分組彙總欄位對象,最多支援設定 32 列。支援的分組類型如下:
GroupByField:欄位值分組,支援設定 groupByName、fieldName 和 groupBySorter 參數。
GroupByHistogram:長條圖統計,支援設定 groupByName、fieldName、interval 和 groupBySorter 參數。
GroupByDateHistogram:日期長條圖統計,支援設定 groupByName、fieldName、interval、timeZone 和 groupBySorter 參數。
重要sources 內分組專案僅支援按分組值(groupKeySort)的字典序進行排列,預設降序排序。
當某一列的欄位值不存在時,返回結果中的值將為 NULL。
nextToken
分頁查詢憑證,用於擷取下一頁資料。預設值為空白。
首次請求,需將nextToken設定為空白。如果一次請求未返回全部合格資料,則返回結果中的nextToken參數值不為空白,您可使用nextToken進行翻頁查詢。
說明如果需要對nextToken進行持久化或將其傳輸至前端頁面,建議使用Base64編碼將nextToken編碼為字串後進行儲存或傳輸。nextToken本身並不是字串,如果直接使用new String(nextToken)進行編碼,將導致token資訊的丟失。
size
返回的分組數量。預設值為10,最大值為2000。
重要如果需要限制返回的分組數量,一般情況下只需配置 size 參數。
不支援同時配置 size 和 suggestedSize 參數
suggestedSize
返回分組的數量。可設定為大於服務端最大限制的值或-1, 服務端按實際能力返回實際行數。
如果該參數的取值超過了服務端的最大值限制,則將被修正為最大值。實際返回的分組結果數量為min(suggestedSize, 服務端分組數量限制, 總分組數量)。
重要適用於對接例如 Spark、Presto 等計算引擎的高吞吐情境。
subAggregations
子統計彙總,對每個分組內的資料進行彙總計算(如最大值、和、平均值等)。
subGroupBys
子分組,在父級分組結果的基礎上,對分組內的資料進行二次分組操作。
重要GroupByComposite 不支援作為 subGroupBy。
樣本
/** * 組合類別型分組彙總:根據傳入的多個 SourceGroupBy(支援 groupbyField、groupByHistogram 和 groupByDataHistogram)進行分組彙總。 * 多列的彙總返回結果以扁平化結構返回。 */ public static void groupByComposite(SyncClient client) { GroupByComposite.Builder compositeBuilder = GroupByBuilders .groupByComposite("groupByComposite") .size(2000) .addSources(GroupByBuilders.groupByField("groupByField", "Col_Keyword") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()).build()) .addSources(GroupByBuilders.groupByHistogram("groupByHistogram", "Col_Long") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5) .build()) .addSources(GroupByBuilders.groupByDateHistogram("groupByDateHistogram", "Col_Date") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5, DateTimeUnit.DAY) .timeZone("+05:30").build()); SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .returnAllColumnsFromIndex(true) .searchQuery(SearchQuery.newBuilder() .addGroupBy(compositeBuilder.build()) .build()) .build(); SearchResponse resp = client.search(searchRequest); while (true) { if (resp.getGroupByResults() == null || resp.getGroupByResults().getResultAsMap().size() == 0) { System.out.println("groupByComposite Result is null or empty"); return; } GroupByCompositeResult result = resp.getGroupByResults().getAsGroupByCompositeResult("groupByComposite"); if(!result.getSourceNames().isEmpty()) { for (String sourceGroupByNames: result.getSourceNames()) { System.out.printf("%s\t", sourceGroupByNames); } System.out.print("rowCount\t\n"); } for (GroupByCompositeResultItem item : result.getGroupByCompositeResultItems()) { for (String value : item.getKeys()) { String val = value == null ? "NULL" : value; System.out.printf("%s\t", val); } System.out.printf("%d\t\n", item.getRowCount()); } // 利用 token 繼續翻頁擷取後續分組。 if (result.getNextToken() != null) { searchRequest.setSearchQuery( SearchQuery.newBuilder() .addGroupBy(compositeBuilder.nextToken(result.getNextToken()).build()) .build() ); resp = client.search(searchRequest); } else { break; } } }
