本文介紹在AI搜尋開放平台進行多模態資料預先處理流程。
應用情境
多模態資料預先處理情境提供非結構化文檔及圖片處理方案,全鏈路分別由文檔解析服務、圖片解析服務、文檔切分服務、文本向量化服務、文本稀疏向量化服務組成,您將體驗到完整的資料處理流程。以上服務均需使用AI搜尋開放平台的API服務,將按照實際調用產生費用。
前提條件
開通AI搜尋開放平台服務,詳情請參見開通服務。
擷取服務調用地址和身份鑒權資訊,詳情請參見擷取服務接入地址、擷取API-KEY。
AI搜尋開放平台支援通過公網和VPC地址調用服務,且可通過VPC實現跨地區調用服務。目前支援上海、杭州、深圳、北京、張家口、青島地區的使用者,通過VPC地址調用AI搜尋開放平台的服務。
多模態資料預先處理鏈路搭建
為方便使用者使用,AI搜尋開放平台提供四種類型的開發架構:
Java SDK。
Python SDK。
如果業務已經使用LangChain開發架構,在開發架構中選擇LangChain。
如果業務已經使用LlamaIndex開發架構,在開發架構中選擇LlamaIndex。
步驟一:完成服務選型和代碼下載
本文以Python SDK開發架構為例介紹如何搭建多模態資料預先處理鏈路。
登入AI搜尋開放平台控制台。
選擇上海地區,切換到AI搜尋開放平台,切換到目標空間。
說明目前僅支援在上海開通AI搜尋開放平台功能。
支援杭州、深圳、北京、張家口、青島地區的使用者,通過VPC地址跨地區調用AI搜尋開放平台的服務。
在左側導覽列選擇情境中心,選擇多模態資料預先處理情境-資料解析和向量化右側的進入。
根據服務資訊結合業務特點,從下拉式清單中選擇所需服務,服務詳情頁面可查看服務詳細資料。
說明通過API調用多模態資料預先處理鏈路中的演算法服務時,需要提供服務ID(service_id),如文檔內容解析服務的ID為ops-document-analyze-001。
從服務列表中切換服務後,產生代碼中的service_id會同步更新。當代碼下載到本地環境後,您仍可以更改service_id,調用對應服務。
環節
服務說明
文檔內容解析
文檔內容解析服務(ops-document-analyze-001):提供通用文檔解析服務,支援從非結構化文檔(文本、表格、圖片等)中提取標題、分段等邏輯層級結構,以結構化格式輸出。
圖片內容解析
圖片內容理解服務(ops-image-analyze-vlm-001):可基於多模態大模型對圖片內容進行解析理解以及文字識別,解析後的文本可用於圖片檢索問答情境。
圖片文本識別服務(ops-image-analyze-ocr-001):使用OCR能力進行圖片文字識別,解析後的文本可用於圖片檢索問答情境。
文檔切片
文檔切片服務(ops-document-split-001):提供通用文本切片服務,支援基於文檔段落、文本語義、指定規則,對HTML、Markdown、txt格式的結構化資料進行拆分,同時支援以富文本形式提取文檔中的代碼、圖片以及表格。
文本向量化
OpenSearch文本向量化服務-001(ops-text-embedding-001):提供多語言(40+)文本向量化服務,輸入文本最大長度300,輸出向量維度1536維。
OpenSearch通用文本向量化服務-002(ops-text-embedding-002):提供多語言(100+)文本向量化服務,輸入文本最大長度8192,輸出向量維度1024維。
OpenSearch文本向量化服務-中文-001(ops-text-embedding-zh-001):提供中文文本向量化服務,輸入文本最大長度1024,輸出向量維度768維。
OpenSearch文本向量化服務-英文-001(ops-text-embedding-en-001):提供英文文本向量化服務,輸入文本最大長度512,輸出向量維度768維。
文本稀疏向量化
提供將文本資料轉化為稀疏向量形式表達的服務,稀疏向量儲存空間更小,常用於表達關鍵詞和詞頻資訊,可與稠密向量搭配進行混合檢索,提升檢索效果。
OpenSearch文本稀疏向量化服務(ops-text-sparse-embedding-001):提供多語言(100+)文本向量化服務,輸入文本最大長度8192。
完成服務選型後,單擊配置完成,進入代碼查詢查看和下載代碼,按照應用調用資料預先處理鏈路時的運行流程:
作用 | 說明 |
負責文檔處理,包含文檔解析/圖片解析、文檔切片、文本向量化。 | 使用主函數document_pipeline_execute完成以下流程,可通過文檔URL或Base64編碼輸入待處理文檔。
|
選擇代碼查詢下的文檔解析與向量化,單擊複製代碼或者下載檔案,將代碼下載到本地。
步驟二:本地環境適配和測試資料預先處理開發鏈路
將代碼下載到本地檔案後,需要配置代碼中的關鍵參數。
類別 | 參數 | 說明 |
AI搜尋開放平台 | api_key | API調用密鑰,擷取方式請參見管理API Key。 |
aisearch_endpoint | API調用地址,擷取方式請參見擷取服務接入地址。 說明 注意需要去掉“http://”。 支援通過公網和VPC兩種方式調用API。 | |
workspace_name | AI搜尋開放平台中的空間名稱。 | |
service_id | 服務ID,為操作方便,可以通過service_id_config配置各項服務以及ID。
|

完成參數配置後即可在Python 3.8.1及以上版本環境中運行代碼,測試結果是否正確。
如在代碼中對AI搜尋開放平台介紹進行資料預先處理,運行結果如下:
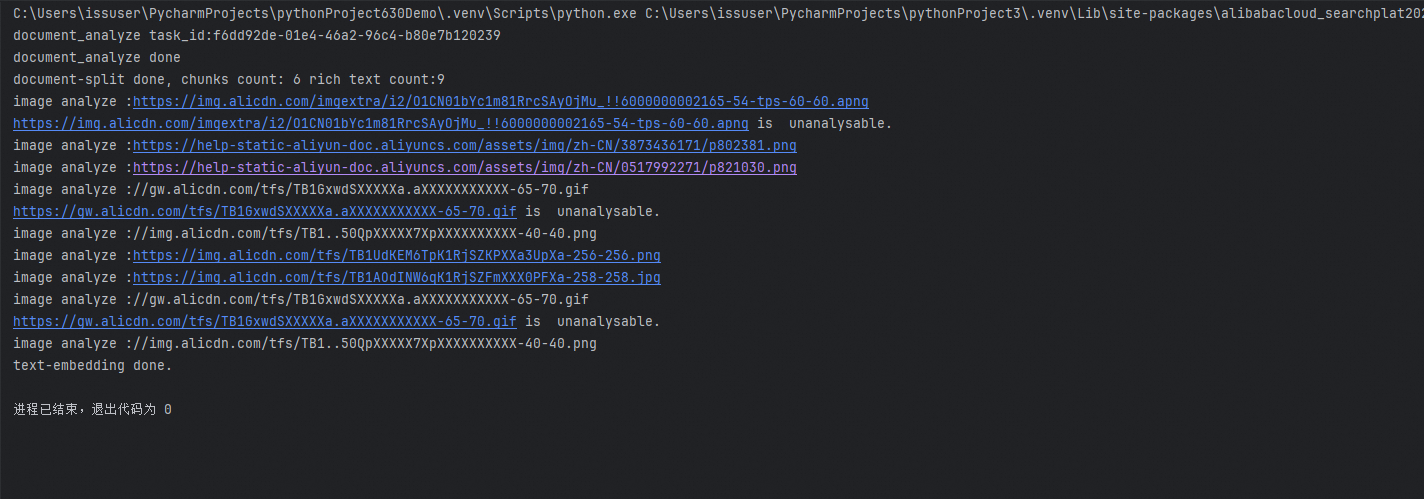
文檔解析與向量化檔案:
# 多模態資料處理鏈路
# 環境需求:
# Python版本:3.7及以上
# 包需求:
# pip install alibabacloud_searchplat20240529
# AI搜尋開放平台配置
aisearch_endpoint = "xxx.platform-cn-shanghai.opensearch.aliyuncs.com"
api_key = "OS-xxx"
workspace_name = "default"
service_id_config = {"document_analyze": "ops-document-analyze-001",
"split": "ops-document-split-001",
"text_embedding": "ops-text-embedding-001",
"text_sparse_embedding": "ops-text-sparse-embedding-001",
"image_analyze": "ops-image-analyze-ocr-001"}
# 輸入文檔url,範例文件為opensearch產品說明文檔
document_url = "https://www.alibabacloud.com/help/zh/open-search/search-platform/product-overview/introduction-to-search-platform?spm=a2c4g.11186623.0.0.7ab93526WDzQ8z"
import asyncio
from operator import attrgetter
from typing import List
from Tea.exceptions import TeaException, RetryError
from alibabacloud_tea_openapi.models import Config
from alibabacloud_searchplat20240529.client import Client
from alibabacloud_searchplat20240529.models import GetDocumentSplitRequest, CreateDocumentAnalyzeTaskRequest, \
CreateDocumentAnalyzeTaskRequestDocument, GetDocumentAnalyzeTaskStatusRequest, \
GetDocumentSplitRequestDocument, GetTextEmbeddingRequest, GetTextEmbeddingResponseBodyResultEmbeddings, \
GetTextSparseEmbeddingRequest, GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings, \
GetImageAnalyzeTaskStatusResponse, CreateImageAnalyzeTaskRequest, GetImageAnalyzeTaskStatusRequest, \
CreateImageAnalyzeTaskRequestDocument, CreateImageAnalyzeTaskResponse
async def poll_doc_analyze_task_result(ops_client, task_id, service_id, interval=5):
while True:
request = GetDocumentAnalyzeTaskStatusRequest(task_id=task_id)
response = await ops_client.get_document_analyze_task_status_async(workspace_name, service_id, request)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(interval)
elif status == "SUCCESS":
return response
else:
print("error: " + response.body.result.error)
raise Exception("document analyze task failed")
def is_analyzable_url(url:str):
if not url:
return False
image_extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.tiff'}
return url.lower().endswith(tuple(image_extensions))
async def image_analyze(ops_client, url):
try:
print("image analyze :" + url)
if url.startswith("//"):
url = "https:" + url
if not is_analyzable_url(url):
print(url + " is unanalysable.")
