本文為您介紹任務運行失敗的報錯資訊及解決方案。
Seek階段pk重複導致運行失敗
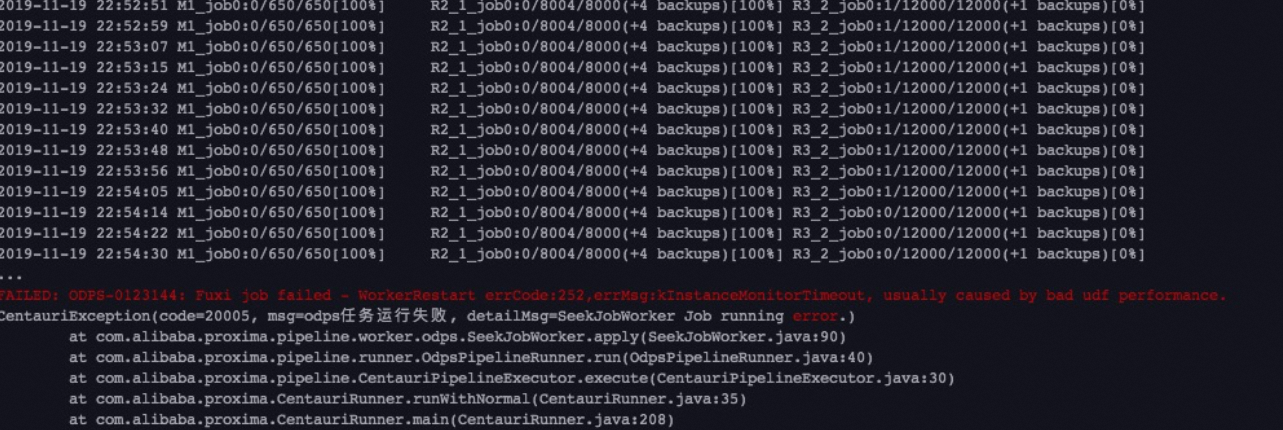
報錯資訊
解決方案
開啟運行MaxCompute任務的Logview,並查看StdOut中的值。Loview使用方法請參考使用Logview查看作業運行資訊。
 如果該執行個體的record number比其它執行個體大很多,請檢查資料是否存在pk相同、但value不同的vector。此種情況是資料沒有去重,在資料庫當中有pk相同,但是向量不同的資料。在seek階段M-R1-R2的R1到R2的過程,會將這些資料交給同樣的Reducer去執行,導致資料扭曲,造成某個Reduce Job掛掉。
如果該執行個體的record number比其它執行個體大很多,請檢查資料是否存在pk相同、但value不同的vector。此種情況是資料沒有去重,在資料庫當中有pk相同,但是向量不同的資料。在seek階段M-R1-R2的R1到R2的過程,會將這些資料交給同樣的Reducer去執行,導致資料扭曲,造成某個Reduce Job掛掉。
小類目檢索準備階段GetSmallCategoryDocNum為空白
報錯資訊

解決方案
該問題的主要原因是表當中某些欄位的值為空白,比如category列的值為空白或者pk列的值為空白,建議通過SQL將這些空值對應的record刪除。
小類目檢索階段schema validation不匹配
報錯資訊
2020-07-28 16:58:15.221 [main] INFO p.a.p.p.ProximaCEPipelineExecutor - [] - execute SmallCategorySeek worker start .......... [400] com.aliyun.odps.OdpsException: ODPS-0420031: Invalid xml in HTTP request body - The request body is malformed or the server version doesn't match this sdk/client. XML Schema validation failed: Element 'Value': [facet 'maxLength'] The value has a length of '4952955'; this exceeds the allowed maximum length of '2097152'. Element 'Value': '{"MaxCompute.pipeline.0.output.key.schema":"instId:BIGINT,type:BIGINT,pk:STRING,category:BIGINT","MaxCompute.pipeline.0.output.value.schema":"v解決方案
表明doc表中的類目數量太多,需要按類目拆分成多個表。
解析表資料時出現“-nan”錯誤
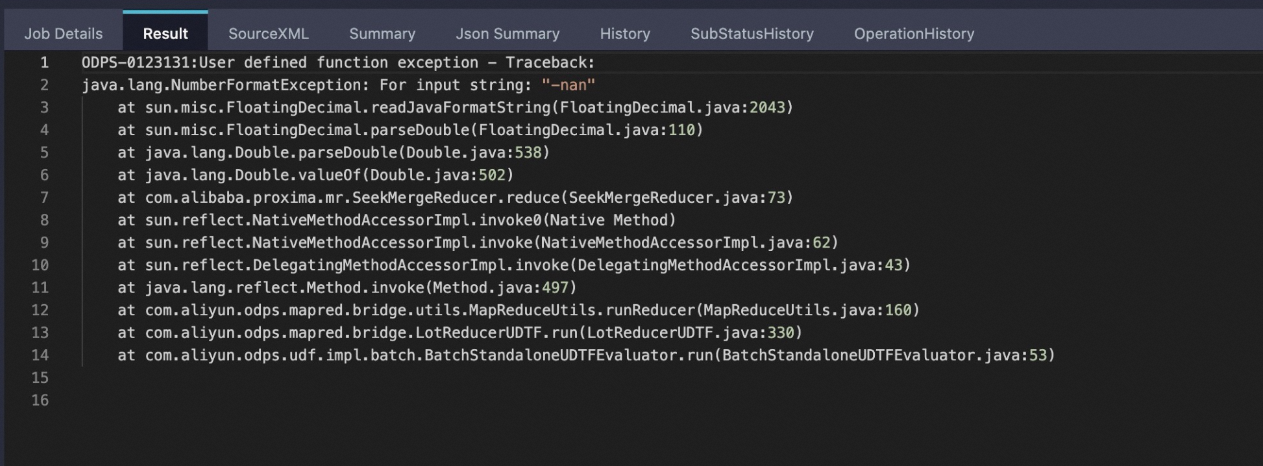
報錯資訊
解決方案
該問題一般是原始doc或query表輸入的格式有問題,可能存在很大的值或者接近0的值。例如某一行vector下的值為
1.23~4.56~7.89~nan~4.21或1.1~2.2~127197893781729178311928739179222121.23128767846816278193456789087654~ 0.000000000000000000000000000000000000000001~5.5,會導致在數值計算時溢出或者出現除零錯誤。可以嘗試使用MaxCompute的SQL UDF過濾出doc表和query表中的問題資料。
多類目情況下,某個類目doc數目為0,query數目不為0導致的jni調用異常
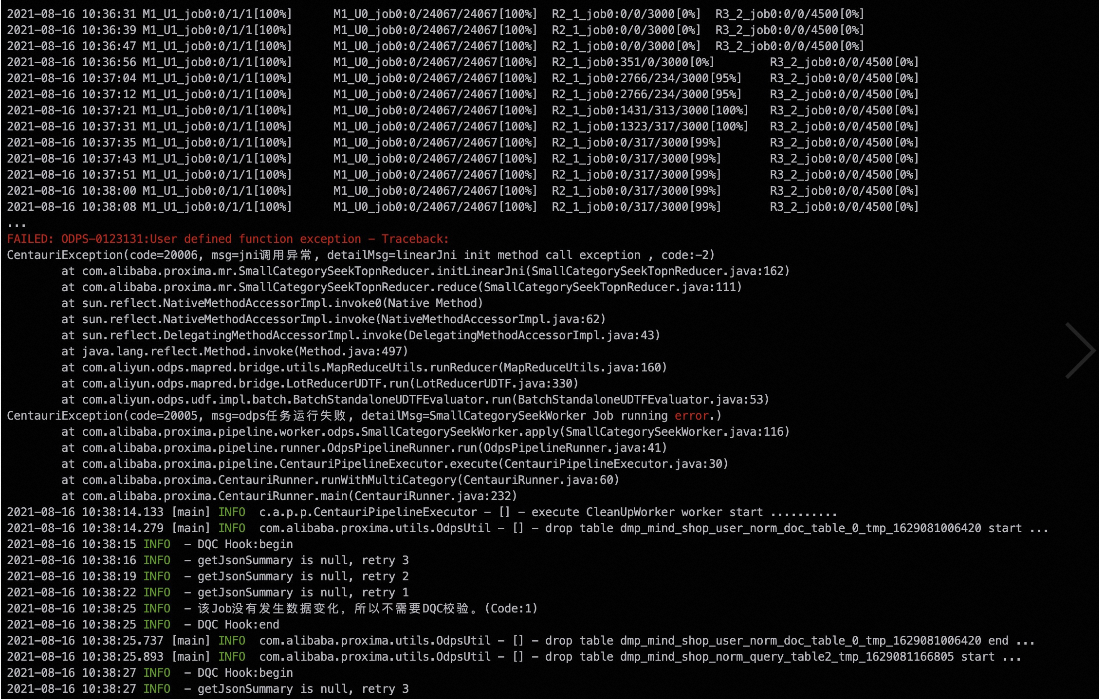
