百鍊 API 對單位時間內的請求數量、Token 用量及其增長速率設有限制,即限流。大模型服務具有長延遲和雙維度限流(同時限制請求數與 Token 量)的特性,傳統的"遇錯即重試"策略難以有效應對,需要針對性的流控措施。
本文按介入成本從低到高,介紹三類應對方案:
如果當前正在解決 429 報錯,可直接查看錯誤診斷與策略推薦定位原因。
錯誤診斷與策略推薦
同一錯誤碼可能由不同限流維度觸發。此外,高並發下服務端飽和也可能導致響應變慢或逾時,可通過下文的自適應擁塞控制策略緩解。
錯誤碼 (DashScope / OpenAI) | 觸發維度 | 特徵診斷 | 推薦策略 |
Throttling.RateQuota / limit_requests | 請求頻率超限
(RPM 超限)
| 間歇性報錯,成功率隨時間下降 | 令牌桶:控制單位時間內的請求配額 |
請求頻率超限
(RPS 超限)
| 啟動瞬間或並發激增時集中報錯 | 並發訊號量或平滑限速器:拉開請求間距 |
Throttling.AllocationQuota / insufficient_quota | Token 用量超限
(TPM 超限)
| 長文本處理時間歇性報錯 | 雙重令牌桶:同時限制 RPM 和 TPM 配額 |
Token 用量超限
(TPS 超限)
| 長文本並發時瞬間 Token 消耗過大 | 並發訊號量或平滑限速器 |
Throttling.BurstRate / limit_burst_rate | 流量增速超限
(Traffic Burst)
| 啟動或空閑恢複後突然發起大量請求 | 令牌桶設定低初始值(如 initial_tokens=0)實現冷啟動緩起;或使用平滑限速器削峰 |
用戶端流控策略
當平台配置方案無法滿足需求時,需要在用戶端引入流控機制。核心原則是將請求儘可能均勻分布在時間視窗內,避免突發流量觸發限流。系統剛啟動或長時間空閑後,應逐步提升並發量而非瞬間拉滿。
以下四種策略按工程複雜度從低到高排列。每種策略包含上一級的能力並在此基礎上增強:
建議在滿足業務需求的前提下,優先選擇實現成本更低的策略。
各策略的輸送量表現對比
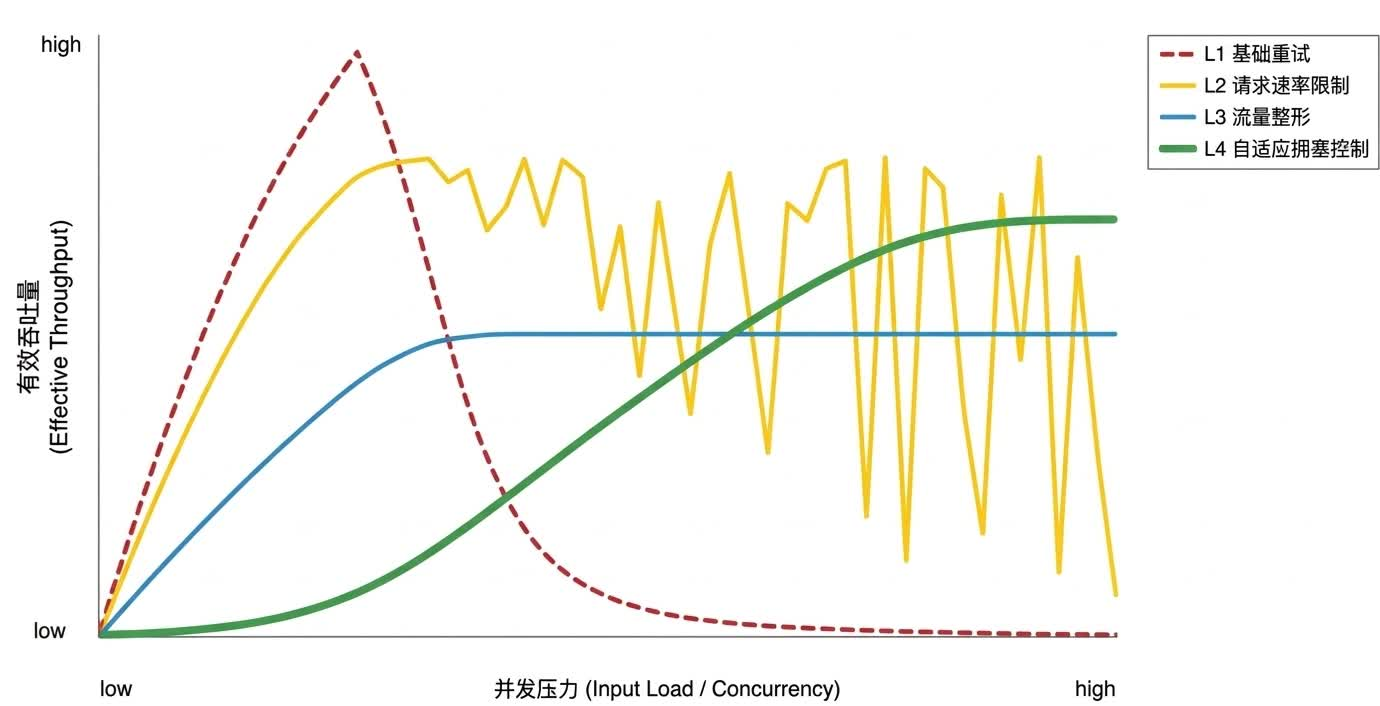
以上四種用戶端流控策略在不同負載下的有效輸送量表現差異如下:
基礎重試策略:低負載下有效,高並發下易觸發擁塞崩潰,輸送量斷崖式下降。
請求速率限制策略:防崩潰能力強,但長文本混合負載下因缺乏 Token 管控,輸送量呈鋸齒狀波動。
流量整形策略:穩定性高,以犧牲部分峰值吞吐換取平穩輸出。
自適應擁塞控制策略:高負載下可動態收斂至穩定高吞吐點,但存在冷啟動探測開銷。
基礎重試策略
適用於個人測試、本地指令碼和低頻背景工作等非高並發情境。預設不限制發送速率,僅在收到 429 或 5xx 錯誤時,觸發帶隨機抖動的指數退避重試。
該策略沒有前置流量控制,在多線程並發下極易觸發限流並導致大面積請求積壓報錯。
程式碼範例
使用 tenacity 庫
import openai
from openai import OpenAI
from tenacity import (
retry,
stop_after_attempt,
wait_random_exponential,
retry_if_exception_type
)
RETRYABLE_ERRORS = (
openai.RateLimitError,
openai.InternalServerError,
openai.APIConnectionError,
)
@retry(
wait=wait_random_exponential(min=1, max=60),
stop=stop_after_attempt(6),
retry=retry_if_exception_type(RETRYABLE_ERRORS)
)
def chat_with_retry(client, model, messages, max_tokens):
return client.chat.completions.create(
model=model,
max_tokens=max_tokens,
messages=messages
)
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="YOUR_DASHSCOPE_API_KEY"
)
try:
response = chat_with_retry(
client=client,
model="qwen-plus",
