多模態資料管理支援通過大模型對圖片等資料進行智能打標和語義索引,實現資料搜尋、篩選和子集匯出,用於模型訓練和資料分析。
1. 概述
多模態資料管理通過多模態大模型和 Embedding 模型對圖片等資料進行智能打標和語義索引,產生中繼資料。基於這些中繼資料,您可以搜尋、篩選資料,快速挖掘特定情境的資料子集,用於資料標註和模型訓練。PAI 資料集還開放了全套 OpenAPI,便於在自建平台中整合。產品架構:
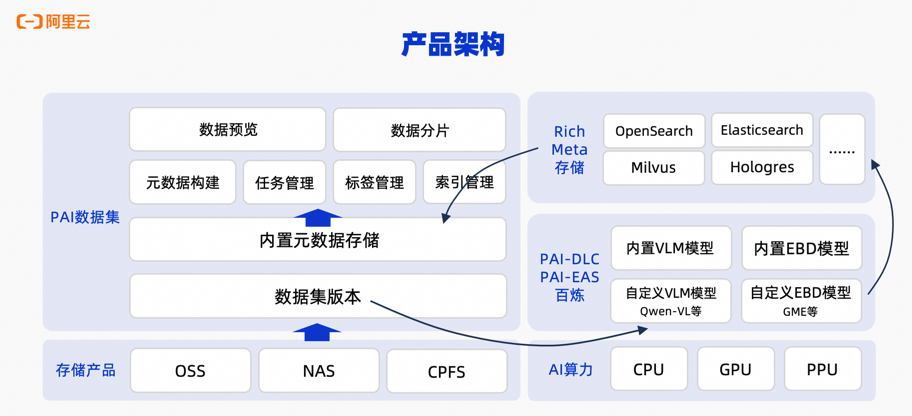
2. 使用限制
當前 PAI 多模態資料管理有以下使用限制:
-
使用地區:當前支援杭州、上海、深圳、烏蘭察布、北京、廣州、新加坡、德國、美國(維吉尼亞)、中國香港、東京、雅加達、廣州、美國(矽谷)、吉隆坡、首爾地區。
-
儲存類型:當前僅支援在OSS Object Storage Service中使用PAI多模態資料管理。
-
檔案類型:當前僅支援圖片類型檔案,支援檔案格式:jpg、 jpeg、png、gif、bmp、tiff、webp。
-
檔案數量:支援單個資料集版本最大1,000,000個檔案,如有特殊需求可聯絡PAI 客戶經理擴容。
-
使用模型:
-
打標模型:支援使用百鍊平台-Qwen VL Max/Plus模型。
-
索引模型:支援使用百鍊多模態Embedding 模型(如tongyi-embedding-vision-plus),以及PAI Model Gallery的GME模型作為索引模型,部署至PAI-EAS使用。
-
-
元資訊儲存:
-
中繼資料:中繼資料安全儲存於PAI內建的中繼資料庫。
-
Embedding向量:支援儲存於下列自訂向量資料庫中:
-
Elasticsearch(向量增強版,8.17.0版本及以上)
-
OpenSearch(向量檢索版)
-
Milvus(2.4及以上版本)
-
Hologres(4.0.9以上版本)
-
Lindorm(向量引擎版本)
-
-
-
資料集處理模式:目前支援全量模式和增量模式運行智能打標任務及語義索引任務。
3. 使用流程
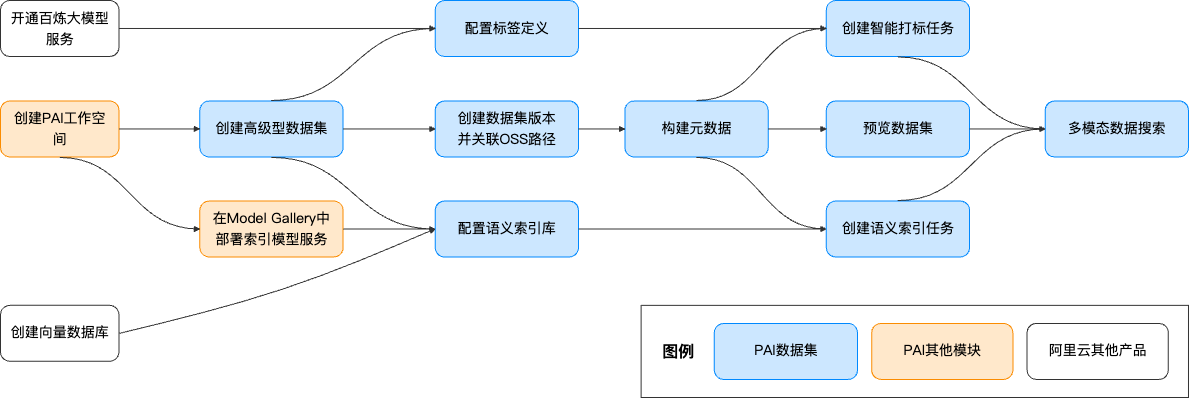
3.1 前置準備
3.1.1 開通PAI,建立預設工作空間並擷取空間管理員權限
3.1.2 開通百鍊並建立API Key
開通阿里雲百鍊並建立 API Key,詳情參見擷取API Key。
3.1.3 建立向量資料庫
建立向量資料庫執行個體
多模態資料集管理支援以下阿里雲向量資料庫:
-
Elasticsearch(向量增強版,8.17.0版本及以上)
-
OpenSearch(向量檢索版)
-
Milvus(2.4及以上版本)
-
Hologres(4.0.9以上版本)
-
Lindorm(向量引擎版本)
各向量資料庫執行個體的建立方法參見對應雲產品文檔。
網路設定以及白名單配置
-
公網方式
若向量庫執行個體開通了公網地址,將下方 IP 列表添加到執行個體的公網訪問白名單後,多模態資料管理服務即可通過公網訪問此執行個體。Elasticsearch 白名單設定參見配置執行個體公網或私網訪問白名單。
地區
IP列表
杭州
47.110.230.142、47.98.189.92
上海
47.117.86.159、106.14.192.90
深圳
47.106.88.217、39.108.12.110
烏蘭察布
8.130.24.177、8.130.82.15
北京
39.107.234.20、182.92.58.94
-
私網方式
請提交工單申請。
建立向量索引表(可選)
系統提供自動建立索引表功能,如果您無需自訂建立索引表,可跳過此步驟。
在某些向量資料庫中,向量索引表也稱為Collection或Index。
索引表結構定義(表結構必須遵循如下定義):
以 Elasticsearch 為例,通過 Python 建立語義索引表(其他類型向量資料庫索引表的建立參見對應雲產品文檔):
3.2 建立資料集
-
進入 PAI 工作空間,在左側功能表列單擊AI资产管理 > 数据集 > 新建数据集,進入資料集配置頁面。
-
配置資料集參數,關鍵參數如下,其他參數保持預設。
-
存储类型:Object Storage Service;
