針對知識庫線上問答情境,AI搜尋開放平台提供完整的RAG開發鏈路搭建方法,整體鏈路包含資料預先處理、檢索服務以及問答總結產生三大模組。AI搜尋開放平台將各模組可用的演算法服務元件化,可靈活選擇各模組使用的服務,如文檔解析、排序、問答總結服務等,快速產生開發代碼。AI搜尋開放平台以API形式透出服務,開發人員只需將代碼下載到本地,根據本文操作步驟替換API_KEY、API調用地址、本地知識庫等資訊,即可快速搭建基於RAG開發鏈路的知識庫問答應用。
技術原理
檢索增強產生RAG(Retrieval-Augmented Generation)結合了檢索技術和產生技術的人工智慧方法,旨在提升模型產生內容的相關性、準確性和多樣性。處理產生任務時,RAG首先在大量外部資料或知識庫中檢索與輸入最相關的片段,然後將檢索到的資訊與原始輸入一起輸入到大語言模型(LLM)中,作為提示或者上下文引導模型產生更精確和豐富的回答。這種方法允許模型在產生響應時不僅依賴於其內部的參數和訓練資料,還可以使用外部最新或特定領域的資訊提升回答準確性。

應用情境
知識庫線上問答常用於企業內部知識庫檢索與總結、垂直領域的線上問答等業務情境,基於客戶的專業知識庫文檔,通過RAG(檢索增強產生)技術和LLM(大語言模型) ,理解和響應複雜的自然語言查詢,協助企業客戶通過自然語言快速從PDF、WORD、表格、圖片文檔中檢索到所需資訊。
前提條件
-
開通AI搜尋開放平台服務,詳情請參見開通服務。
-
擷取服務調用地址和身份鑒權資訊,詳情請參見擷取服務接入地址、擷取API-KEY。
AI搜尋開放平台支援通過公網和VPC地址調用服務,且可通過VPC實現跨地區調用服務。目前支援上海、杭州、深圳、北京、張家口、青島地區的使用者,通過VPC地址調用AI搜尋開放平台的服務。

-
建立Elasticsearch(ES)執行個體,要求ES 8.5及以上版本,詳情請參見建立Elasticsearch執行個體。通過公網或私網訪問阿里雲ES執行個體時,需要將待訪問裝置的IP地址加入執行個體的訪問白名單中,詳情請參見配置執行個體公網或私網訪問白名單。
-
Python版本3.7及以上,在開發環境中引入Python包依賴aiohttp 3.8.6、elasticsearch 8.14。
RAG開發鏈路搭建
為方便使用者使用,AI搜尋開放平台提供四種類型的開發架構:
-
Java SDK。
-
Python SDK。
-
如果業務已經使用LangChain開發架構,在開發架構中選擇LangChain。
-
如果業務已經使用LlamaIndex開發架構,在開發架構中選擇LlamaIndex。
步驟一:完成服務選型和代碼下載
根據知識庫和業務需要,選擇RAG鏈路中需要使用的演算法服務以及開發架構,本文以Python SDK開發架構為例介紹如何搭建RAG鏈路。
-
登入AI搜尋開放平台控制台。
-
選擇上海地區,切換到AI搜尋開放平台,切換到目標空間。
說明目前僅支援在上海、德國(法蘭克福)開通AI搜尋開放平台功能。
支援杭州、深圳、北京、張家口、青島地區的使用者,通過VPC地址跨地區調用AI搜尋開放平台的服務。
-
在左側導覽列選擇情境中心,選擇RAG情境-知識庫線上問答右側的進入。
-
根據服務資訊結合業務特點,從下拉式清單中選擇所需服務,服務詳情頁面可查看服務詳細資料。
說明-
通過API調用RAG鏈路中的演算法服務時,需要提供服務ID(service_id),如文檔內容解析服務的ID為ops-document-analyze-001。
-
從服務列表中切換服務後,產生代碼中的service_id會同步更新。當代碼下載到本地環境後,您仍可以更改service_id,調用對應服務。
環節
服務說明
文檔內容解析
文檔內容解析服務(ops-document-analyze-001):提供通用文檔解析服務,支援從非結構化文檔(文本、表格、圖片等)中提取標題、分段等邏輯層級結構,以結構化格式輸出。
圖片內容解析
-
圖片內容理解服務(ops-image-analyze-vlm-001):可基於多模態大模型對圖片內容進行解析理解以及文字識別,解析後的文本可用於圖片檢索問答情境。
-