messages=[{"role": "user", "content": "什麼是指數退避重試?"}],
max_tokens=1024
)
print(response.choices[0].message.content)
except Exception as e:
print(f"請求失敗: {e}")
原生實現(無依賴)
import time
import random
import openai
from openai import OpenAI
RETRYABLE_ERRORS = (
openai.RateLimitError,
openai.InternalServerError,
openai.APIConnectionError,
)
def chat_with_retry(client, model, messages, max_tokens):
attempt = 0
max_retries = 5
base_delay = 1
max_delay = 60
while attempt <= max_retries:
try:
return client.chat.completions.create(
model=model,
max_tokens=max_tokens,
messages=messages
)
except RETRYABLE_ERRORS as e:
attempt += 1
if attempt > max_retries:
raise e
backoff = min(max_delay, base_delay * (2 ** (attempt - 1)))
sleep_time = backoff + random.uniform(0, 1)
print(f"觸發 {type(e).__name__},等待 {sleep_time:.2f}s 後重試...")
time.sleep(sleep_time)
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="YOUR_DASHSCOPE_API_KEY"
)
try:
response = chat_with_retry(
client=client,
model="qwen-plus",
messages=[{"role": "user", "content": "什麼是指數退避重試?"}],
max_tokens=1024
)
print(response.choices[0].message.content)
except Exception as e:
print(f"請求失敗: {e}")
上述代碼使用指數退避而非固定間隔重試。固定間隔重試(如統一 3 秒後重試)會讓所有失敗請求在同一時刻重新發起,極易再次觸發限流,形成持續擁堵。指數退避 + 隨機抖動則將重試"散開":
系統便能以分散的方式恢複,而非陷入"失敗—集體重試—再次失敗"的惡性迴圈。
請求速率限制策略
僅依賴被動重試難以應對真實業務流量,頻繁重試會顯著增加響應延遲。請求速率限制策略引入主動流控,在請求發出前進行自我檢查和調控,將無序湧入的大量請求梳理成符合平台 RPM 限額的平穩隊列。觸發平台限流後,通常需要一段時間才能恢複,主動平滑請求節奏雖會帶來少量可控的排隊延遲,但遠低於被動陷入”報錯—等待—重試”迴圈的時間成本,即用確定的小代價,避免不確定的大延遲。
適用於 Chatbot 等輕量互動、一問一答、對首字延遲敏感的線上服務。
該策略在用戶端實施主動排隊,分為兩級控制:
兩級控制必須嚴格按先擷取 RPM 令牌,再擷取並發訊號量的順序執行。並發槽位是稀缺資源,只應分配給已滿足執行條件的請求。若順序顛倒(先佔槽位,再等令牌),高負載下極易引發隊頭阻塞(Head-of-Line Blocking)——請求佔住槽位後無令牌可用,長期持槽卻無法執行,所有槽位被佔滿,卻無請求真正發送。核心原則:持有稀缺資源時,不做可能的長耗時等待。
下方代碼將令牌桶初始化為滿桶狀態(initial_tokens=rpm_limit),適合輕量線上服務在啟動初期立即處理請求。若滿桶啟動觸發速率限制錯誤,可降低初始令牌數(如設為 initial_tokens=0,即”空桶啟動”),使系統以更平緩的速率進入工作狀態。
該策略不追蹤 Token 用量,長文本任務中仍會因耗盡 TPM 配額觸發限流。
程式碼範例
核心組件:令牌桶
import time
class TokenBucket:
"""
令牌桶實現,用於控制每分鐘請求數 (RPM)。
支援預支 (Debt) 機制,以保證高並發下的先進先出 (FIFO) 順序。