範圍分組
根據一個欄位的範圍對查詢結果進行分組,欄位值在某範圍內放到同一分組內,返回每個範圍中相應的 item 個數。
參數
參數
說明
groupByName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long 和 Double 類型。
range[double_from, double_to)
分組的範圍。
起始值 double_from 可以使用最小值 Double.MIN_VALUE,結束值 double_to 可以使用最大值 Double.MAX_VALUE。
subAggregation 和 subGroupBy
子統計彙總,子統計彙總會根據分組內容再進行一次統計彙總分析。
例如按銷量分組後再按省份分組,即可獲得某個銷量範圍內哪個省比重比較大,實現方法是 GroupByRange 下添加一個 GroupByField。
樣本
/** * 求商品銷量時按 [0,1000)、[1000,5000)、[5000,Double.MAX_VALUE) 這些分組計算每個範圍的銷量。 */ public void groupByRange(SyncClient client) { //構建查詢語句。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByRange("name1", "column_number") .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name1").getGroupByRangeResultItems()) { //列印個數。 System.out.println(item.getRowCount()); } }
地理位置分組
根據距離某一個中心點的範圍對查詢結果進行分組,距離差值在某範圍內放到同一分組內,返回每個範圍中相應的 item 個數。
參數
參數
說明
groupByName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Geo_point 類型。
origin(double lat, double lon)
起始中心點的經緯度。
double lat 是起始中心點緯度,double lon 是起始中心點經度。
range[double_from, double_to)
分組的範圍,單位為米。
起始值 double_from 可以使用最小值 Double.MIN_VALUE,結束值 double_to 可以使用最大值 Double.MAX_VALUE。
subAggregation 和 subGroupBy
子統計彙總,子統計彙總會根據分組內容再進行一次統計彙總分析。
樣本
/** * 求距離萬達廣場 [0,1000)、[1000,5000)、[5000,Double.MAX_VALUE) 這些範圍內的人數,距離的單位為米。 */ public void groupByGeoDistance(SyncClient client) { //構建查詢語句。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByGeoDistance("name1", "column_geo_point") .origin(3.1, 6.5) .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //擷取統計彙總結果。 for (GroupByGeoDistanceResultItem item : resp.getGroupByResults().getAsGroupByGeoDistanceResult("name1").getGroupByGeoDistanceResultItems()) { //列印個數。 System.out.println(item.getRowCount()); } }
過濾條件分組
按照過濾條件對查詢結果進行分組,擷取每個過濾條件匹配到的數量,返回結果的順序和添加過濾條件的順序一致。
參數
參數
說明
groupByName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
filter
過濾條件,返回結果的順序和添加過濾條件的順序一致。
subAggregation 和 subGroupBy
子統計彙總,子統計彙總會根據分組內容再進行一次統計彙總分析。
樣本
/** * 按照過濾條件進行分組,例如添加三個過濾條件(銷量大於 100、產地是浙江省、描述中包含杭州關鍵詞),然後擷取每個過濾條件匹配到的數量。 */ public void groupByFilter(SyncClient client) { //構建查詢語句。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByFilter("name1") .addFilter(QueryBuilders.range("number").greaterThanOrEqual(100)) .addFilter(QueryBuilders.term("place","浙江省")) .addFilter(QueryBuilders.match("text","杭州")) ) .build()) .build(); //執行查詢。 SearchResponse resp = client.search(searchRequest); //按照過濾條件的順序擷取的統計彙總結果。 for (GroupByFilterResultItem item : resp.getGroupByResults().getAsGroupByFilterResult("name1").getGroupByFilterResultItems()) { //列印個數。 System.out.println(item.getRowCount()); } }
長條圖統計
按照指定資料間隔對查詢結果進行分組,欄位值在相同範圍內放到同一分組內,返回每個分組的值和該值對應的個數。
參數
參數
說明
groupByName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Long 和 Double 類型。
interval
統計間隔。
fieldRange[min,max]
統計範圍,與 interval 參數配合使用限制分組的數量。
