本文為您介紹如何使用Kohya訓練LoRA模型。
點擊登入PAI ArtLab控制台。
背景資訊
Stable Diffusion(SD)是一個開源的深度學習文生圖模型。SD WebUI是SD的可視化介面,支援網頁端文生圖、圖生圖操作,並通過外掛程式和模型匯入實現高度定製化。
使用SD WebUI產生圖片需要使用多種模型,不同模型有各自的特色與適用領域,需要針對性地採用不同的訓練資料集及訓練策略進行培養。其中,LoRA是一種輕量化的模型微調方法,速度較快,檔案大小適中,對配置要求低。
Kohya是廣泛應用的LoRA模型訓練開源服務,Kohya's GUI程式包提供了訓練環境和模型訓練的使用者介面,避免與其他程式幹擾。SD WebUI也支援通過外掛程式進行模型訓練,但可能會產生幹擾,導致報錯 。
其他模型微調方法請參見PAI ArtLab 模型使用說明。
LoRA模型介紹
LoRA(Low-Rank Adaptation of Large Language Models)可以基於基本模型通過對資料集的訓練,得到一個風格化的模型,從而實現高度定製化的映像產生效果。
檔案規格如下:
檔案大小:通常為個位到百級MB,具體大小取決於受訓練參數與基本模型的複雜度。
檔案格式:採用.safetensors作為標準尾碼。
檔案應用:需與特定的Checkpoint基本模型結合使用。
檔案版本:需要明確區分Stable Diffusion v1.5與Stable Diffusion XL版本,各版本間模型不通用。
LoRA微調模型
如果將基本模型(如Stable Diffusion v1.5 Model、v2.1 Model或Stable Diffusion XL base 1.0 Model等)視作基礎原生態的自然食材,那麼LoRA模型則是某種特殊風味的調味料,旨在為這些食材賦予獨特的風味與創新。為了使料理具備多樣性和創新性,LoRA模型作為關鍵的創新催化劑,可以突破基本模型在創造過程中遭遇的局限性,使內容創作更加靈活高效,個性十足。
以Stable Diffusion v1.5模型為例,其局限性包括:
產生內容細節精準度缺失:在產生特定細節或複雜內容時,可能難以精準複現所有細節,導致產生映像缺乏細節或不夠逼真。
產生內容邏輯性構建不足:產生映像中的物體布局、尺寸比例及光影邏輯可能不符合現實規律。
產生內容風格不一致:高度複雜且隨機的產生過程,使得維持特定風格或執行風格轉移時,難以確保風格的統一與連貫。
當前模型生態社區已有眾多優秀的微調模型,此類模型均基於基本模型微調訓練產生。相較於原始基本模型,產生映像細節更豐富,風格特徵也更加鮮明,且產生內容更加可控。例如,下圖展示了Stable Diffusion v1.5模型和微調模型產生映像效果對比,可以直觀感受到映像產生品質的顯著提升。

LoRA模型的不同類型
LyCORIS(LoHa/LoCon的前身)
LyCORIS作為LoRA的增強版,能夠對26層的神經網路進行精細調整,相比LoRA僅支援17層的微調,在效能上顯著提升。因此,相較於LoRA,LyCORIS表現力更強,有更多的參數,可以承載更多的資訊量。LyCORIS的核心優勢在於LoHa與LoCon。其中,LoCon專註於針對SD模型的每一層級進行調整,而LoHa則在原基礎上實現雙倍資料資訊量。
用法和LoRA相同,進階用法可以通過調整文本編碼的權重、Unet的權重和DyLoRa的權重實現。
LoCon
LoRA(Conventional LoRA)只調整了cross-attention layers,LoCon用同樣的方法調整了ResNet矩陣。目前LoCon已經被LyCORIS合并,過去擴充的LoCon已經不再需要。更多資訊,參見 LoCon-LoRA for Convolution Network。
LoHa
LoHa(LoRA with Hadamard Product)用Hadamard Product替換了原方法中的矩陣點乘,理論上在相同的情況下能容納更多資訊。更多資訊,請參見FedPara Low-Rank Hadamard Product For Communication-Efficient Federated Learning。
DyLoRA
LoRA的rank並非越高越好,其最優值需依據具體模型、資料集特性和所執行任務共同決定。DyLoRA能夠在指定維度(rank)下靈活探索並學習多種rank的LoRA配置,簡化了尋找最適rank的複雜度,從而提升了模型調優的效率與精準度。