"""
def __init__(self, quota_per_minute: float, initial_tokens: float = 0.0):
self.capacity = quota_per_minute
self.tokens = initial_tokens
self.refill_rate = quota_per_minute / 60.0
self.last_refill = time.monotonic()
def reserve(self, cost: float = 1.0) -> float:
"""
申請令牌。
如果令牌不足,返回需要等待的秒數(支援預支)。
"""
self._refill()
# 1. 令牌充足:直接扣除
if self.tokens >= cost:
self.tokens -= cost
return 0.0
# 2. 令牌不足:計算等待時間並預支
# 為當前請求"預定"了未來的令牌,確保 FIFO 順序
deficit = cost - self.tokens
wait_seconds = deficit / self.refill_rate
self.tokens -= cost
return wait_seconds
def _refill(self):
"""根據流逝時間補充令牌"""
now = time.monotonic()
elapsed = now - self.last_refill
if elapsed > 0:
self.tokens = min(self.capacity, self.tokens + elapsed * self.refill_rate)
self.last_refill = now
用戶端邏輯
import asyncio
import openai
from openai import AsyncOpenAI
from tenacity import retry, wait_random_exponential, stop_after_attempt, retry_if_exception_type
class RateLimitedClient:
def __init__(
self,
api_key: str,
base_url: str = "https://dashscope.aliyuncs.com/compatible-mode/v1",
rpm_limit: float = 600.0,
max_concurrency: int = 20
):
self.client = AsyncOpenAI(api_key=api_key, base_url=base_url)
# 組件 1: RPM 令牌桶 (控制總量)
self.rpm_bucket = TokenBucket(
quota_per_minute=rpm_limit,
initial_tokens=rpm_limit # 滿桶啟動,適合輕量線上服務
)
# 組件 2: 並發訊號量 (控制瞬間並發)
self.semaphore = asyncio.Semaphore(max_concurrency)
async def _execute_request(self, model, messages, max_tokens):
"""執行單個請求:依次通過 RPM 檢查和並發限制。"""
# 1. RPM 檢查 (先拿令牌)
wait_seconds = self.rpm_bucket.reserve(1.0)
if wait_seconds > 0:
await asyncio.sleep(wait_seconds)
# 2. 並發檢查 (再拿訊號量)
async with self.semaphore:
# 3. 發起 API 呼叫
return await self.client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens
)
@retry(
wait=wait_random_exponential(min=1, max=60),
stop=stop_after_attempt(5),
retry=retry_if_exception_type((
openai.RateLimitError,
openai.InternalServerError,
openai.APIConnectionError
))
)
async def chat_with_limit(self, model, messages, max_tokens=1024):