-
类型:高级型;
-
内容类型:图片;
-
OSS路径:選擇資料集的OSS 儲存路徑。如果您沒有準備資料集,可以下載樣本資料集retrieval_demo_data,並上傳至OSS,體驗多模態資料管理功能。
說明此處匯入檔案/檔案夾,僅在系統記錄中設定了路徑,不會複製資料。
其中匯入格式可選擇檔案或檔案夾,應用配置中預設掛載路徑為 /mnt/data/。
然後單擊确定,建立資料集。
-
3.3 建立串連
3.3.1 建立智能打標模型串連
-
進入 PAI 工作空間,在左側功能表列單擊AI资产管理 > 连接 > 模型服务 > 新建连接,開啟建立串連頁面。
-
選擇百炼大模型服务,並配置百鍊api_key。
-
建立成功後,在列表頁可以看到建立的百鍊大模型服務。
3.3.2 建立語義索引模型串連
-
如果您使用百鍊語義索引模型服務,可跳過此步驟。在左側功能表列單擊 Model Gallery,找到並部署 GME 多模態檢索模型,得到一個 EAS 服務。部署大約需要 5 分鐘,當處於运行中時,代表部署成功。
重要不再使用該索引模型時,請及時停止和刪除服務,避免持續產生費用。
可選擇 GME-2B 檢索模型(參數量 2B)或 GME-7B 檢索模型,單擊對應的部署按鈕即可開始部署。
-
進入 PAI 工作空間,在左側功能表列單擊AI资产管理 > 连接 > 模型服务 > 新建连接,開啟建立串連頁面。
-
根據您選擇百鍊語義索引模型還是自訂部署的 EAS 語義索引模型,配置模型串連資訊。
使用百鍊語義索引模型
-
连接类型:選擇通用多模态Embedding模型服务。
-
服务提供方:選擇第三方服務模型。
-
模型名稱:tongyi-embedding-vision-plus。
-
base_url:
https://dashscope.aliyuncs.com/api/v1/services/embeddings/multimodal-embedding/multimodal-embedding -
api_key:擷取API Key並填寫。
使用自訂部署的EAS語義索引模型
-
连接类型:選擇通用多模态Embedding模型服务。
-
服务提供方:選擇PAI-EAS模型服务。
-
EAS服务:選擇剛部署的 GME 多模態檢索模型。服務提供者不在當前帳號下時,可選擇第三方模型服務。
在彈出的選擇 EAS 服務對話方塊中,選擇狀態為 Running 的目標模型服務。
-
-
建立成功後,在列表頁可以看到建立的模型串連服務。
3.3.3 建立向量資料庫連接
-
在左側功能表列單擊AI资产管理 > 连接 > 数据库 > 新建连接,開啟建立串連頁面。
-
多模態檢索服務支援 Milvus/Lindorm/OpenSearch/Elasticsearch/Hologres 向量資料庫,以 Elasticsearch 為例建立串連。選擇检索分析服务-Elasticsearch,配置uri、username、password等資訊,詳情參見建立資料庫連接。
各向量資料庫連結格式參考:
Milvus
uri: http://xxx.milvus.aliyuncs.com:19530 database: {your_data_base} token: root:{password}OpenSearch
uri: http://xxxx.ha.aliyuncs.com username: {username} password: {password}Hologres
host: xxxx.hologres.aliyuncs.com database: {your_data_base} port: {port} access_key_id={password}Elasticsearch
uri: http://xxxx.elasticsearch.aliyuncs.com:9200 username: {username} password: {password}Lindorm
uri: xxxx.lindorm.aliyuncs.com:{port} username: {username} password: root:{password} -
建立成功後,在列表頁可以看到建立的向量資料庫連接。