準備資料集
確定LoRA類型
首先您需要確定希望訓練的LoRA模型的類型,比如是角色類型還是風格類型。
例如,需要訓練一個阿里雲進化設計語言體系下的阿里雲3D產品表徵圖風格的風格模型。
資料集內容要求
資料集由圖片和圖片對應的文本描述標註兩種檔案組成。
準備資料集內容:圖片
圖片要求
數量:15張以上。
品質:解析度適中,畫質清晰。
風格:需要一套風格統一的圖片內容。
內容:圖片需凸顯要訓練的主體物形象,不宜有複雜背景以及其他無關的內容,尤其是文字。
尺寸:解析度是64的倍數,範圍為512~768。顯存低可以裁剪為512*512,顯存高可以裁剪為768*768。
圖片預先處理
品質調整:圖片解析度適中,保證畫質清晰即可。如果圖片解析度較小,可以使用SD WebUI中Extras或影像處理工具進行解析度放大。
尺寸調整:可以使用批量裁剪工具進行裁剪。
圖片部分準備完畢樣本
將圖片存放至本地檔案夾中。

建立資料集並上傳檔案
上傳前需要注意檔案的屬性和命名要求,如果只是用平台管理資料集檔案或者給圖片打標,直接上傳檔案或檔案夾都可以,對這些檔案和檔案夾的命名沒有特殊要求。
如果資料集打標完之後,需要用平台的Kohya做LoRA模型訓練,對於上傳的檔案屬性和命名要求如下。
命名格式:數字+底線+任意名稱
命名含義:自訂。
數字:每張圖片重複訓練次數,一般要求≥100。總訓練次數一般要求>1500,因此若檔案夾內包含10張圖片,則每張圖片訓練1500/10=150次,圖片檔案夾名數字部分可為150;若檔案夾內包含20張圖片,則每張圖片訓練1500/20=75(<100)次,圖片檔案夾名數字部分可為100。
任意名稱:本文以100_ACD3DICON為例,您可以根據實際情況自訂。
登入PAI ArtLab,選擇Kohya(專享版),進入Kohya-SS頁面。
建立資料集
在資料集頁面,單擊建立資料集,並輸入資料集名稱,此處以acd3dicon為例。
上傳資料集檔案
單擊已建立的資料集,將整理好的資料集圖片檔案夾從本地拖拽上傳。
上傳成功。
進入到檔案夾裡可以查看到已上傳的圖片。
準備資料集內容:圖片標註
圖片標註是指每張圖片對應的文字描述,文字描述的標註檔案,是與圖片同名的TXT格式的檔案。
圖片標註要求
B端元素通常具備清晰的結構布局、規範的透視效果及特定的光影,因此在進行標註處理時,需要區別於人像、風景等類型的資料集影像處理方法。建議採取基礎的描繪打標,集中關注並標註元素的頂層、中層及底部的簡單幾何形態,如“球形”、“立方體”等。
分類
關鍵詞
業務
產品/業務
資料庫、雲安全、計算平台、容器、雲原生等(英文)
雲端運算元素
Data processing、Storage、Computing、Cloud computing、Elastic computing、Distributed storage、Cloud database、Virtualization、Containerization、Cloud security、Cloud architecture、Cloud services、Server、Load balancing、Automated management、Scalability、Disaster recovery、High availability、Cloud monitoring、Cloud billing
設計(質感)
環境&構圖
viewfinder、isometric、hdri environment、white background、negative space
材質
glossy texture、matte texture、metallic texture、glass texture、frosted glass texture
照明
studio lighting、soft lighting
色彩
alibaba cloud orange、white、black、gradient orange、transparent、silver
情緒
rational、orderly、energetic、vibrant
品質
UHD、accurate、high details、best quality、1080P、16k、8k
設計(氛圍)
...