# 設計考量:為什麼重試也要重新拿 Token?
# 答:為了安全。如果不重新拿,重試帶來的流量脈衝
# 可能會瞬間突破 RPM 限制
return await self._execute_request(model, messages, max_tokens)
流量整形策略
在 RAG 即時入庫、長文檔批量分析等追求高穩吞吐的批量處理情境中,請求速率限制策略存在明顯的 TPM 盲區。為此,流量整形策略升級為雙重資源感知(RPM & TPM),並在發送端引入整形機制,將突發脈衝流量“削峰填穀”,轉為平滑流速。
該策略在原有請求速率限制基礎上,增強了以下能力:
雙重資源管控(RPM & TPM):同時維護 RPM 和 TPM 令牌桶,所有請求在發出前必須通過兩個維度配額檢查。
輸入事前預扣,輸出事後結算:模型輸出長度在請求前未知。TPM 令牌桶在發送時僅預扣輸入 Token,請求完成後結算實際輸出 Token。即使結算時額度不足(令牌為負),後續請求也會等待令牌回正,自然平滑流速。
勻速預熱:冷啟動期間,令牌發放速率隨時間軸性增長,消除初始突發風險。
平滑限速:通過強制請求間保持最小間隔(Pacing),平滑發送速率,降低觸發速率限制的風險。
備選方案參考:若業務對啟動瞬間的微小排隊延遲不敏感,可複用標準令牌桶邏輯(設 initial_tokens=0),實現安全啟動,同時降低用戶端複雜度。此外,本文的 Python 令牌桶實現僅用於示範設計思路,生產環境中建議使用各語言生態成熟的限流組件(如 Java 的 Guava SmoothRateLimiter)。
程式碼範例中將平滑等待置於並發鎖內部,以避免隊頭阻塞引發的請求集中發送。多個請求可能在等待結束後同時競爭並發訊號量,導致原本平滑的流量在出口處再次擁堵。雖會輕微降低並發效率,但能確保發送間隔精準可控。
完整的流量整形鏈路為:預估輸入 Token → 雙重准入(RPM & TPM)→ 並發鎖 → 平滑整形 → 發送 → 輸出 Token 結算。
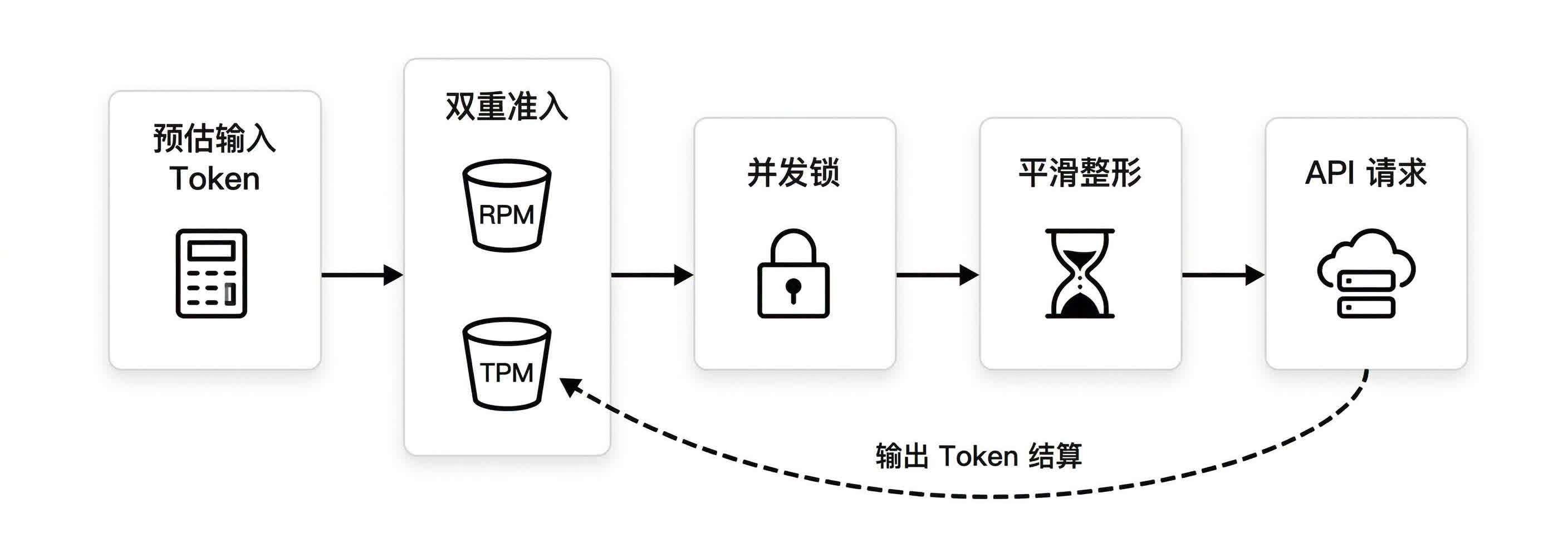
該策略因採用保守的平滑機制,會犧牲部分理論最大並發度,不適用於極致低延遲的線上服務。
程式碼範例
進階令牌桶
import time
class TokenBucket:
"""進階令牌桶,支援勻速預熱 (Continuous Warm-up) 機制。"""
def __init__(self, quota_per_minute: float, warmup_seconds: float = 0.0):
self.capacity = quota_per_minute
self.tokens = 0.0
self.target_refill_rate = quota_per_minute / 60.0
self.warmup_seconds = warmup_seconds
self.start_time = time.monotonic()
self.last_update_time = self.start_time
self.cumulative_generated = 0.0
def _get_cumulative_tokens(self, t: float) -> float:
if t <= 0:
return 0.0
R = self.target_refill_rate
T = self.warmup_seconds
if T <= 0:
return R * t
if t <= T:
return (R / (2 * T)) * (t ** 2)
else:
warmup_total = (R * T) / 2.0
return warmup_total + R * (t - T)
def _get_time_for_cumulative_tokens(self, target_cumulative: float) -> float:
if target_cumulative <= 0:
return 0.0
R = self.target_refill_rate
T = self.warmup_seconds
if T <= 0:
return target_cumulative / R
warmup_total = (R * T) / 2.0
if target_cumulative <= warmup_total:
return ((2 * T * target_cumulative) / R) ** 0.5
else:
return (target_cumulative - warmup_total) / R + T
def reserve(self, cost: float = 1.0) -> float:
now = time.monotonic()
relative_now = now - self.start_time
current_cumulative = self._get_cumulative_tokens(relative_now)
new_tokens = current_cumulative - self.cumulative_generated
self.tokens = min(self.capacity, self.tokens + new_tokens)
self.cumulative_generated = current_cumulative
self.last_update_time = now
if self.tokens >= cost:
self.tokens -= cost
return 0.0
deficit = cost - self.tokens
self.tokens -= cost
target_cumulative = self.cumulative_generated + deficit
target_time = self._get_time_for_cumulative_tokens(target_cumulative)
wait_seconds = target_time - relative_now
return max(0.0, wait_seconds)
def adjust(self, amount: float):
self.tokens = min(self.capacity, self.tokens + amount)
平滑限流器
import time
class SmoothRateLimiter:
def __init__(self, rate_per_minute: float):
self._min_interval = 60.0 / rate_per_minute
self._last_operation = time.monotonic()
def reserve(self) -> float:
now = time.monotonic()
elapsed = now - self._last_operation
wait_time = max(0.0, self._min_interval - elapsed)
self._last_operation = now + wait_time
return wait_time
用戶端邏輯
import asyncio
class TrafficShapingClient:
def __init__(self):
self._rpm_bucket = TokenBucket(quota_per_minute=600)
self._tpm_bucket = TokenBucket(quota_per_minute=1_000_000)
self._smooth_limiter = SmoothRateLimiter(rate_per_minute=600)
self._concurrency_semaphore = asyncio.Semaphore(20)
async def _execute_throttled_request(self, model, prompt, max_tokens, input_tokens):
# [步驟 1] 雙重准入控制 (Parallel Admission)
# 同時檢查 RPM 和 TPM,取兩者中較長的等待時間
wait_rpm = self._rpm_bucket.reserve(1.0)
# TPM 檢查僅針對輸入 Token 申請額度
wait_tpm = self._tpm_bucket.reserve(input_tokens)
admission_wait = max(wait_rpm, wait_tpm)
if admission_wait > 0:
await asyncio.sleep(admission_wait)
# [步驟 2] 擷取並發鎖 (Concurrency Lock)
async with self._concurrency_semaphore:
# [步驟 3] 流量整形 (Traffic Shaping)
# 關鍵:在鎖內進行平滑等待
# 犧牲部分並發效率,換取發送間隔的精準可控
smooth_wait = self._smooth_limiter.reserve()
if smooth_wait > 0:
await asyncio.sleep(smooth_wait)
# [步驟 4] 發送請求
content, actual_usage = await self._send_chat_request(model, prompt, max_tokens)
