Proxima CE支援使用聚類分區方式檢索任務,本文為您介紹聚類分區檢索功能的使用方法及樣本。
前提條件
已安裝Proxima CE包,詳情請參見安裝Proxima CE包。
基本原理
Proxima CE在檢索時有兩種劃分資料分區的方式:雜湊分區與聚類分區。您可以通過設定-sharding_mode參數來選擇具體的索引分區模式,值為hash時採用雜湊分區,值為cluster時採用聚類分區,當前預設採用雜湊分區。
雜湊分區:在構建索引時,對全量doc集合劃分,得到column_num個索引,檢索時每條query需要在所有索引分區中查詢,最後合并召回結果。
聚類分區:核心思路是先對doc進行聚類,將距離接近的doc劃分到同一索引分區中,檢索時根據query和聚類中心點的距離,選擇最近的部分中心點對應的索引分區進行檢索。
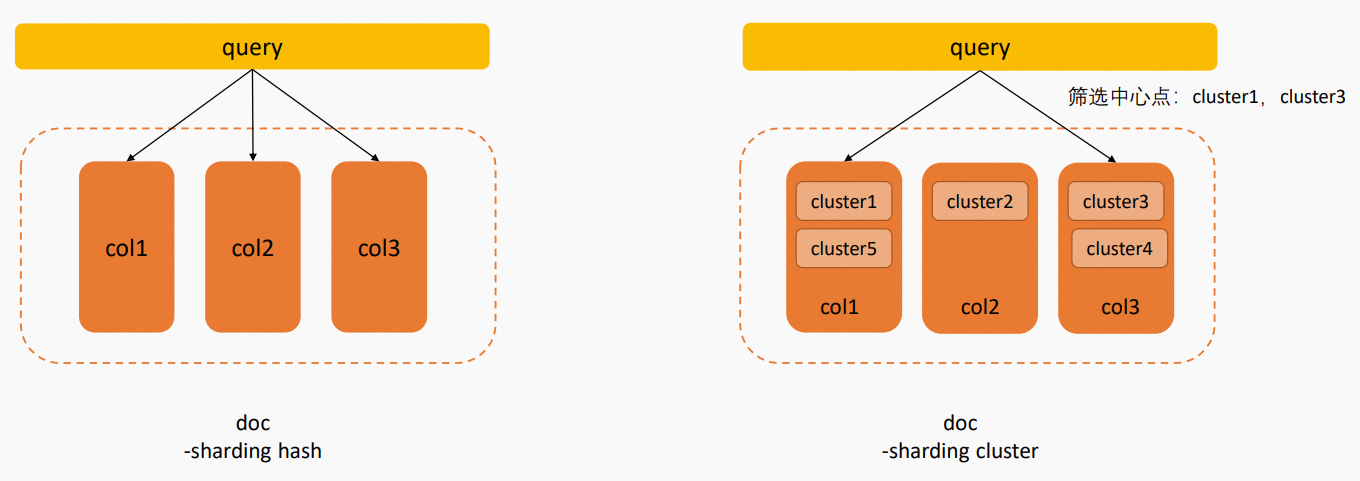
聚類分區劃分索引方式的目的是效能最佳化,查詢時避免查詢所有索引分區,只需要檢索部分索引分區就能儘可能召回最優結果。聚類分區劃分索引時包含如下兩個階段:
索引構建階段。
在構建索引時先對doc集合進行kmeans聚類,產生kmeans_cluster_num個中心點。
將kmeans_cluster_num個中心點,按照空間距離劃分成column_num個集合,可以理解為將中心點分配到column_num個索引中。
在對doc集合進行劃分時,將doc劃分到距離該doc最近的中心點對應的索引分區中。
索引查詢階段。
query先和所有中心點計算距離。
根據kmeans_seek_ratio選擇一定比例的最近中心點對應的索引分區進行檢索。
對檢索的索引分區結果進行結果合并。
適用情境
聚類分區方式適用於資料量非常大的情況(十億資料量級),特別是query資料量極大的情境。
適用於構建一次索引,後續多次查詢該索引(即一次build,多次seek)的情境。
說明聚類索引分區劃分方法需要對doc集合進行kmeans聚類,產生時間消耗,並且由於只檢索了一部分索引分區,勢必會產生一定的召回損失,所以該方式不適用於所有向量檢索情境。
聚類分區不支援多類目檢索,距離函數不支援除歐式距離、漢明距離以外的其他距離公式。
使用邏輯
指定
-sharding_mode為cluster。在JAR命令的
-resources中添加聚類初始中心點表名稱。說明此處不是命令列參數,是JAR命令需要的參數。聚類初始中心點名稱為使用者自訂名稱,需要保持唯一,例如
foo_init_center_resource。運行Proxima CE時會建立對應的MaxCompute表格儲存體聚類中心點,由於MaxCompute資源的機制,需要使用者手動添加中心點表的具體表名。
-kmeans_resource_name參數值需要和-resources中保持一致。因程式無法直接擷取-resources的值,所以需要額外的-kmeans_resouce_name命令列參數來傳遞。其他參數非必選,可以參考選擇性參數中名稱以
kmeans_開頭的參數。
建立輸入表並匯入資料
您可以在DataWorks的SQL節點運行以下命令。
-- 備忘:origin_table 來自阿里某業務的 128 維 float 向量資料表
-- 準備 doc 表:
CREATE TABLE cluster_10kw_128f_doc(pk STRING, vector STRING) PARTITIONED BY (pt STRING);
ALTER TABLE cluster_10kw_128f_doc add PARTITION(pt='20221111');
INSERT OVERWRITE TABLE cluster_10kw_128f_doc PARTITION (pt='20221111') SELECT pk, vector FROM origin_table WHERE pt='20221111';
-- 準備 query 表:
CREATE TABLE cluster_10kw_128f_query(pk STRING, vector STRING) PARTITIONED BY (pt STRING);
ALTER TABLE cluster_10kw_128f_query add PARTITION(pt='20221111');
INSERT OVERWRITE TABLE cluster_10kw_128f_query PARTITION (pt='20221111') SELECT pk, vector FROM origin_table WHERE pt='20221111';使用DataWorks運行