(fieldRange.max-fieldRange.min)/interval的值不能超過 2000。minDocCount
最小行數。當分組中的行數小於最小行數時,不會返回此分組的統計結果。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
樣本
/** * 統計不同年齡段使用者數量分布情況。 */ public static void groupByHistogram(SyncClient client) { //構建查詢語句。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .addGroupBy(GroupByBuilders .groupByHistogram("groupByHistogram", "age") .interval(10) .minDocCount(0L) .addFieldRange(0, 99)) .build()) .build(); //執行查詢。 SearchResponse resp = ots.search(searchRequest); //擷取長條圖的統計彙總結果。 GroupByHistogramResult results = resp.getGroupByResults().getAsGroupByHistogramResult("groupByHistogram"); for (GroupByHistogramItem item : results.getGroupByHistogramItems()) { System.out.println("key:" + item.getKey().asLong() + " value:" + item.getValue()); } }
日期長條圖統計
對日期欄位類型的資料按照指定間隔對查詢結果進行分組,欄位值在相同範圍內放到同一分組內,返回每個分組的值和該值對應的個數。
Tablestore Java SDK 從 5.16.1 版本開始支援此功能。關於 Java SDK 歷史迭代版本的更多資訊,請參見 Java SDK 歷史迭代版本。
參數
參數
說明
groupByName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
fieldName
用於統計彙總的欄位,僅支援 Date 類型。
重要Table Store Java SDK 版本從 5.13.9 版本開始支援多元索引 Date 類型。
interval
統計間隔。
fieldRange[min,max]
統計範圍,與 interval 參數配合使用限制分組的數量。
(fieldRange.max-fieldRange.min)/interval的值不能超過 2000。minDocCount
最小行數。當分組中的行數小於最小行數時,不會返回此分組的統計結果。
missing
當某行資料中的欄位為空白時,欄位值的預設值。
如果未設定 missing 值,則在統計彙總時會忽略該行。
如果設定了 missing 值,則使用 missing 值作為欄位值的預設值參與統計彙總。
timeZone
時區。格式為
+hh:mm或者-hh:mm,例如+08:00、-09:00。只有當欄位資料類型為 Date 時才需要配置。當 Date 類型欄位的 Format 未設定時區資訊時,可能會導致彙總結果存在 N 小時的位移,此時請設定 timeZone 來解決該問題。
樣本
/** * 統計 2017-05-01 10:00 到 2017-05-21 13:00:00 時間段內每天的 col_date 資料分布情況。 */ public static void groupByDateHistogram(SyncClient client) { //構建查詢語句。 SearchRequest searchRequest = SearchRequest.newBuilder() .returnAllColumns(false) .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .getTotalCount(false) .addGroupBy(GroupByBuilders .groupByDateHistogram("groupByDateHistogram", "col_date") .interval(1, DateTimeUnit.DAY) .minDocCount(1) .missing("2017-05-01 13:01:00") .fieldRange("2017-05-01 10:00", "2017-05-21 13:00:00")) .build()) .build(); //執行查詢。 SearchResponse resp = ots.search(searchRequest); //擷取長條圖的統計彙總結果。 List<GroupByDateHistogramItem> items = resp.getGroupByResults().getAsGroupByDateHistogramResult("groupByDateHistogram").getGroupByDateHistogramItems(); for (GroupByDateHistogramItem item : items) { System.out.printf("millisecondTimestamp:%d, count:%d \n", item.getTimestamp(), item.getRowCount()); } }
擷取統計彙總分組中的行
對查詢結果進行分組後,擷取每個分組內的一些行資料,可實現和 MySQL 中 ANY_VALUE(field) 類似的功能。
擷取統計彙總分組中的行時,如果多元索引中包含巢狀型別、地理位置類型或者數群組類型的欄位,則返回結果中只會包含主鍵資訊,請手動反查資料表擷取所需欄位。
參數
參數
說明
aggregationName
自訂的統計彙總名稱,用於區分不同的統計彙總,可根據此名稱擷取本次統計彙總結果。
limit
每個分組內最多返回的資料行數,預設返回1行資料。
sort
分組內資料的排序方式。
columnsToGet
指定返回的欄位,僅支援多元索引中的欄位,且不支援數組、Date、Geopoint 和 Nested 類型的欄位。
該參數複用 SearchRequest 中的 columnsToGet 參數,在 SearchRequest 中指定 columnsToGet 即可。
樣本