圖片文本識別服務(ops-image-analyze-ocr-001):使用OCR能力進行圖片文字識別,解析後的文本可用於圖片檢索問答情境。
文檔切片
文檔切片服務(ops-document-split-001):提供通用文本切片服務,支援基於文檔段落、文本語義、指定規則,對HTML、Markdown、txt格式的結構化資料進行拆分,同時支援以富文本形式提取文檔中的代碼、圖片以及表格。
文本向量化
-
OpenSearch文本向量化服務-001(ops-text-embedding-001):提供多語言(40+)文本向量化服務,輸入文本最大長度300,輸出向量維度1536維。
-
OpenSearch通用文本向量化服務-002(ops-text-embedding-002):提供多語言(100+)文本向量化服務,輸入文本最大長度8192,輸出向量維度1024維。
-
OpenSearch文本向量化服務-中文-001(ops-text-embedding-zh-001):提供中文文本向量化服務,輸入文本最大長度1024,輸出向量維度768維。
-
OpenSearch文本向量化服務-英文-001(ops-text-embedding-en-001):提供英文文本向量化服務,輸入文本最大長度512,輸出向量維度768維。
文本稀疏向量化
提供將文本資料轉化為稀疏向量形式表達的服務,稀疏向量儲存空間更小,常用於表達關鍵詞和詞頻資訊,可與稠密向量搭配進行混合檢索,提升檢索效果。
OpenSearch文本稀疏向量化服務(ops-text-sparse-embedding-001):提供多語言(100+)文本向量化服務,輸入文本最大長度8192。
查詢分析
查詢分析服務001(ops-query-analyze-001)提供通用的Query分析服務,可基於大語言模型對使用者輸入的Query進行意圖理解,以及相似問題擴充。
搜尋引擎
-
Elasticsearch:基於開源Elasticsearch構建的全託管雲端服務,100%相容開源功能的同時,支援開箱即用、按需付費。
說明搜尋引擎服務選擇Elasticsearch時,由於相容性問題,文本稀疏向量化服務不可用,建議使用文本向量化相關服務。
-
OpenSearch-向量檢索版是阿里巴巴自主研發的大規模分布式向量檢索引擎,支援多種向量檢索演算法,高精度下效能表現優異,能完成大規模高性價比的索引構建和檢索,同時,索引支援水平拓展與合并,支援索引流式構建、即增即查、資料即時動態更新。
說明如您需要使用OpenSearch-向量檢索版引擎方案,可以在RAG鏈路中替換引擎配置及代碼。
排序服務
BGE重排模型(ops-bge-reranker-larger):通用文檔打分服務,支援根據query與文檔內容的相關性,按分數由高到低對文檔排序,並輸出打分結果。
大模型
-
-
完成服務選型後,單擊配置完成,進入代碼查詢查看和下載代碼。
按照應用調用RAG鏈路時的運行流程,將代碼分為離線文檔處理和線上使用者問答處理兩部分:
流程
作用
說明
離線文檔處理
負責文檔處理,包含文檔解析、圖片提取、切片、向量化以及將文檔處理結果寫入ES索引。
使用主函數document_pipeline_execute完成以下流程,可通過文檔URL或Base64編碼輸入待處理文檔。
-
文檔解析,服務調用請參見文檔解析API。
-
調用非同步文檔解析介面,從文檔URL地址中提取文檔內容,或者從Base64編碼檔案中進行解碼。
-
通過create_async_extraction_task函數構造解析任務,通過poll_task_result函數輪詢任務完成狀態。
-
-
圖片提取,服務調用請參見圖片內容提取API。
-
調用非同步圖片解析介面,從圖片URL地址中提取圖片內容,或者從Base64編碼檔案中進行解碼。
-
通過create_image_analyze_task函數建立圖片解析任務,通過get_image_analyze_task_status函數擷取圖片解析任務狀態。
-
-
文檔切片,服務調用請參見文檔切片API。
-
調用文檔切片介面,將解析後的文檔按指定策略切片。
-