3.4 建立智能打標任務
3.4.1 建立智能標籤定義
在左側功能表列單擊AI资产管理 > 数据集 > 智能标签定义 > 新建智能标签定义,開啟標籤配置頁面,配置樣本如下:
-
引导提示词:作為一個擁有多年駕駛經驗的老司機,你有著非常豐富的高速以及城市道路駕駛經驗。
-
标签定义:
3.4.2 建立智能打標離線任務
-
單擊自定义数据集,單擊資料集名稱進入詳情頁面,然後再單擊数据集任务。
-
進入任務頁面,單擊新建任务 > 智能打标,並配置任務參數。
-
数据集版本:選擇需要打標的版本,如 v1。
-
智能打标模型连接:選擇建立的百鍊模型串連。
-
智能打标模型:支援千問 VL-MAX 和千問 VL-Plus。
-
最大并发数:最大並發數根據 EAS 模型服務規格配置,單卡建議最大並發為 5。
-
智能标签定义:選擇剛建立的智能標籤定義。
-
打标模式:支援增量打標和全量打標。
-
-
智能打標任務建立成功後,在工作清單可查看打標任務狀態。單擊列表右側連結可查看日誌或停止任務。
說明初次開機智能打標任務,將進行中繼資料的構建,所需時間可能較長,請耐心等待。
3.5 建立語義索引任務
-
單擊資料集名稱進入詳情頁面,在索引库配置地區,單擊編輯按鈕。
-
配置索引庫。
-
索引模型连接:選擇3.3.2中建立的索引模型串連;
-
索引数据库连接:選擇3.3.3中建立的索引庫串連;
-
索引表:輸入建立向量索引表(可選)中建立的索引表名稱,即:dataset_embed_test;
單擊保存 > 立即刷新。然後會建立一個所選資料集版本的語義索引任務,對版本中全量檔案更新語義索引。可單擊資料集詳情頁面右上方语义索引任务查看任務詳情。
說明初次開機語義索引任務,將進行中繼資料的構建,所需時間可能較長,請耐心等待。
如果沒有單擊立即重新整理,而是取消,您可以手動建立任務。詳細操作如下:
在資料集詳情頁面單擊数据集任务進入任務頁面。
單擊新建任务 > 语义索引,配置資料集版本,最大並發數根據 EAS 模型服務規格配置,單卡建議最大並發為 5。然後單擊確認建立語義索引任務。
-
3.6 資料預覽
-
待智能打標和語義索引任務完成後,在資料集詳情頁面,單擊查看数据可預覽該資料集版本內的圖片。
-
在查看資料頁面,可對該資料集版本內的圖片進行預覽,可切換“畫廊視圖”和“列表視圖”查看。
-
點擊具體圖片,可查看大圖,並查看圖片中包含的標籤。
詳情頁展示圖片的中繼資料(檔案名稱、檔案類型、儲存路徑、檔案大小、修改時間)以及智能標籤(包括演算法標籤和使用者標籤)。
-
點擊縮圖左上方的Checkbox,可進行多選。或按住Shift鍵點擊Checkbox可一次性選擇多行資料。
選中後頁面底部顯示已選數量,可進行手動打標或取消選擇操作。
3.7 基礎資料搜尋(組合檢索)
-
在“查看資料”介面的左側工具列內,可進行索引检索和标签搜索,按下Enter或單擊搜索即可開始搜尋。
-
索引检索,文本關鍵詞搜尋:基於“語義索引”的結果,通過關鍵詞與圖片索引結果的向量匹配進行搜尋。在“進階設定”中可以設定topk、Score 閾值等參數。
-
索引检索,以圖搜圖:基於“語義索引”的結果,使用者可以從本地上傳圖片或者選擇OSS中的圖片,與資料集圖片索引結果的向量匹配進行搜尋。在“進階設定”中可以設定topk、Score閾值等參數。
-
标签搜索:基於“智能打標”的結果,通過關鍵詞與圖片標籤的匹配進行搜尋。可同時按照包含以下任意标签(OR)、同时包含以下标签(AND)和排除以下任意标签(NOT)的邏輯進行搜尋。
-
元数据搜尋:可以按照檔案名稱、儲存路徑、檔案最後修改時間進行搜尋。
以上所有搜尋條件為AND關係。
3.8 進階資料搜尋(DSL)
高级检索可以使用DSL检索。DSL是一種用於表達複雜檢索條件的領特定領域語言。它支援分組、布爾邏輯(AND/OR/NOT)、範圍比較(>, >=, <, <=)、屬性存在性(HAS/NOT HAS)、分詞匹配(:)與精確匹配(=)等,適用於進階檢索情境。文法說明詳見:擷取資料集檔案中繼資料列表。
例如,輸入以下 DSL 可篩選圖片類型的檔案:(FileType = "image" OR ContentType = "application/json") AND ThumbnailMode = "h_200" AND MaxResults = 50。