...
給圖片添加標註
您可以手動為每張圖片添加對應的文字描述,但當圖片數量非常大時,手動打標非常耗時耗力,此時您可以選擇藉助神經網路,完成對所有圖片批量產生文本描述的工作,或者在Kohya中選擇使用BLIP的映像打標模型,搭配手動微調,滿足您的業務需求。
打標資料集
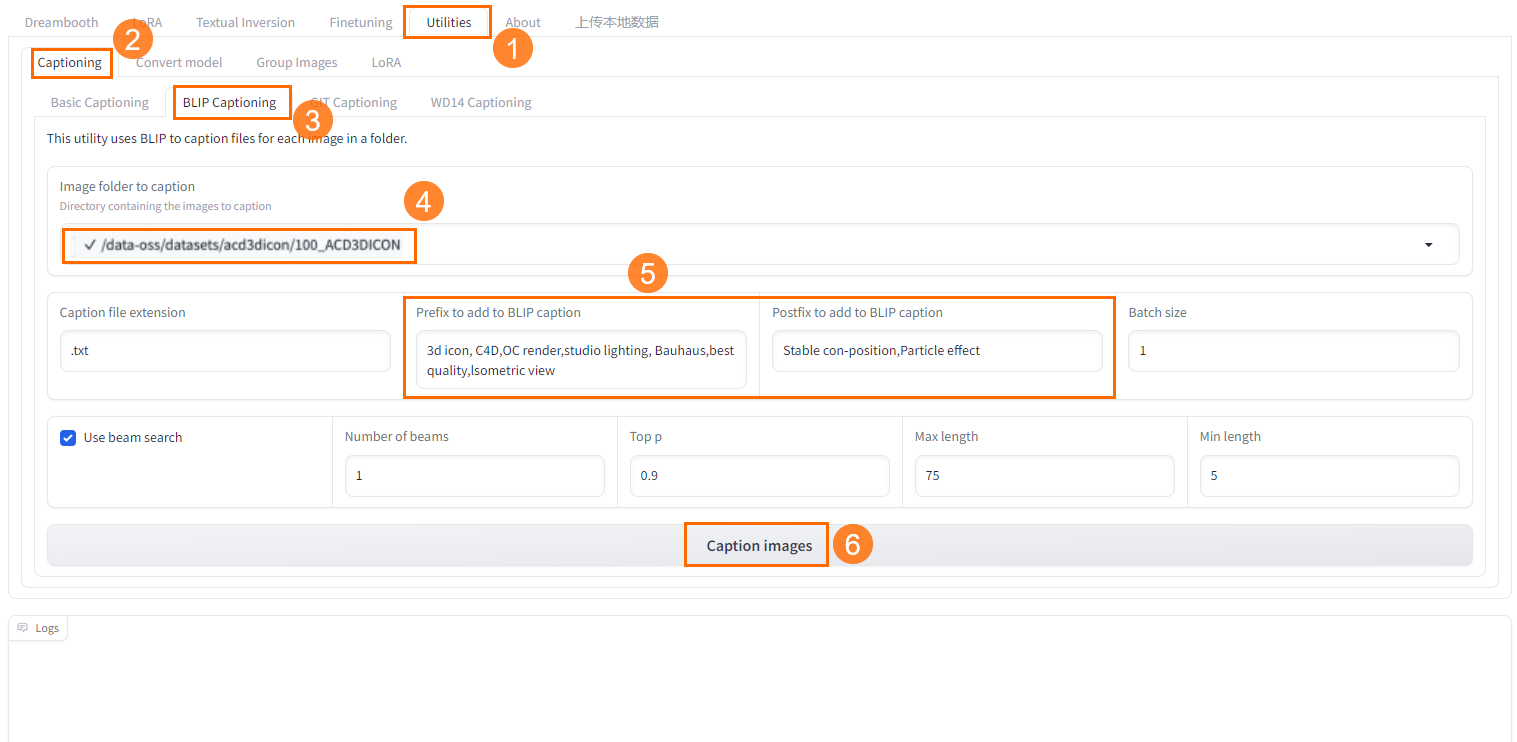
在Kohya-SS頁面,選擇Utilities>Captioning>BLIP Captioning。
選擇已建立的資料集中上傳的圖片檔案夾。
輸入一些預置詞,讓機器給每一張圖片都批量加上您輸入的標註文本。您可以結合自己對資料集圖片拆分的維度去添加預置詞,不同類型的圖片打標的維度也不同。
單擊Caption Image即可開始打標。
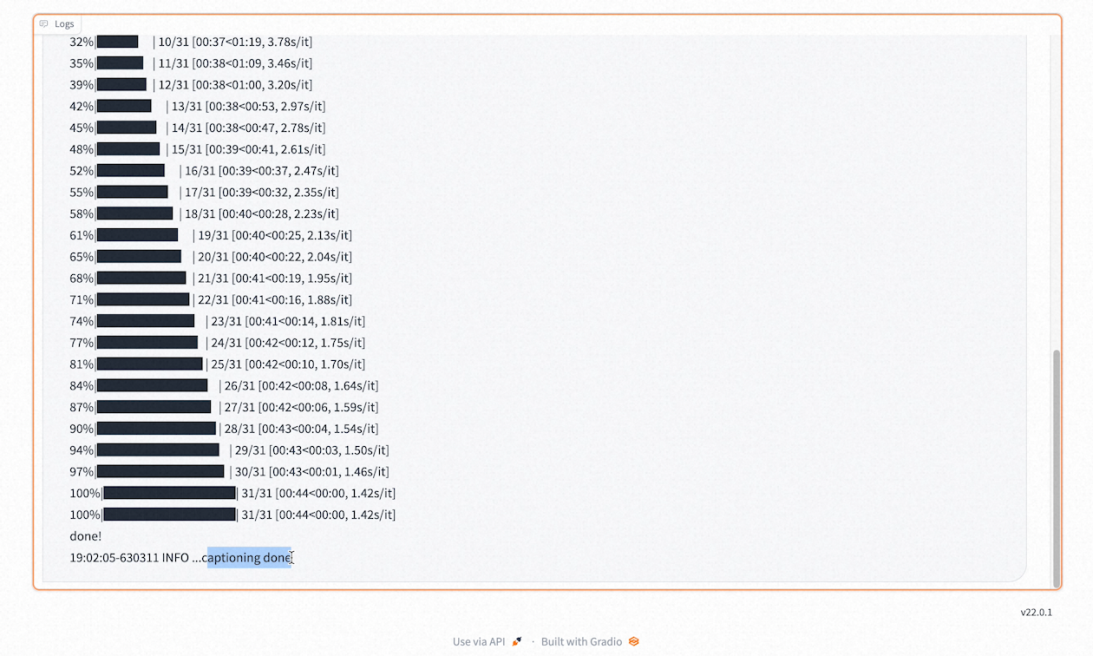
在下方的日誌裡可以查看打標的進度和打標完成的提示。
返回資料集,可以看到剛才上傳的圖片已經有對應的標註檔案。
(可選)對於不合適的標註,可以手動修改。
訓練LoRA模型
在Kohya-SS頁面,選擇LoRA(LoRA)>Training(訓練)>Source Model(模型來源)。
配置以下參數:
Model Quick Pick(快速選擇模型):runwayml/stable-diffusion-v1-5