# [步驟 5] 輸出 Token 結算
output_tokens = actual_usage.completion_tokens
if output_tokens > 0:
self._tpm_bucket.adjust(-output_tokens)
return content
自適應擁塞控制策略
適用於 API Gateway、複雜代理、多租戶等大規模動態混合負載情境。
說明 選型提示:該策略並非通用方案
自適應擁塞控制策略的核心價值在於應對高度不確定與劇烈波動的業務環境,並非普適選擇:
效能悖論:若業務負載可預測、較穩定(如定量批處理),基於經驗直接設定最優靜態參數,效能通常優於需要"試探與收斂"的動態探測。
探測損耗:動態演算法為了尋找邊界,必然伴隨冷啟動爬坡與試探性波動。在可知情境下,這種"探索成本"反而是不必要的效能損耗。
維護成本:引入閉環反饋機制,顯著增加了系統的複雜度與排查難度。
除非業務規模極大、負載複雜且波動顯著,否則優先選擇更簡單的前三種策略。
請求速率限制策略和流量整形策略是基於靜態配額的經典防禦策略,在負載穩定、可預測的情境下完全適用。然而,在網關級的複雜情境下,業務面臨來自兩方面的動態變化:下遊負載複雜多變(高並發短請求與長耗時深度推理任務交織);平台限流閾值動態波動(秒級速率限制和增速判定閾值會根據服務狀態調整)。靜態策略難以兼顧效率與穩定性。
該策略借鑒 BBR(Bottleneck Bandwidth and RTT) ,建立了基於 EBP(Elastic Bandwidth Probing) 的閉環控制系統。它將 RPM/TPM 配額視為指導上限,根據即時反饋(延遲變化、是否限流)動態計算最佳發送速率,最大化輸送量。
彈性探測(EBP):記憶歷史最高成功水位,根據當前並發度與最高水位的距離類比彈簧張力計算探測增益(距離越遠加速,越近減速)。疊加微小線性推力確保在高飽和區間仍能持續探索邊界。
TPT 擁塞感知:大模型產生耗時與長度成正比,長文本延遲高不代表擁塞。使用 TPT(Time Per Token,單 Token 處理耗時)作為指標,濾除內容長度的雜訊。只有當 TPT 顯著惡化時才判定為計算飽和。
防突發調速器:無論 EBP 計算出的目標並發度多高,調速器都會強制限制並發增長的加速度,確保流量呈平滑上升態勢,避免階梯跳變觸發增速限制。
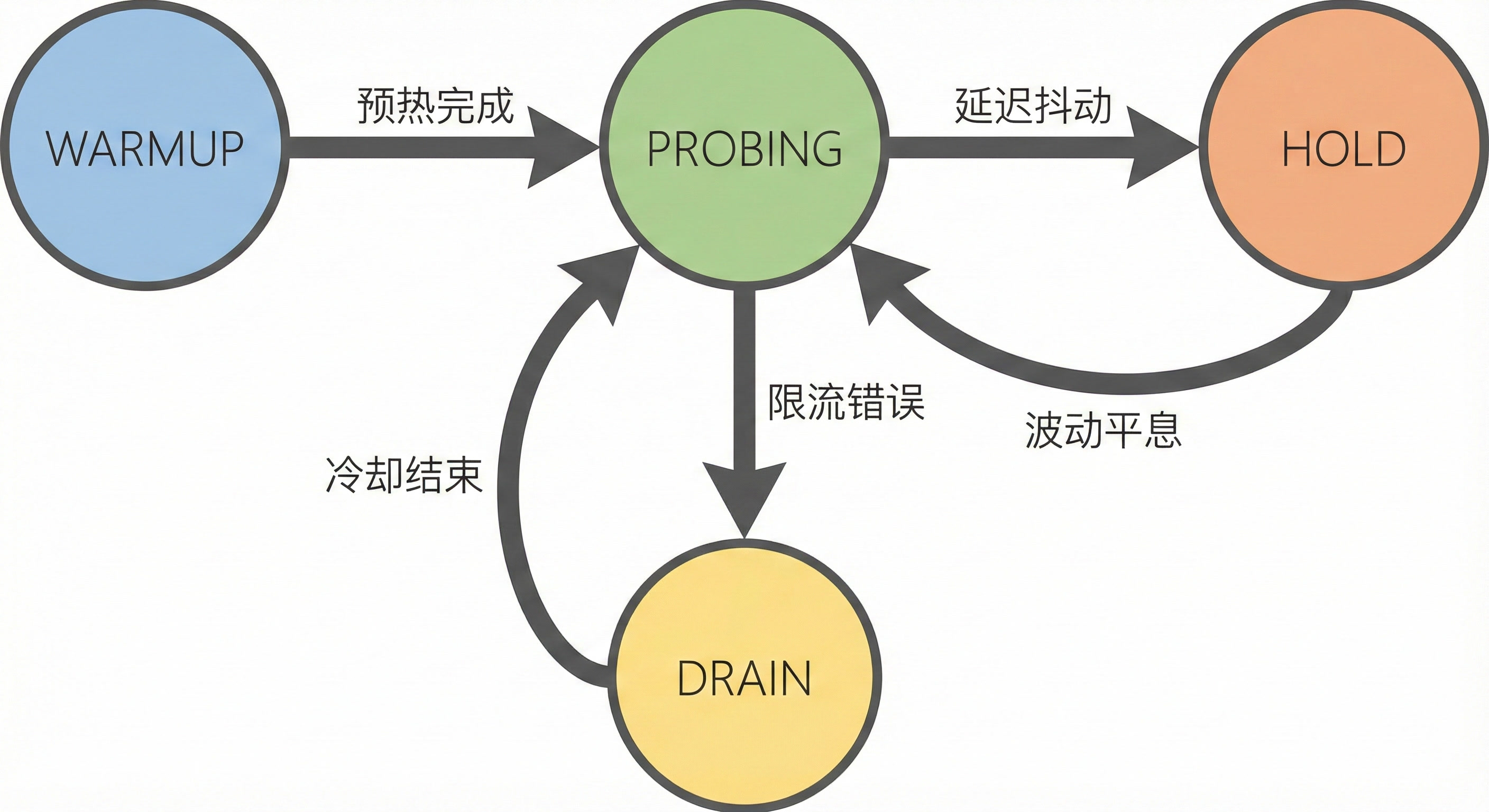
相較於原生 BBR,該策略針對大模型特性進行了以下關鍵改造:
指導性探測:引入已知的 RPM/TPM 配額作為"指導上限",避免盲目試探導致的頻繁撞牆。
訊號源改造(RTT → TPT):原生 BBR 依賴 RTT(往返時延),但大模型情境中內容長度帶來的延遲差異遠大於網路抖動,改用 TPT 剔除內容長度的幹擾。
響應機制強化(ProbeRTT → Hold):面對延遲波動,選擇保持當前並發水平,而非主動退避降低吞吐。
硬限流響應(Packet Loss → 429 Drain):一旦觸發 429 錯誤,進入激進的 Drain 狀態,冷卻期結束後執行快速恢複。
該策略存在以下局限:
擁塞訊號噪點(TPT Noise):當前 TPT 按"總延遲 / 總 Token 數"粗略估算。總延遲混入了網路往返、排隊與首字產生耗時,容易受網路抖動或長輸入幹擾而虛高,從而誤觸發 Hold 狀態。
大請求饑餓(Starvation Risk):為追求極致調度效能,該策略使用了非嚴格 FIFO 的喚醒機制。在配額緊缺時,短 Token 請求可能"插隊"搶佔資源,導致長 Token 請求排隊等待時間過長。
冷啟動問題(Cold Start):該策略需要預熱時間建立統計模型,低負載或短時任務中因從零探測,輸送量可能低於前三種策略。
程式碼範例
控制入口
class ElasticCongestionController:
async def acquire(self):
"""[准入階段] 請求發起前的檢查"""
# 1. SSR 慢啟動重啟:若空閑太久,主動衰減上限
# 防止過時水位導致的突發流量
if self.is_idle_too_long():
self.perform_slow_start_restart()
# 2. 熔斷檢查:若處於 DRAIN (冷卻) 狀態,強制等待
if self.state == CongestionState.DRAIN:
await self.wait_for_cooldown()
# 3. 雙重預算檢查:同時檢查並發槽位和 Token 預算
await self.wait_for_budget(request_tokens)
async def release(self, latency, actual_tokens, error):