3.9 搜尋結果集的匯出
將搜尋結果匯出為檔案清單索引,用於後續模型訓練或資料分析。
檢索完成後,可以單擊頁面下方导出搜索结果按鈕,支援兩種匯出模式:
3.9.1 匯出為檔案
-
單擊导出为文件,在配置頁設定匯出內容及目標OSS目錄,單擊确定。
在匯出配置頁中,匯出內容可選擇文字、圖片、音頻、視頻和人工標籤,匯出類型選擇匯出檔案,並設定匯出路徑為目標 OSS 目錄。
-
查看匯出進度可通過在左側功能表列單擊AI资产管理 > 任务 > 数据集任务查看。
-
使用匯出結果。將匯出結果檔案與原資料集掛載至訓練環境(如 DLC 或 DSW 執行個體),通過代碼讀取匯出結果檔案索引,從原資料集中載入目標檔案進行訓練或分析。
3.9.2 匯出至邏輯型資料集版本
將進階型資料集的檢索結果匯入到邏輯型資料集的版本中,後續可通過資料集 SDK 使用該版本資料。
-
單擊导出至逻辑型数据集版本,選擇目標邏輯型資料集,單擊确认。
在匯出對話方塊中,選擇目標資料集和基礎型資料集版本,設定匯入範圍(全部檔案或選中檔案),匯入模式可選擇合并覆蓋並勾選需要匯入的標籤類型(智能標籤、人工標籤)。
如無可選邏輯型資料集,可參考如下內容:
-
使用邏輯型資料集。匯入任務完成後,目標邏輯型資料集已包含本次匯出的中繼資料,可通過 SDK 載入和使用。在資料集詳情頁可查看 SDK 使用方法。
from pai_datasets.load import load_dataset dataset = load_dataset(dataset_id="xxx", dataset_version="v1", region="cn-hangzhou", cache_dir=CACHE_DIR, keep_in_memory=True)SDK的安裝命令為:
pip install https://pai-sdk.oss-cn-shanghai.aliyuncs.com/dataset/pai_dataset_sdk-1.0.0-py3-none-any.whl
4. 自訂語義索引模型(可選)
您可以微調自訂語義檢索模型,在 EAS 部署成功後,按照3.3.2中的步驟建立模型串連,用於多模態資料管理。
4.1 資料準備
本文提供了樣本資料retrieval_demo_data,您可以單擊下載。
4.1.1 資料格式要求
每個資料樣本以一行 JSON 格式儲存到 dataset.jsonl 檔案中,必須包含以下欄位:
-
image_id: 映像唯一識別碼(如圖片名稱或唯一ID)。
-
tags: 與該映像關聯的文字標籤列表,標籤為字串數組。
樣本格式:
{
"image_id": "c909f3df-ac4074ed",
"tags": ["銀色的轎車", "白色的SUV", "城市街道", "下雪", "夜晚"],
}4.1.2 檔案組織圖
將所有影像檔放入 images 檔案夾,並將 dataset.jsonl 檔案放在與影像檔夾同級的目錄中。
目錄樣本:
├── images
│ ├── image1.jpg
│ ├── image2.jpg
│ └── image3.jpg
└── dataset.jsonl 務必使用原始檔案名 dataset.jsonl,檔案夾名 images 不可更改。
4.2 模型訓練
-
在 Model Gallery 中找到檢索相關的模型,根據所需模型大小和計算資源,選擇合適的模型進行微調和部署。
微調 VRAM bs=4
微調(4*A800)train_samples/second
部署 VRAM
向量維度
GME-2B
14G
16.331
5G
1536
GME-7B
35G
13.868
16G
3584
-
以訓練 GME-2B 模型為例,單擊训练,填入資料地址(預設地址為樣本資料地址),填寫模型輸出路徑,即可開始訓練。
在訓練配置頁面中,訓練資料集預設為樣本資料路徑,可自訂模型名稱和版本描述,設定模型輸出路徑為 OSS 目錄。
4.3 模型部署
訓練完成的模型可在訓練任務中,單擊部署部署微調後的模型。
單擊 Model Gallery 模型選項卡的部署按鈕,即可部署原始 GME 模型。