Save trained model as(儲存訓練模型為):safetensors
說明如果Model Quick Pick(快速選擇模型)下拉選擇中沒有自己想要的模型,可以選擇custom之後再選擇模型。從模型廣場添加到我的模型的底模以及本地上傳到我的模型的底模,在custom路徑裡可以找到。
在Kohya-SS頁面,選擇LoRA(LoRA)>Training(訓練)>Folders(檔案夾)。
選擇已上傳了資料集檔案夾的資料集,並配置訓練參數。
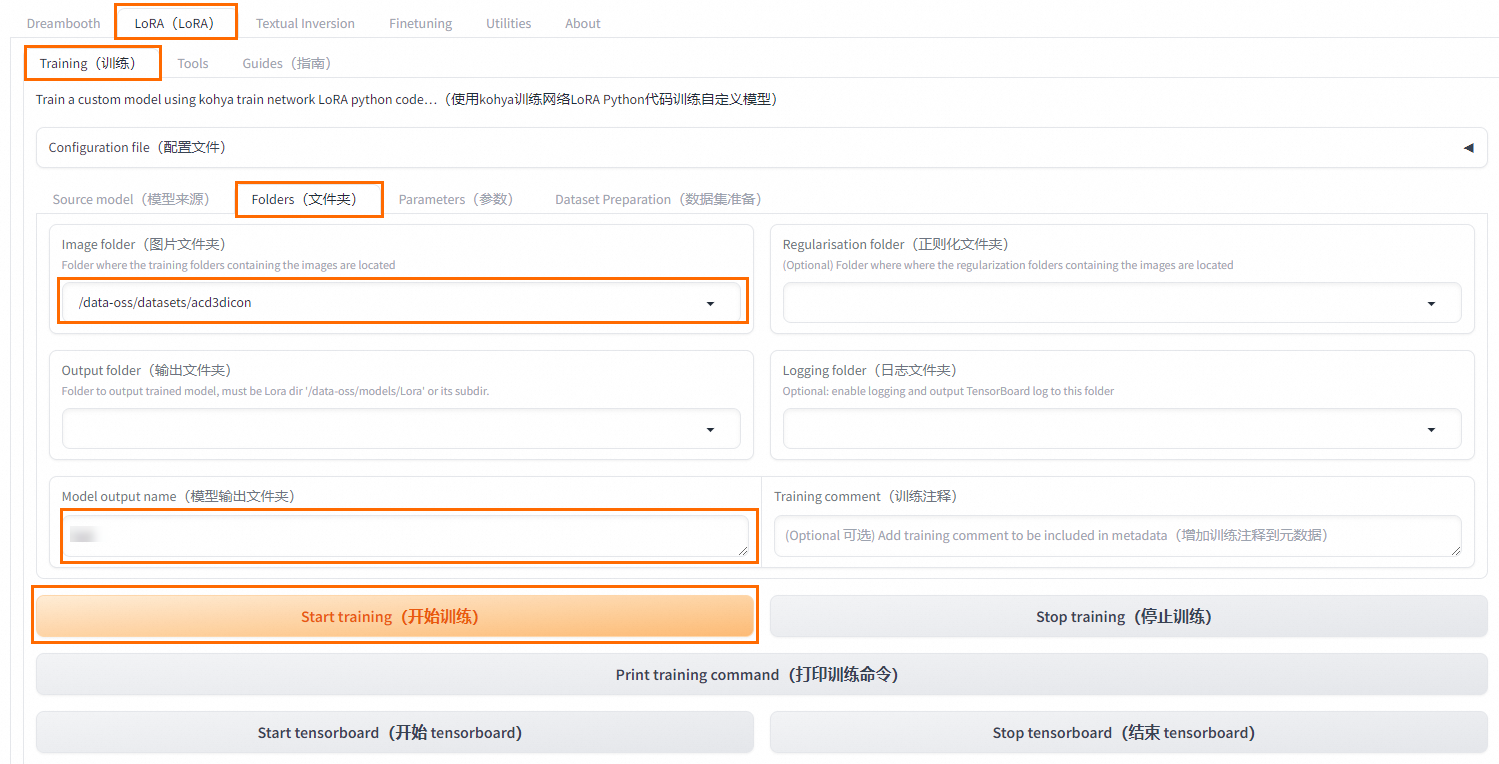 說明
說明資料集檔案打標時,要選到資料集下面圖片的檔案夾;做模型訓練時,要選擇放置資料集檔案夾的資料集。
單擊Start training,開始訓練。
更多參數資訊,請參見常用訓練參數介紹說明。
在下方的日誌裡可以查看模型訓練進度和模型訓練完成的提示。
常用訓練參數介紹說明
參數介紹
圖片數量*repeat數量*設定的epoch/batch_size=模型訓練總步數
例如,10張圖*20步*10個迴圈/2並行數=1000步。
在Kohya-SS頁面,選擇LoRA(LoRA)>Training(訓練)>Parameters(參數),即可配置模型訓練參數,常用參數說明如下:
Basic(基礎)頁簽
參數
功能
設定說明
repeat
讀取映像次數
在檔案夾命名時設定讀取映像的次數,次數越多學習效果越好。初期訓練時建議設定如下:
二次元:7~15
人像:20~30
實物:30~100
LoRA type
選擇LoRA類型
保持預設選擇Standard。
LoRA network weights
LoRA網路權重
選填。如果要接著訓練則選用最後訓練的LoRA。
Train batch size
訓練批量大小
根據顯卡效能選擇。12G顯存最大為2,8G顯存最大為1。
Epoch
訓練輪數,將所有資料訓練一次為一輪
自行計算。一般:
Kohya中總訓練次數=訓練圖片數量x重複次數x訓練輪數/訓練批量大小
WebUI中總訓練次數=訓練圖片數量x重複次數
使用類別映像時,在Kohya或在WebUI中總訓練次數都會乘2;在Kohya中模型儲存次數會減半。
Save every N epochs
每N個訓練周期儲存一次結果
如設為2,則每完成2輪訓練儲存一次訓練結果。
Caption Extension
打標副檔名
選填。 訓練圖集中註解/提示檔案的格式為.txt。
Mixed precision
混合精度
根據顯卡效能決定。取值如下:
no
fp16(預設)
bf16(RTX30以上顯卡可選bf16)