"""[反饋階段] 請求結束後的決策"""
if error:
# [故障響應] 遇限流錯誤 (429/503):立即排水 + 乘性回退
self.state = CongestionState.DRAIN
self.concurrency_limit *= self.backoff_factor # e.g. 0.7
return
# [正常響應] 計算 TPT (Time-Per-Token)
current_tpt = latency / actual_tokens
# [擁塞感知] TPT 突增 (產生變慢):進入 HOLD 觀察
# 維持並發水平,不退避也不增長
if current_tpt > self.metrics.ema_tpt * 2.0:
self.state = CongestionState.HOLD
else:
# [穩態探測] 網路健康:執行 EBP 彈性探測
self.state = CongestionState.PROBING
self.update_limit_via_ebp()
EBP 探測
def probe_next_limit(self, current_limit, max_known_capacity):
"""
計算下一個並發上限
核心公式:Next = Max(彈簧張力, 線性推力) + 調速器平滑
"""
# 1. 計算物理上限 (Little's Law)
# 理論上限 = 輸送量 * 延遲 * 緩衝因子
dynamic_ceiling = self.metrics.tps * self.metrics.avg_latency * 1.2
# 2. 彈簧邏輯 (Spring Tension)
# 距離歷史最高水位越遠,張力越大(加速);越近則越小(減速)
tension = 1.0 - (current_limit / max_known_capacity)
spring_target = current_limit * (1.0 + tension * gain)
# 3. 線性推力 (Additive Thrust)
# 解決"芝諾悖論":張力趨近於 0 時,強制疊加微小線性增量
# 確保系統能突破局部極值,持續探索邊界
linear_target = current_limit + self.min_additive_step
raw_target = max(spring_target, linear_target)
# 4. 防突發調速器 (Rate Governor)
# 限制並發增長的加速度,防止階梯跳變
final_limit = self.governor.smooth(raw_target)
return min(final_limit, dynamic_ceiling)
統計追蹤
class CongestionMetrics:
def update_stats(self, latency, token_count):
"""
[感應器] 即時更新統計指標
使用 EMA (指數移動平均) 濾除長尾請求的雜訊
"""
alpha = 0.2 # 平滑因子
# 1. 估算單請求大小 (Token Size)
self.ema_tokens = (1 - alpha) * self.ema_tokens + alpha * token_count
# 2. 估算 TPT (Time Per Token)
# 用 TPT 代替 Latency,消除 LLM 產生長度不同帶來的誤差
instant_tpt = latency / token_count
self.ema_tpt = (1 - alpha) * self.ema_tpt + alpha * instant_tpt
def track_inflight(self, estimated_tokens):
"""
[盲區填充] 修正"響應後才計數"的滯後性
請求發起瞬間,立即預扣額度
"""
self.inflight_tokens += estimated_tokens
架構兜底方案
當平台配置和用戶端流控仍無法滿足業務對可用性或峰值吞吐的要求時,可在系統架構層面引入兜底機制。
模型降級(Fallback)
當主模型因限流或服務異常無法響應時,自動回退至配額寬裕的備選模型,保障主流程持續響應。
降級鏈路設計原則
選擇不同系列的模型:百鍊的限流按模型獨立計算。模型限流時可選擇不同模型作為備選,例如由 qwen3.6-plus 降級至 qwen3.6-flash。
僅在限流錯誤時觸發降級:降級應針對 429 限流錯誤,而非所有異常。網路逾時或參數錯誤等問題切換模型也無法解決。