本文以DataWorks運行方式為例,假設已提前建立好了External Volume。
下述範例程式碼中所使用的參數配置,詳情請參見參考:Proxima CE全量參數說明。
命令如下:
--@resource_reference{"proxima-ce-aliyun-1.0.0.jar"}
jar -resources proxima-ce-aliyun-1.0.0.jar -- 上傳的 proxima-ce jar 包
-classpath proxima-ce-aliyun-1.0.0.jar com.alibaba.proxima2.ce.ProximaCERunner -- classpath 指定 main 函數入口類
-doc_table cluster_10kw_128f_doc
-doc_table_partition 20221111
-query_table cluster_10kw_128f_query
-query_table_partition 20221111
-output_table cluster_10kw_128f_output
-output_table_partition 20221111
-algo_model hnsw
-data_type float
-pk_type int64
-dimension 128
-column_num 50
-row_num 50
-vector_separator ,
-topk 1,50,100,200 -- 擷取 topk 為 1/50/100/200 時各自的召回率
-job_mode train:build:seek:recall
-- -clean_build_volume true -- 保留索引,後續多次運行時可以設定該選項為 true,此時需要設定 job_mode 為 `seek(:recall 可選)` 模式
-external_volume_name udf_proxima_ext
-sharding_mode cluster
-kmeans_resource_name kmeans_center_resource_xxx -- 手動指定 kmeans 資源名稱,這裡的命名樣本為 `kmeans_center_resource_xxx`
-kmeans_cluster_num 1000
-- -kmeans_sample_ratio 0.05 -- 使用預設參數
-- -kmeans_seek_ratio 0.1 -- 使用預設參數
-- -kmeans_iter_num 30 -- 使用預設參數
-- -kmeans_init_center_method "" -- 使用預設參數
-- -kmeans_worker_num 0 -- 使用預設參數
;運行結果
因輸出表資料量較大,此處只給出實際的作業記錄,不再列舉具體的結果表,表的Schema與運行結果相同。
向量檢索 資料類型:4 , 向量維度:128 , 檢索方式:HNSW , 計算方法:SquaredEuclidean , 構建模式:train:build:seek:recall
doc表資訊 表名: cluster_10kw_128f_doc , 分區:20221111 , doc數量:100000000 , 向量分隔字元:,
query表資訊 表名: cluster_10kw_128f_query , 分區:20221111 , query數量:100000000 , 向量分隔字元:,
輸出表資訊 表名: cluster_10kw_128f_output , 分區:20221111
行列資訊 行數: 50 , 列數:50 , 每列索引doc數量:2000000
是否清除Volume索引:true
各個worker的耗時(單位:秒):
SegmentationWorker: 3
TmpTableWorker: 1
KmeansGraphWorker: 2243
BuildJobWorker: 4973
SeekJobWorker: 5922
TmpResultJoinWorker: 0
RecallWorker: 986
CleanUpWorker: 6
總耗時(單位:分鐘):235
實際召回率
Recall@1: 0.999
Recall@50: 0.9941600000000027
Recall@100: 0.9902300000000046
Recall@200: 0.9816199999999914