Save precision
儲存精度
根據顯卡效能決定。取值如下:
no
fp16(預設)
bf16(RTX30以上顯卡可選bf16)
Number of CPU threads per core
CPU每核線程數
主要根據CPU效能,根據所購執行個體和需求調整,保持預設即可。
Seed
隨機數種子
可以用於生圖驗證。
Cache latents
緩衝潛變數
預設開啟,訓練後映像資訊會緩衝為latens檔案。
LR Scheduler
學習率調度器
理論上沒有最佳學習點,為了能夠找到一個最佳的假設值,一般可以使用cosine(餘弦函數)。
Optimizer
最佳化器
預設AdamW8bit。如果基於sd1.5的基本模型訓練,保持預設值即可。
Learning rate
學習率
初期訓練時,建議設定學習率為0.01~0.001。預設值為0.0001。
可以根據損失函數(loss)調整學習率:當loss值偏高時,可以適度提升學習率;若loss值較低,可以逐步減少學習率有助於精細調優模型。
高學習率加速訓練但可能因學習粗糙引發過擬合,即模型對訓練資料過度適應而泛化能力差。
低學習率雖能細緻學習,減少過擬合,但可能導致訓練時間長和欠擬合,即模型簡化而未能把握資料特性。
LR Warmup(% of steps)