備選模型需提前驗證:確保備選模型支援業務所需的功能(如 Function Calling、結構化輸出等),避免降級後功能異常。
程式碼範例
以下樣本示範了基於 429 錯誤碼的模型降級邏輯:主模型請求觸發限流時,自動切換至備選模型重試。
import os
import asyncio
from openai import AsyncOpenAI, APIStatusError
# 主模型與備選模型(不同系列,獨立配額)
PRIMARY_MODEL = "qwen3.6-plus"
FALLBACK_MODEL = "qwen3.6-flash"
client = AsyncOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
async def chat_with_fallback(messages: list) -> str:
"""帶降級的請求:主模型限流時自動切換備選模型。"""
for model in [PRIMARY_MODEL, FALLBACK_MODEL]:
try:
response = await client.chat.completions.create(
model=model,
messages=messages
)
return response.choices[0].message.content
except APIStatusError as e:
if e.status_code == 429 and model == PRIMARY_MODEL:
print(f"[限流觸發] {model},降級至 {FALLBACK_MODEL}")
continue
raise
raise RuntimeError("所有模型均不可用")
async def main():
result = await chat_with_fallback(
messages=[{"role": "user", "content": "你好"}]
)
print(result)
if __name__ == "__main__":
asyncio.run(main())
模型降級可與用戶端流控策略組合使用。例如,在請求速率限制策略的重試邏輯中整合降級判斷:當重試次數耗盡仍觸發限流時,切換至備選模型。
基於訊息佇列(MQ)的削峰填穀
對於不要求即時響應的後端業務,可引入訊息中介軟體(如 RabbitMQ、Kafka)進行削峰。突發流量先寫入 MQ,消費端按限流配額勻速拉取處理。該架構解耦了前端峰值與後端調用,可從根本上避免限流報錯。
適用情境:使用者提交任務後可接受非同步通知結果的業務,如工單處理、內容審核、批量資料標註等。MQ 作為緩衝層,吸收前端的流量尖峰,消費端以穩定速率向百鍊 API 發送請求。
架構設計要點:
消費速率控制:消費端應配合請求速率限制或流量整形策略,按 RPM/TPM 配額勻速消費,而非無限制地拉取訊息。
死信處理:對於多次重試仍失敗的訊息,應轉入無效信件佇列並觸發警示,避免訊息無限重試導致消費阻塞。
背壓傳遞:當 MQ 積壓超過閾值時,應向上遊反饋壓力(如返回排隊狀態),避免隊列無限增長。
生產環境注意事項
上述範例程式碼基於 Python asyncio 單線程迴圈,用於示範核心演算法。應用於大規模生產前,建議關注以下問題。
非文本模型的適配
上述策略以文本模型為例,但核心控制思想同樣適用於多模態模型服務(如映像產生、語音合成)。除計量單位不同外,本質均為對提交速率和處理容量的限制:
無論限流指標如何變化,用戶端主動流控的原則不變。只需將計數器(如 RPM 令牌桶)或探測指標(如 TPT)替換為對應模態的指標。具體限流規則與指標定義參見模型限流條件中對應模型的說明。
並行存取模型的原子性
樣本實現:由於 asyncio 採用單線程協作式調度,範例程式碼中的狀態修改操作具備天然的原子性,在單進程內無需額外的並發保護。
生產建議:在多線程或多進程環境中實現時,需注意令牌桶及統計視窗的並發安全,確保狀態更新的正確性,否則會因競態條件(Race Condition)導致流控失效。
分布式限流
樣本實現:範例程式碼中的流控組件均為本地記憶體(In-Memory)實現。
生產建議:多執行個體分布式部署中,各執行個體獨立進行本地流控,實際總用量可能超標並觸發全域限流。建議使用中心化計數器(如 Redis)統一管控全節點用量。
優先順序隊列與饑餓預防
樣本實現:所有範例程式碼皆未實現優先順序區分。尤其自適應擁塞控制策略為追求調度效能而採用了非嚴格 FIFO 的喚醒機制。
生產建議:當業務存在高低優先順序請求時,建議實現加權優先順序隊列(Weighted Priority Queue),保障高優請求的頻寬。同時需引入防饑餓機制,為低優先順序隊列保留最小配額,防止其因持續高負載而完全無法調度。