/** * 某學校有一個活動報名表,活動報名表中包含學生姓名、班級、班主任、班長等資訊,如果希望按班級進行分組,以查看每個班級的報名情況,同時擷取班級的屬性資訊。 * 等效的 SQL 陳述式是 select className, teacher, monitor, COUNT(*) as number from table GROUP BY className。 */ public void testTopRows(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders.groupByField("groupName", "className") .size(5) //返回的分組數量,最大值請參見“多元索引使用限制”文檔中的限制性“GroupByField 返回的分組個數”。 .addSubAggregation(AggregationBuilders.topRows("topRowsName") .limit(1) .sort(new Sort(Arrays.asList(new FieldSort("teacher", SortOrder.DESC)))) // topRows 的排序。 ) ) .build()) .addColumnsToGet(Arrays.asList("teacher", "monitor")) .build(); SearchResponse resp = client.search(searchRequest); List<GroupByFieldResultItem> items = resp.getGroupByResults().getAsGroupByFieldResult("groupName").getGroupByFieldResultItems(); for (GroupByFieldResultItem item : items) { String className = item.getKey(); long number = item.getRowCount(); List<Row> topRows = item.getSubAggregationResults().getAsTopRowsAggregationResult("topRowsName").getRows(); Row row = topRows.get(0); String teacher = row.getLatestColumn("teacher").getValue().asString(); String monitor = row.getLatestColumn("monitor").getValue().asString(); } }
多個統計彙總
多個統計彙總功能可以組合使用。
當多個統計彙總的複雜度較高時可能會影響響應速度。
組合使用多個 Aggregation
public void multipleAggregation(SyncClient client) {
//構建查詢語句。
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.build())
.build();
//執行查詢。
SearchResponse resp = client.search(searchRequest);
//擷取求最小值的統計彙總結果。
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
//擷取求和的統計彙總結果。
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
//擷取去重統計行數的統計彙總結果。
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
}組合使用 Aggregation 和 GroupBy
public void multipleGroupBy(SyncClient client) {
//構建查詢語句。
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.addGroupBy(GroupByBuilders.groupByField("name4", "type"))
.addGroupBy(GroupByBuilders.groupByRange("name5", "long").addRange(1, 15))
.build())
.build();
//執行查詢。
SearchResponse resp = client.search(searchRequest);
//擷取求最小值的統計彙總結果。
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
//擷取求和的統計彙總結果。
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
//擷取去重統計行數的統計彙總結果。
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
//擷取按欄位值分組的統計彙總結果。
for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name4").getGroupByFieldResultItems()) {
//列印 key。
System.out.println(item.getKey());
//列印個數。
System.out.println(item.getRowCount());
}
//擷取按範圍分組的統計彙總結果。
for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name5").getGroupByRangeResultItems()) {
//列印個數。
System.out.println(item.getRowCount());
}
}附錄:多欄位分組不同實現方式對比
如果要根據多個欄位對查詢結果進行分組,您可以通過欄位分組嵌套(即嵌套多層 groupBy)或者多欄位分組(即直接使用 GroupByComposite)功能實現。具體實現方式的功能對比說明請參見下表。
功能對比 | 欄位分組嵌套 | 多欄位分組 |
size | 2000 | 2000 |
欄位列限制 | 最高支援 3 層 | 最高支援 32 列 |
翻頁 | 不支援 | 支援通過 GroupByComposite 中的 nextToken 翻頁 |
分組中 Item 定序 |
| 按照值的字典序升序或降序排列 |
是否支援子統計彙總 | 支援 | 支援 |
相容性 | 日期類型根據 Format 返回 | 日期類型返回時間戳記字串 |
相關文檔
您還可以通過以下查詢與分析表中資料。