學習率預熱(%的步數)
預設值為10。
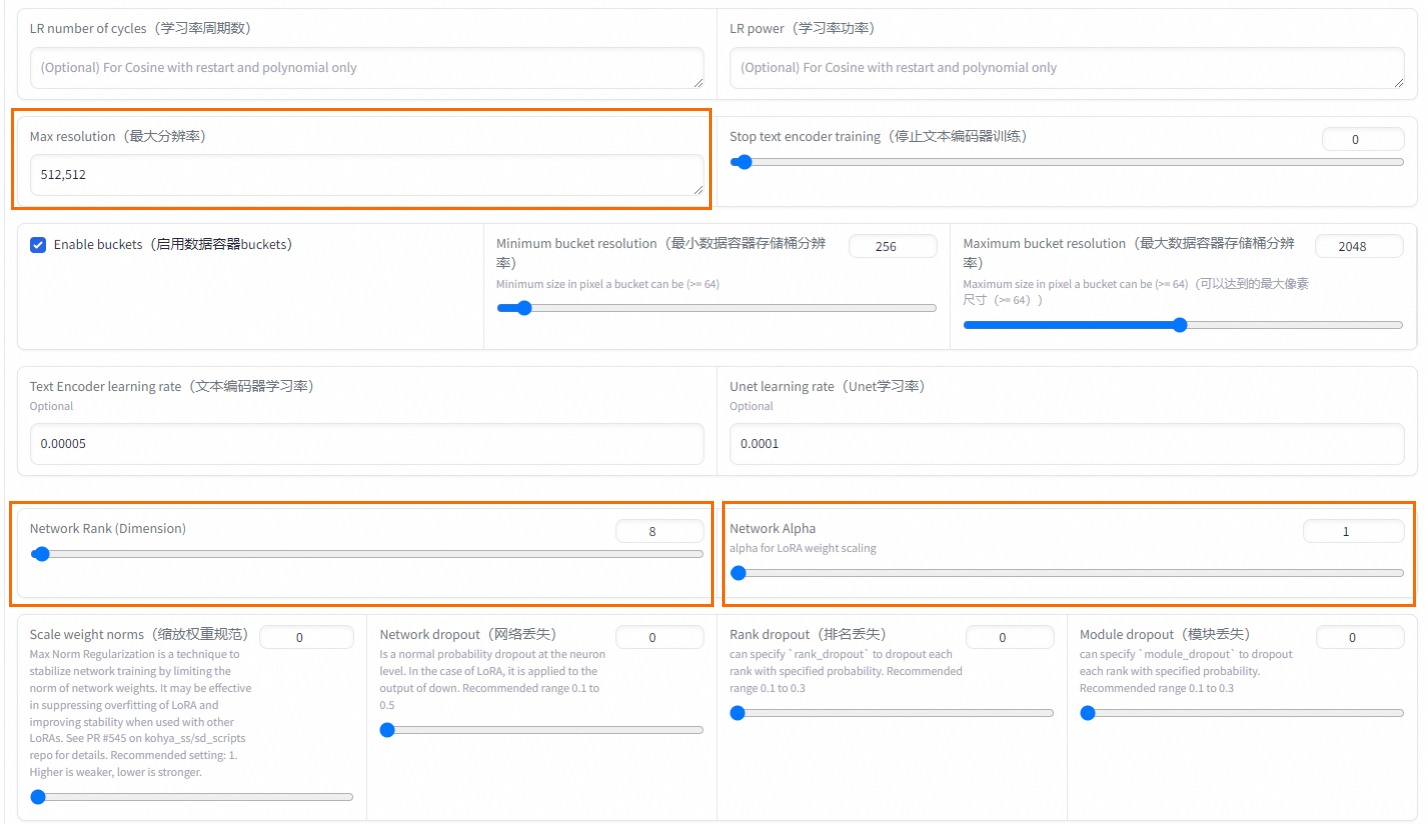
Max Resolution
最大解析度
根據圖片情況設定。預設值為512,512。
Network Rank (Dimension)
模型複雜度
一般設定為64即可適應大部分情境。
Network Alpha
網路Alpha
建議可以設定較小值,Rank和Alpha設定會影響最終輸出LoRA的大小。
Clip skip
文本編碼器跳過層數
二次元選2,寫實模型選1,動漫模型訓練最初就有跳過一層,如使用訓練素材也是二次元映像,再跳一層=2。
Sample every n epochs
每n個訓練周期採樣一次
每幾輪儲存一次樣本。
Sample prompts
樣本提示
提示詞樣本。需要使用命令,參數如下:
--n:反向提示詞。
--w:圖片寬度。
--h:圖片高度。
--d:映像種子。
--l:提示詞相關性(cfg比例)。
--s:迭代步數(steps)。
Advanced(增強)頁簽
參數
功能
設定說明
Clip skip
文本編碼器跳過層數
二次元選2,寫實模型選1,動漫模型訓練最初就有跳過一層,如使用訓練素材也是二次元映像,再跳一層=2。
Samples(範例)頁簽