return url
image_analyze_service_id = service_id_config["image_analyze"]
document = CreateImageAnalyzeTaskRequestDocument(
url=url,
)
request = CreateImageAnalyzeTaskRequest(document=document)
response: CreateImageAnalyzeTaskResponse = ops_client.create_image_analyze_task(workspace_name, image_analyze_service_id, request)
task_id = response.body.result.task_id
while True:
request = GetImageAnalyzeTaskStatusRequest(task_id=task_id)
response: GetImageAnalyzeTaskStatusResponse = ops_client.get_image_analyze_task_status(workspace_name, image_analyze_service_id, request)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(5)
elif status == "SUCCESS":
return url + response.body.result.data.content
else:
print("image analyze error: " + response.body.result.error)
return url
except Exception as e:
print(f"image analyze Exception : {e}")
def chunk_list(lst, chunk_size):
for i in range(0, len(lst), chunk_size):
yield lst[i:i + chunk_size]
async def document_pipeline_execute(document_url: str = None, document_base64: str = None, file_name: str = None):
# 產生opensearch開發平台client
config = Config(bearer_token=api_key,endpoint=aisearch_endpoint,protocol="http")
ops_client = Client(config=config)
# Step 1: 文檔解析/圖片解析
document_analyze_request = CreateDocumentAnalyzeTaskRequest(document=CreateDocumentAnalyzeTaskRequestDocument(url=document_url, content=document_base64,file_name=file_name, file_type='html'))
document_analyze_response = await ops_client.create_document_analyze_task_async(workspace_name=workspace_name,service_id=service_id_config["document_analyze"],request=document_analyze_request)
print("document_analyze task_id:" + document_analyze_response.body.result.task_id)
extraction_result = await poll_doc_analyze_task_result(ops_client, document_analyze_response.body.result.task_id, service_id_config["document_analyze"])
print("document_analyze done")
document_content = extraction_result.body.result.data.content
content_type = extraction_result.body.result.data.content_type
# Step 2: 文檔切片
document_split_request = GetDocumentSplitRequest(
GetDocumentSplitRequestDocument(content=document_content, content_type=content_type))
document_split_result = await ops_client.get_document_split_async(workspace_name, service_id_config["split"],
document_split_request)
print("document-split done, chunks count: " + str(len(document_split_result.body.result.chunks))
+ " rich text count:" + str(len(document_split_result.body.result.rich_texts)))
# Step 3: 文本向量化
# 提取切片結果。圖片切片會通過圖片解析服務提取出常值內容
doc_list = ([{"id": chunk.meta.get("id"), "content": chunk.content} for chunk in document_split_result.body.result.chunks]
+ [{"id": chunk.meta.get("id"), "content": chunk.content} for chunk in document_split_result.body.result.rich_texts if chunk.meta.get("type") != "image"]
+ [{"id": chunk.meta.get("id"), "content": await image_analyze(ops_client,chunk.content)} for chunk in document_split_result.body.result.rich_texts if chunk.meta.get("type") == "image"]
)
chunk_size = 32 # 一次最多允許計算32個embedding
all_text_embeddings: List[GetTextEmbeddingResponseBodyResultEmbeddings] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_embedding_async(workspace_name,service_id_config["text_embedding"],GetTextEmbeddingRequest(chunk))
all_text_embeddings.extend(response.body.result.embeddings)
all_text_sparse_embeddings: List[GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_sparse_embedding_async(workspace_name,service_id_config["text_sparse_embedding"],GetTextSparseEmbeddingRequest(chunk,input_type="document",return_token=True))
all_text_sparse_embeddings.extend(response.body.result.sparse_embeddings)
for i in range(len(doc_list)):
doc_list[i]["embedding"] = all_text_embeddings[i].embedding
doc_list[i]["sparse_embedding"] = all_text_sparse_embeddings[i].embedding
print("text-embedding done.")
if __name__ == "__main__":
# 運行非同步任務
# import nest_asyncio # 如果在Jupyter notebook中運行,反注釋這兩行
# nest_asyncio.apply() # 如果在Jupyter notebook中運行,反注釋這兩行
asyncio.run(document_pipeline_execute(document_url))
# asyncio.run(document_pipeline_execute(document_base64="eHh4eHh4eHg...", file_name="attention.pdf")) #另外一種調用方式