部署完成後,在頁面中擷取對應的 EAS 访问地址 及 Token。單擊查看調用資訊即可查看公網地址調用和 VPC 地址調用的詳細資料。
4.4 模型服務調用
輸入參數
|
名稱 |
類型 |
是否必填 |
樣本值 |
描述 |
|
model |
String |
是 |
pai-multimodal-embedding-v1 |
模型類型,後續可以添加使用者自訂模型的支援 / 進行基模型的版本迭代 |
|
contents.input |
list(dict) or list(str) |
否 |
input = [{'text': text}] input=[xxx,xxx,xxx,...] input = [{'text': text},{'image', f"data:image/{image_format};base64,{image64}"}] |
待embedding的內容。 當前只支援 text, image |
輸出參數
|
名稱 |
類型 |
樣本值 |
描述 |
|
status_code |
Integer |
200 |
http狀態代碼。 200 請求成功 204 請求部分成功 400 請求失敗 |
|
message |
list(str) |
['Invalid input data: must be a list of strings or dict'] |
報錯資訊 |
|
output |
dict |
見下表 |
embedding結果 |
dashscope 返回結果是一個 {'output', {'embeddings': list(dict), 'usage': xxx, 'request_id':xxx}}(暫時不用 'usage', 'request_id')
embeddings 的元素包含以下key (失敗的index 會把錯誤原因加在message中)
|
名稱 |
類型 |
樣本值 |
描述 |
|
index |
資料id |
0 |
http狀態代碼。 200、400、500等 |
|
embedding |
List[Float] |
[0.0391846,0.0518188,.....,-0.0329895, 0.0251465] 1536 |
embedding後的向量 |
|
type |
String |
"Internal execute error." |
錯誤資訊 |
輸出樣本:
{
"status_code": 200,
"message": "",
"output": {
"embeddings": [
{
"index": 0,
"embedding": [
-0.020782470703125,
-0.01399993896484375,
-0.0229949951171875,
...
],
"type": "text"
}
]
}
}4.5 模型評測
在我們的樣本資料上的評測效果如下(所使用的評測檔案):
|
原始模型Precision |
微調1個epoch的模型Precision |
|
|
gme2b |
Precision@1 0.3542 Precision@5 0.5280 Precision@10 0.5923 Precision@50 0.5800 Precision@100 0.5792 |
Precision@1 0.4271 Precision@5 0.6480 Precision@10 0.7308 Precision@50 0.7331 Precision@100 0.7404 |
|
gme7b |
Precision@1 0.3958 Precision@5 0.5920 Precision@10 0.6667 Precision@50 0.6517 Precision@100 0.6415 |
Precision@1 0.4375 Precision@5 0.6680 Precision@10 0.7590 Precision@50 0.7683 Precision@100 0.7723 |
4.6 模型使用
微調後的 Embedding 模型部署到 EAS 後,可通過3.3.2中的步驟建立模型串連,用於後續的多模態資料管理中使用。