添加Serverless Spark資料來源用於連通阿里雲Serverless Spark資料庫與Quick BI,串連成功後,您可以在Quick BI上進行資料的分析與展示。本文為您介紹如何添加阿里雲Serverless Spark資料來源。
前提條件
已建立阿里雲E-MapReduce Serverless Spark版資料庫,具體操作說明請參見EMR Serverless Spark。
操作步驟
添加白名單。
公網串連阿里雲Serverless Spark資料庫之前,需要將Quick BI的IP地址加入到阿里雲Serverless Spark資料庫的白名單中。添加阿里雲Serverless Spark資料庫白名單的操作請參見設定白名單。
登入Quick BI控制台。
從建立資料來源入口進入建立資料來源介面。
在阿里雲資料庫頁簽下,選擇 E-MapReduce Serverless Spark版 資料來源。
在配置串連對話方塊,您可以根據業務情境,完成以下配置。
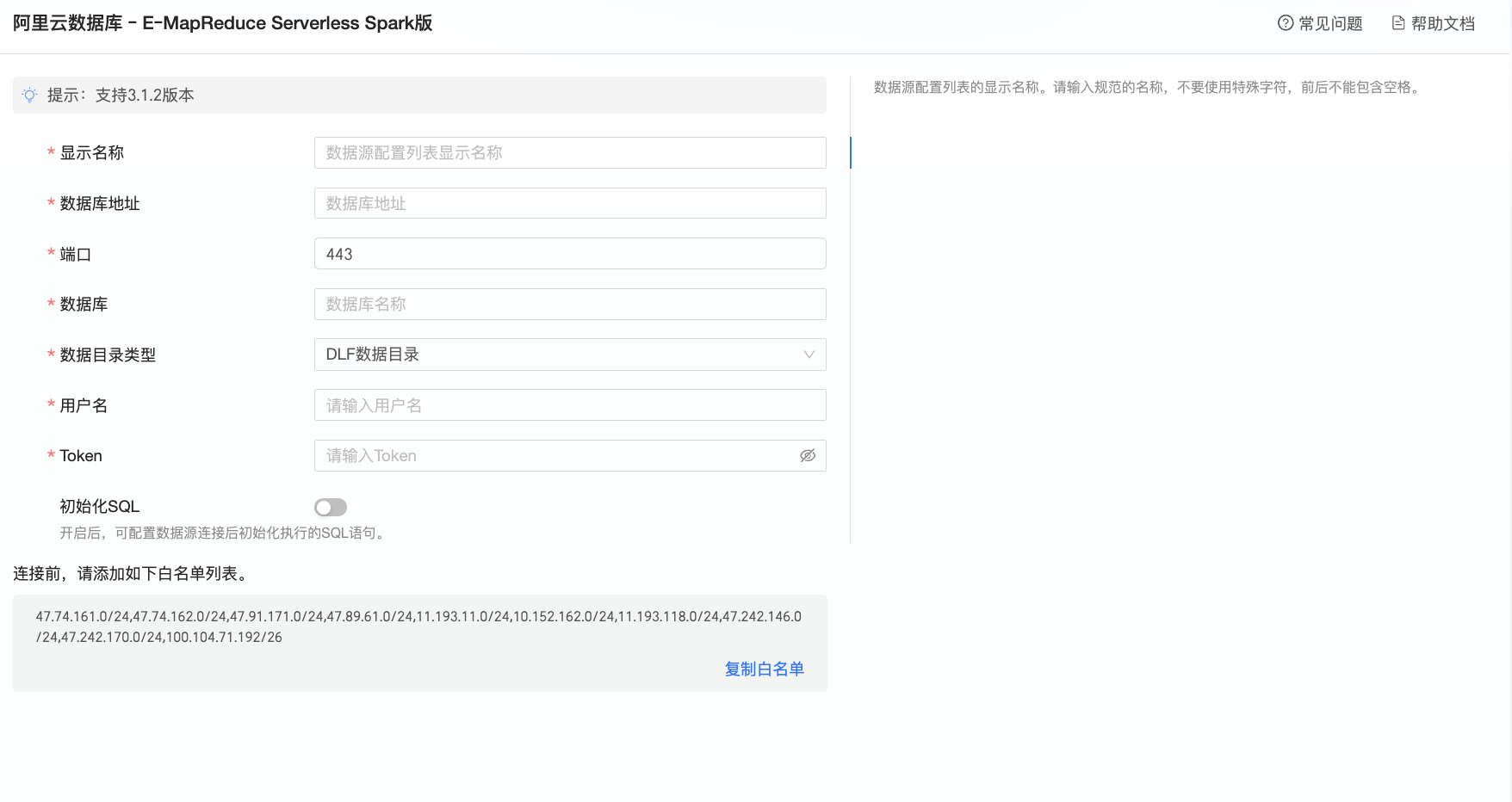
名稱
描述
顯示名稱
資料來源配置列表的顯示名稱。
請輸入規範的名稱,不要使用特殊字元,前後不能包含空格。
資料庫地址
訪問E-MapReduce Serverless Spark資料庫的公網地址(目前僅支援通過公網串連E-MapReduce Serverless Spark)。
請登入E-MapReduce管理主控台,在Kyuubi Gateway頁面的詳情總覽頁內,擷取endpoint。例:emr-xxxxxxxxxxxxxxxxx.aliyuncs.com。
連接埠
資料庫對應的連接埠號碼,預設為443.