報錯資訊
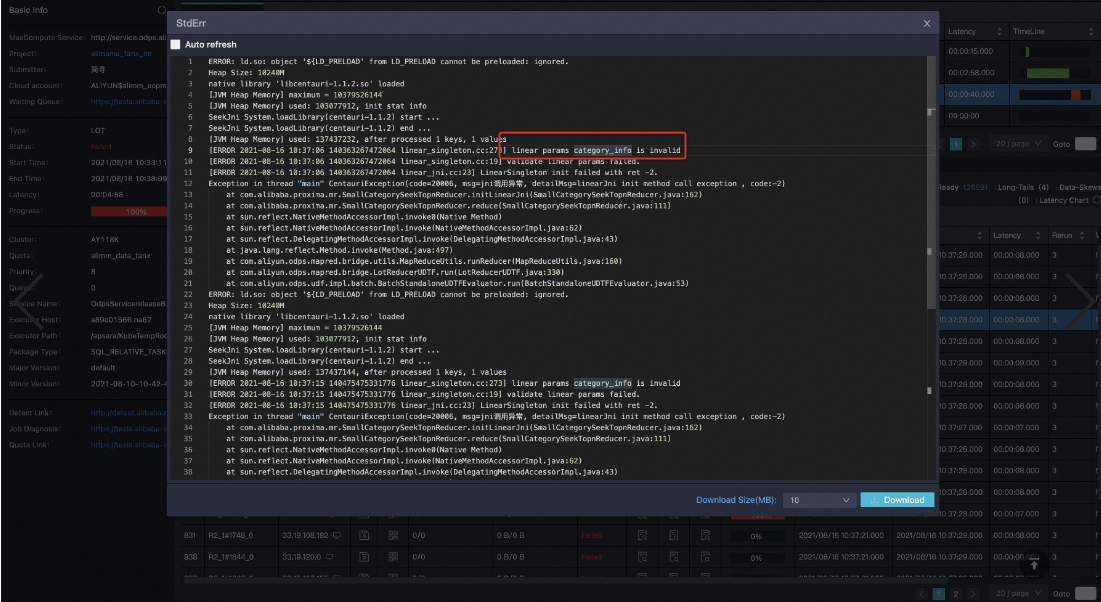
解決方案
這種情況被認為是使用者輸入問題,在設計時發現這樣的情況時通過報錯終止來提示使用者,而不是忽略。這樣做防止使用者需要某個類目的召回結果,但是最終沒有召回,如果忽略將會導致隱形Bug。解決方案是剔除query或doc表中記錄為0的對應類目,因為空白記錄的召回無論是doc還是query都是無實際意義的。
MaxCompute Tunnel Endpoint問題
報錯資訊
建立DownloadSession失敗 ErrorCode=Local Error, ErrorMessage=Failed to create download session with tunnel endpoint解決方案
該問題的主要是Proxima CE內部調用MaxCompute關於Tunnel的某些介面失敗導致的,存在的原因有:
網路問題,重試即可。
跨網路訪問。Tunnel Endpoint設定錯誤導致的讀取MaxCompute table count失敗。詳情參考Tunnel命令常見問題 。使用者可以通過添加啟動參數-tunnel_endpoint指定有效Tunnel Endpoint重新運行。
運行過程中MapReduce裡的java NPE (java.lang.NullPointerException) 問題
報錯資訊
error example1:
setKey()導致。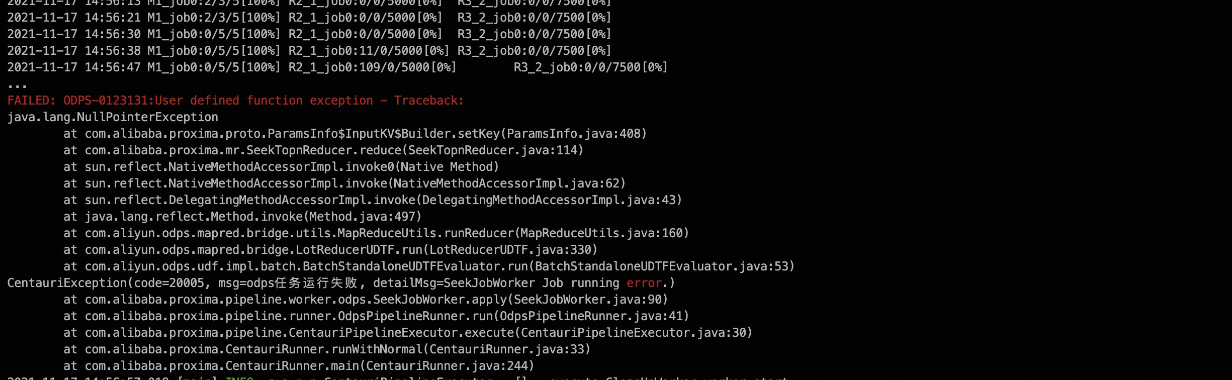
error example2:
VectorConvert.convert()導致。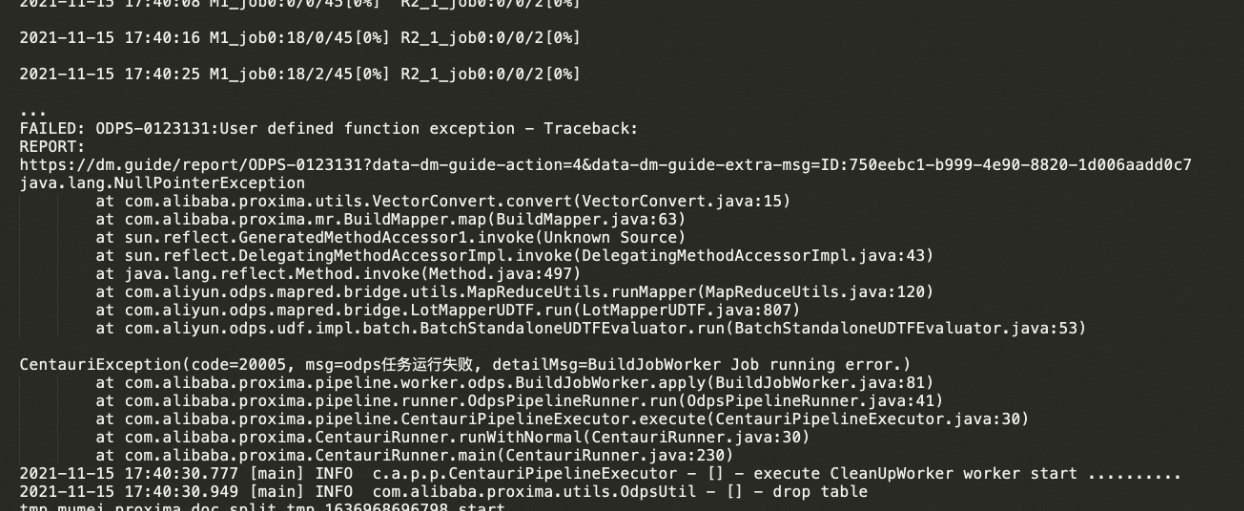
error example3:
getInputVolumeFileSystem()導致。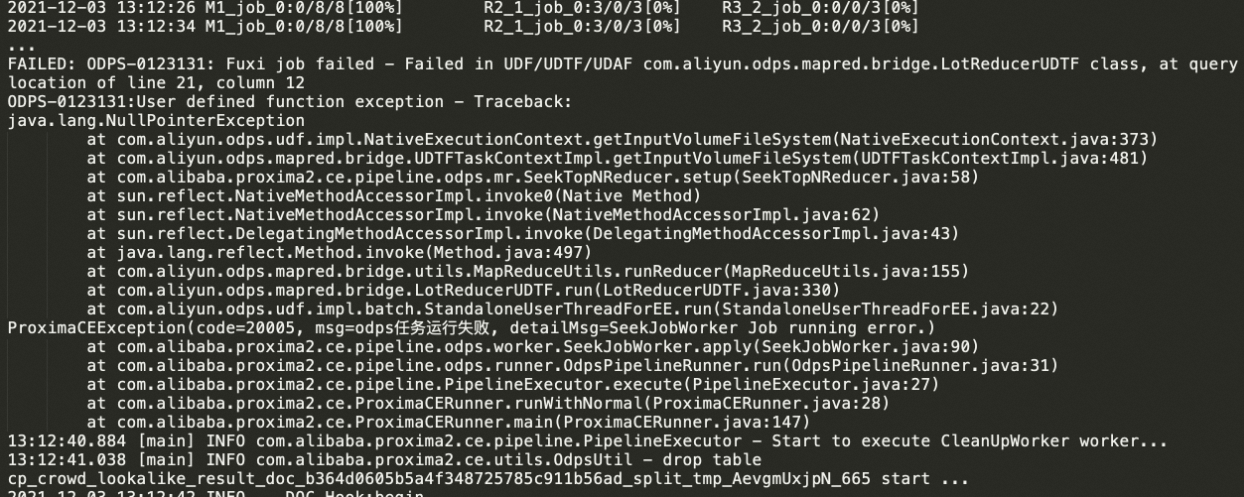
解決方案