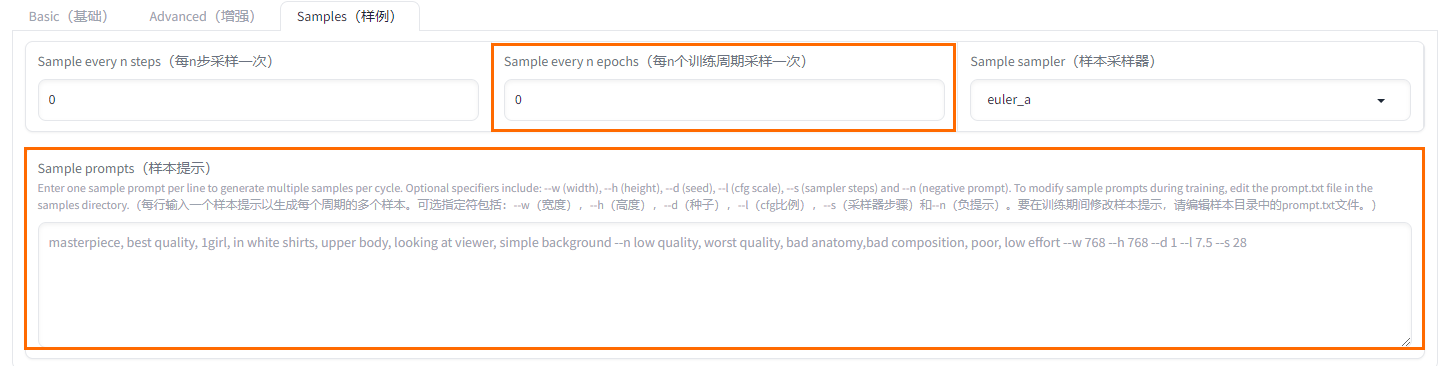
參數
功能
設定說明
Sample every N epochs
每N個訓練周期採樣一次
每幾輪儲存一次樣本。
Sample prompts
樣本提示
提示詞樣本。需要使用命令,參數如下:
--n:反向提示詞。
--w:圖片寬度。
--h:圖片高度。
--d:映像種子。
--l:提示詞相關性(cfg比例)。
--s:迭代步數(steps)。
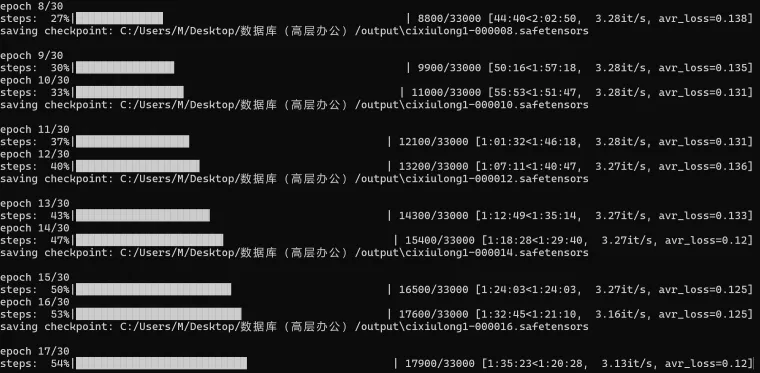
Loss值介紹
在微調模型訓練過程中(LoRA),Loss值可以算是一個比較重要的衡量模型優劣的指標。理想狀況下,隨著訓練的進程,Loss值應呈現逐漸下降的趨勢,這代表訓練過程機器正在有效學習並逐漸去貼合使用者提供的訓練資料。一般Loss值維持在0.08至0.1之間,表明模型訓練的結果較好,Loss值為0.08時,模型訓練的結果比較理想。
可以說LoRA學習就是Loss值從高到低的過程。假設訓練周期Epoch為30,如果目標是擷取Loss值位於0.09至0.07區間的模型,則有望在第20至24個Epoch之間實現這一目標。這樣設定可以避免因訓練輪次過少而導致的Loss快速驟降。例如,僅經歷兩輪訓練Loss就從0.1驟減至0.06,可能會錯到期望的Loss區間。