資料庫
需要串連的資料庫名稱。
資料目錄類型
E-MapReduce Serverless Spark資料庫所在的資料目錄類型,支援選擇DLF資料目錄、其他。
使用者名稱/Token名稱
當資料目錄類型為DLF資料目錄時,您需要在此處填寫您在存取控制中添加的RAM使用者或RAM角色,使用前需提前進行授權。
說明請確保該使用者具備資料庫中表的create、insert、 update和delete許可權。具體操作說明請參見通過Kyuubi Token對DLF資料的許可權管控。
當資料目錄類型為其他時,您需要在此處填寫訪問EMR Serverless Spark資料庫的Token名稱。請登入E-MapReduce管理主控台,在Gateway頁面的Token頁內擷取名稱。
Token
訪問E-MapReduce Serverless Spark資料庫的Token。
請登入E-MapReduce管理主控台,在Gateway頁面的Token頁內,擷取Token。
初始化SQL
開啟後,可配置資料來源串連後初始化執行的SQL語句。
每次資料來源串連後初始化執行的SQL語句,只允許SET語句,語句之間以分號分割。
單擊串連測試,進行資料來源連通性測試。
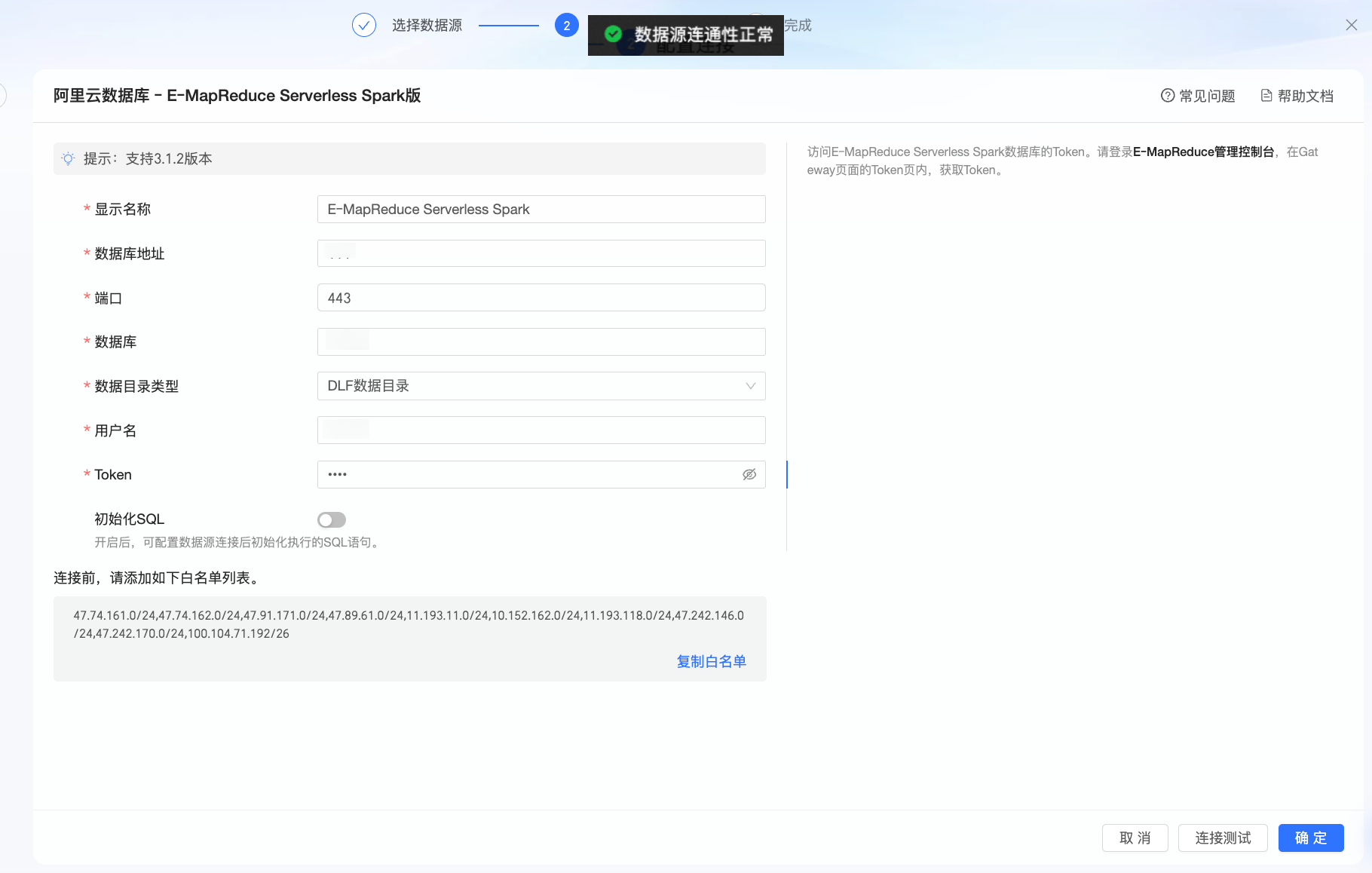
測試成功後,單擊確定,完成資料來源的添加。
後續步驟
建立資料來源後,您還可以建立資料集並分析資料。
將阿里雲Serverless Spark資料庫中的資料表或自建的自訂SQL添加到Quick BI,請參見建立資料集。
切入並深度分析資料,請參見步驟三:切入設定與展示。