對於error example1和error example2:一般是由於在build或seek階段,MR任務讀取輸入表中的某一列時失敗導致,可能的原因有:
該列不存在。
該列下存在某行值為null。
該列下存在某行值不合法,導致解析錯誤。
一般在build階段失敗需要檢查doc表是否存在上述問題,在seek階段失敗需要檢查query表是否存在上述問題,build/seek階段區分如下:
build階段是由Mapper-Reducer構成的MR任務,通常在日誌裡如上述error example2的輸出。
seek階段是由Mapper-Reducer1-Reducer2構成的MRR任務,通常在日誌裡如上述error example1的輸出。
對於error example3:一般是由於在seek階段Mapper任務擷取MaxCompute Volume時出現錯誤,找不到對應的Volume及對應的 Volume Partition,主要原因可能有:
同一時間運行多個具有相同輸入doc表的任務,最後作業記錄會報如圖所示錯誤。對於目前的版本Proxima CE,對索引的分區是依賴輸入的doc表名和分區名的,因此同時跑多個任務時,如果doc表相同,會出現多個任務對同一個Volume下的索引檔案有覆蓋甚至刪除的錯誤,導致讀取MaxCompute Volume失敗,類似的也會導致索引載入失敗。可以通過調整任務的輸入doc表名不同,保證每個任務的正常運行。
行列設定有問題。MaxCompute目前支援reducer執行個體最多為99999個,如果使用者佈建的-column_num和-row_num過大,會導致seek階段MRR任務的執行個體個數(
執行個體個數 = column_num * row_num)超過限制,這樣會導致不可控的錯誤,使得seek階段的reducer無法找到正確的索引Volume。可以通過使用合理的行列值來保證,詳情請參考聚類分區。
getPartitionColumn擷取分區列pt出錯
報錯資訊
