添加視覺理解能力
百鍊 Coding Plan 中的部分模型(qwen3.6-plus、qwen3.5-plus、kimi-k2.5)原生支援視覺理解,可直接處理圖片輸入。對於 glm-5、MiniMax-M2.5 等純文字模型,可通過添加本地 Skill 使其獲得視覺能力。
運行圖片理解 Skill 會消耗 Coding Plan 額度,無其他收費項。
前提條件
-
已訂閱 Coding Plan,詳情請參見快速開始。
-
已在 Coding Plan 工具中完成接入配置,且能正常對話,詳情請參見接入用戶端/開發工具。
視覺支援情況
|
模型 |
是否支援視覺 |
說明 |
|
是 |
無需額外配置,可直接傳入圖片 |
|
否 |
需通過 Skill 或 Agent 輔助模型獲得視覺能力 |
方法 1:直接使用視覺模型(推薦)
qwen3.6-plus、qwen3.5-plus 和 kimi-k2.5 具備視覺理解能力。如果經常需要處理圖片,直接切換到這些模型是最簡單、推薦的做法。
|
工具 |
模型切換方式 |
|
Claude Code |
|
|
OpenCode |
|
|
Qwen Code |
|
更多編程工具中的模型切換方式請參考接入用戶端/開發工具。切換後可直接在對話中引用圖片路徑,或拖拽/粘貼圖片。
方法 2:通過 Skill 或 Agent 添加視覺能力
如需使用 glm-5、MiniMax-M2.5 等不支援視覺的模型處理圖片,可通過配置 Skill 或 Agent 實現。
Claude Code
-
添加 Skill
在專案目錄下的
.claude檔案夾中建立skills/image-analyzer目錄:mkdir -p .claude/skills/image-analyzer在該目錄下建立
SKILL.md檔案,並寫入以下內容:--- name: image-analyzer description: 協助沒有視覺能力的模型進行映像理解。當需要分析映像內容、提取圖片中的資訊、文字、介面元素,或理解截圖、圖表、架構圖等任何視覺內容時,使用此技能,傳入圖片路徑即可獲得描述資訊。 model: qwen3.6-plus --- qwen3.6-plus具有視覺理解能力,請直接使用qwen3.6-plus模型進行圖片理解。建立完成後的目錄結構如下:
.claude/ └── skills/ └── image-analyzer/ └── SKILL.md -
開始使用
-
在專案目錄下運行
claude啟動 Claude Code,並運行/model glm-5切換到glm-5模型。 -
下載alibabacloud.png到專案目錄下,並提問:
Load image-analyzer skill and describe the information displayed at the alibabacloud.png banner location.可收到如下回複: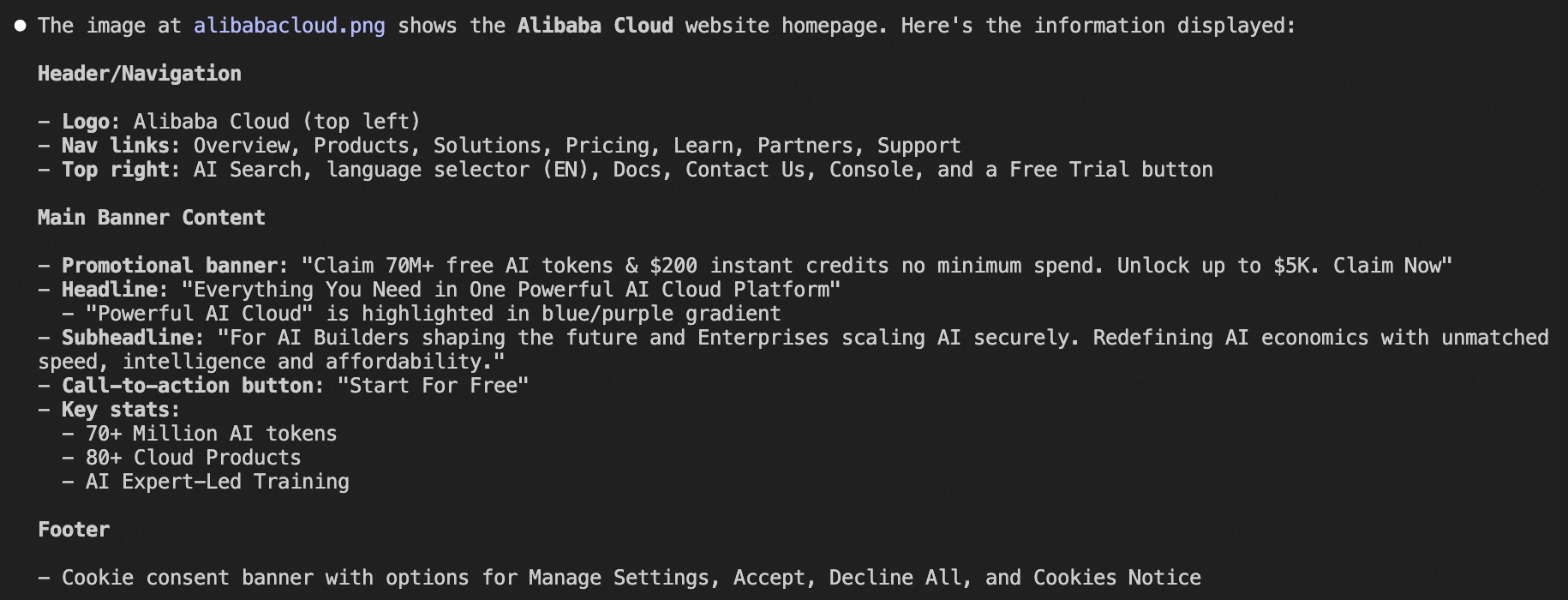
-
{kind=link}
OpenCode
-
添加 Agent
在專案目錄下的
.opencode檔案夾中建立agents目錄:mkdir -p .opencode/agents在該目錄下建立
image-analyzer.md檔案,並寫入以下內容:說明model 欄位必須使用 OpenCode 設定檔中定義的 provider 和模型名稱。參考 OpenCode 文檔的配置樣本,應為
bailian-coding-plan/qwen3.6-plus。--- description: Analyzes images using a vision-capable model. Use this agent when the user needs to understand image content, extract information from screenshots, diagrams, UI mockups, or any visual content. Invoke with @image-analyzer followed by the image path and your question. mode: subagent model: bailian-coding-plan/qwen3.6-plus tools: write: false edit: false --- You have vision capabilities. Analyze the provided image and return a clear, structured description focused on what the user is asking about.建立完成後的目錄結構如下:
.opencode/ └── agents/ └── image-analyzer.md -
開始使用
-
在專案目錄下運行
opencode啟動 OpenCode,並切換到glm-5模型。 -
下載alibabacloud.png到專案目錄下,通過
@喚起image-analyzer並提問:@image-analyzer describe the information displayed at the alibabacloud.png banner location.可收到如下回複:
-