通過document_split函數進行文檔切片,包含文檔切片和富常值內容解析兩部分。
-
-
文本向量化,服務調用請參見文本向量化API。
-
調用文本稠密向量表示介面,將切片後的文本向量化。
-
通過text_embeddingFunction Compute每個切片的embedding向量。
-
-
寫入ES,服務調用請參見使用Elasticsearch的向量近鄰檢索(kNN)功能。
-
建立ES索引配置,包含指定向量欄位embedding和文檔內容欄位content。
重要建立ES索引時,系統會刪除已有同名索引。為避免誤刪同名索引,請更改代碼中的索引名稱。
-
通過helpers.async_bulk函數將向量化結果批量寫入ES索引。
-
線上問答處理
負責處理使用者線上查詢,包含產生查詢向量、查詢分析、檢索相關文檔切片、排序檢索結果以及根據檢索結果產生回答。
使用主函數query_pipeline_execute完成以下流程,對使用者查詢進行處理並輸出回答。
-
query向量化,服務調用請參見文本向量化API。
-
調用文本稠密向量表示介面,將使用者的查詢轉換為向量。
-
通過text_embedding函數產生查詢向量。
-
-
調用查詢分析服務,請參見查詢分析API。
調用查詢分析介面,通過分析歷史訊息識別使用者提問意圖及產生相似問題。
-
搜尋embedding切片,服務調用請參見使用Elasticsearch的向量近鄰檢索(kNN)功能。
-
使用ES檢索索引中與查詢向量相近的文檔切片。
-
通過AsyncElasticsearch的search介面,結合KNN查詢進行相似性檢索。
-
-
調用排序服務,請參見排序API。
-
調用排序服務介面,對檢索到的相關切片打分排序。
-
通過documents_ranking函數,根據使用者查詢對文檔內容打分排序。
-
-
調用大模型產生答案,服務調用請參見答案產生API。
調用大模型服務,使用檢索結果和使用者查詢通過llm_call函數產生最終答案。
分別選擇代碼查詢下的文檔處理流程和線上問答流程,單擊複製代碼或者下載檔案,將代碼下載到本地。
-
步驟二:本地環境適配和測試RAG開發鏈路
將代碼分別下載到本地的兩個檔案後,例如online.py和offline.py,需要配置代碼中的關鍵參數。
|
類別 |
參數 |
說明 |
|
AI搜尋開放平台 |
api_key |
API調用密鑰,擷取方式請參見管理API Key。 |
|
aisearch_endpoint |
API調用地址,擷取方式請參見擷取服務接入地址。 說明
注意需要去掉“http://”。 支援通過公網和VPC兩種方式調用API。 |
|
|
workspace_name |
AI搜尋開放平台 |
|
|
service_id |
服務ID,為操作方便,可以分別在離線文檔處理(offline.py)和線上問答處理代碼(online.py)中,通過service_id_config配置各項服務以及ID。
|
|
|
ES搜尋引擎 |
es_host |
Elasticsearch(ES)執行個體訪問地址,通過公網或私網訪問阿里雲ES執行個體時,需要先將待訪問裝置的IP地址加入執行個體的訪問白名單中,詳情參見配置執行個體公網或私網訪問白名單。 |
|
es_auth |
訪問Elasticsearch執行個體時的帳號和密碼,帳號為elastic,密碼為您建立執行個體時設定的密碼。如果忘記密碼可重設,具體操作請參見重設執行個體訪問密碼。 |
|
|
其他參數 |
如使用樣本資料則無需修改 |
|

完成參數配置後即可在Python 3.7及以上版本環境中,先後運行offline.py離線文檔處理檔案和online.py線上問答處理檔案測試回合結果是否正確。
如知識庫文檔為AI搜尋開放平台介紹,對文檔提問:AI搜尋開放平台可以做什嗎?
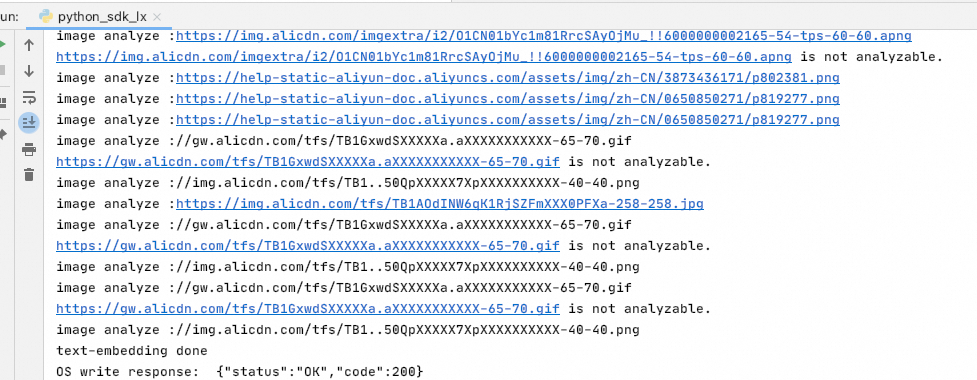
運行結果如下:
-
離線文檔處理結果
-
線上問答處理結果

-
查看源碼檔案
常見問題
代碼運行期間,由於資源未及時釋放可能出現Unclosed connector相關提示,無需處理。