在使用向量計算功能之前,您需要安裝Proxima CE包,本文為您介紹Proxima CE的環境準備、安裝包擷取方式、上傳及輸入資料準備等過程。
前提條件
請確保已完成環境準備。
擷取Proxima CE安裝包
請單擊Proxima CE包下載安裝包。
Proxima CE安裝包主要包含Proxima CE可執行JAR包,您能夠以添加MaxCompute資源的方式將其上傳到MaxCompute Project,然後調用可執行JAR包運行Proxima CE任務。
將安裝包上傳為MaxCompute資源
您可以通過MaxCompute用戶端(odpscmd)或者DataWorks將上述已下載的安裝包上傳至MaxCompute Project。本文以DataWorks為例為您介紹如何上傳並發布資源。odpscmd上傳資源的方式可以參考添加資源。
在DataWorks的資料開發頁面,通過可視化方式將安裝包上傳為JAR資源。
說明通過DataWorks可視化方式建立或上傳的資源:
若資源未在MaxCompute(ODPS)用戶端上傳過,則需勾選上傳為ODPS資源,若資源已上傳至MaxCompute(ODPS)用戶端,則需取消勾選上傳為ODPS資源,否則上傳均會報錯。
若上傳時勾選了上傳為ODPS資源,則上傳後在DataWorks和MaxCompute中均會儲存該資源。後續若通過命令列刪除MaxCompute中的資源,DataWorks中的資源仍然存在且正常顯示。
資源名稱無需與上傳的檔案名稱保持一致。
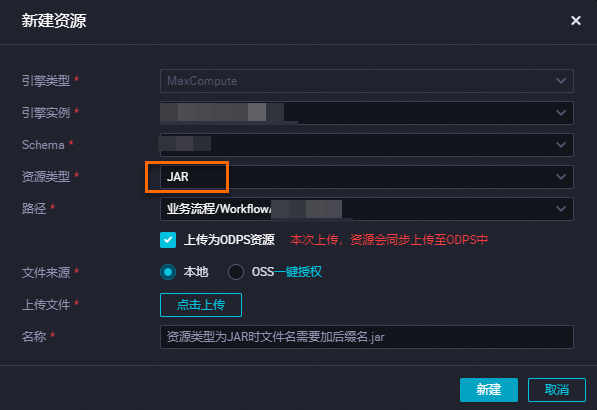
提交並發布資源。
資源建立完成後,您需在資源編輯頁面,單擊工具列中的
 表徵圖,提交資源至調度程式開發伺服器端。說明
表徵圖,提交資源至調度程式開發伺服器端。說明若生產任務需使用該資源,則還需將該資源發布至生產環境。詳情請參見發布任務。
準備輸入表
在運行之前,您需要準備如下兩個輸入表:
doc表:底庫資料表。
query表:使用者查詢表。
建表命令
--建立doc表
CREATE TABLE doc_table_float_smoke(pk STRING,vector STRING <,category BIGINT>) PARTITIONED BY (pt STRING);
--建立query表
CREATE TABLE query_table_float_smoke(pk STRING,vector STRING <,category BIGINT>) PARTITIONED BY (pt STRING);輸入表格式要求
表名
輸入表的表名不能包含
tmp_字串,否則會導致任務運行失敗。輸入表的表名和分區值的字元長度不能超過64,否則會導致任務運行失敗。
欄位
說明輸入表中需包含下述固定欄位,且欄位名稱必須完全一致。
固定欄位
欄位說明
欄位資料類型
pk
查詢時的pk值欄位(主鍵)。
預設為STRING類型。
對於pk列:其具體的值可以是數值或者字串(比如:字串類型
1.nid,2.nid,3.nid,...或INT64數實值型別123,456,789,...)。對於pk列:如果存的都是INT64數值,列的類型可以指定為BIGINT類型,同時若指定啟動參數
-pk_type為INT64,則能夠提升效能。
vector
向量欄位。
預設為STRING類型。
category
多類目的類目欄位。
僅多類目檢索時需要此欄位。
預設為BIGINT類型。
pt
分區欄位。
預設為STRING類型。
輸入表示例
doc表
pk
vector
pt
id1
0~1~1~5
20190322
id2
0~1~1~2
20190322
id3
3~2~1~1
20190322
...
...
...
query表
pk
vector
pt
id8
0~1~1~5
20190322
id9
0~1~1~2
20190322
id10
3~2~1~1
20190322
...
...
...
下一步:使用向量檢索功能
檢索情境 | 關鍵特性 | 指導文檔 |
基礎向量檢索 | 支援百萬層級TopK查詢。 | |
多類目檢索 | 支援多類目情境,包括query和doc屬於多個類目的情境以及單個query屬於多個類目的情境。 | |
聚類分區 | 支援聚類分區索引構建方式,該方式能夠減小計算量和加速後續索引查詢過程。 | |
內積和餘弦距離 | 支援內積檢索。 | |
量化使用 | 支援量化器使用,一般配置量化器可提升效能,減少索引大小,召回視情況有所損失。 |
使用向量檢索後會自動產生一張輸出表,儲存在MaxCompute表中,您無需建立,在運行Proxima CE代碼的-output_table參數後面指定表名即可使用。產生的輸出表格式請參考下文的輸出表格式說明。
輸出表格式說明
運行向量檢索後會自動產生一張輸出表,並儲存在MaxCompute表中,產生的輸出表格式如下。
表名:即您在運行Proxima CE的代碼中所指定的輸出表的表名。
輸出表的表名不能使用半形點號
.,其為MaxCompute的特殊字元,會導致MaxCompute表解析失敗。輸出表的表名不能包含
tmp_字串,會導致任務運行失敗。輸出表名和分區名的字元長度不能超過64,否則會導致任務運行失敗。
欄位
固定欄位
欄位說明
欄位的資料類型
pk
query表中每個query對應的pk值。
預設為STRING類型。
pk列的具體值可以是數值或者字串(比如字串類型
1.nid,2.nid,3.nid,...或INT64數實值型別123,456,789,...)。如果pk列儲存的均為INT64數值,可以將列類型指定為BIGINT類型,同時若指定啟動參數
-pk_type為INT64,可提升效能。
knn_result
query召回對應的doc表中的pk值。
預設為STRING類型。
score
召回的doc對應的相似性分數。
預設為STRING類型。Proxima CE中統一按照相似性大小降序排序。
說明分數對於
inner_product/mips_squared_euclidean兩種距離演算法在Proxima2核心裡是距離越大越相似,其他距離演算法是距離越小越相似,但Proxima CE中進行了統一處理,按照相似性大小降序排序,即:對於
inner_product/mips_squared_euclidean距離,按照score值降序排序;對於其他距離,按照
score值升序排序,與Proxima2核心保持一致。
category
多類目的類目欄位。
僅多類目檢索時需要此欄位。
預設為BIGINT類型。
pt
分區欄位。
預設為STRING類型。
輸出表示例
pk | knn_result | score | pt |
id8 | id1 | 0.1 | 20190322 |
id8 | id2 | 0.2 | 20190322 |
id9 | id1 | 0.1 | 20190322 |
id9 | id3 | 0.3 | 20190322 |
... | ... | ... | ... |