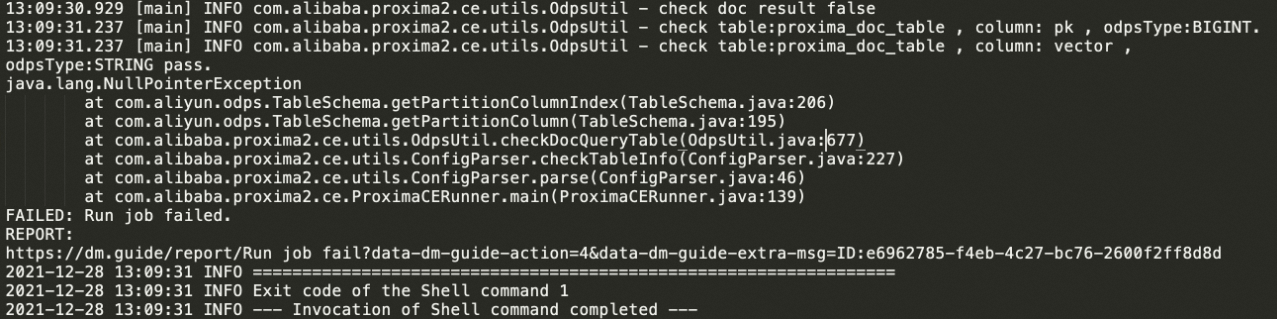
解決方案
一般這種情況是沒有檢查到
pt列,目前doc_table和query_table強制規定了表的schema,其中規定partition列為STRING類型的pt列,詳情請參考匯入輸入表資料。另外pt列必須指定為分區列,如果是普通列也會出現同樣的錯誤。
報錯ShuffleServiceMode: Dump checkpoint failed
報錯資訊
0010000:System internal error - fuxi job failed, caused by: ShuffleServiceMode: Dump checkpoint failed解決方案
該問題一般是單個執行個體output size超限導致的,即MR處理過程中,單個Mapper或Reducer執行個體的輸出超過限制(400 GB)。原因為單個執行個體處理的資料過大,或者Mapper或Reducer內部邏輯導致資料膨脹過大。可以通過指定-mapper_split_size參數調低單個Mapper切分的資料大小來解決,單位為MB。
FAILED: MaxCompute-0430071: Rejected by policy - rejected by system throttling rule
報錯資訊
FAILED: MaxCompute-0430071: Rejected by policy - rejected by system throttling rule解決方案
這種情況是MaxCompute系統限流,任務的執行請求被拒絕,有可能是叢集在執行其他任務(例如:壓測任務),也有可能是為了安全保障某段時間內禁止使用者執行任務。一般過段時間重跑任務即可,具體時間可以詢問Project Owner或Project叢集所在負責人。
因讀表失敗導致的 java.lang.ArrayIndexOutOfBoundException
報錯資訊
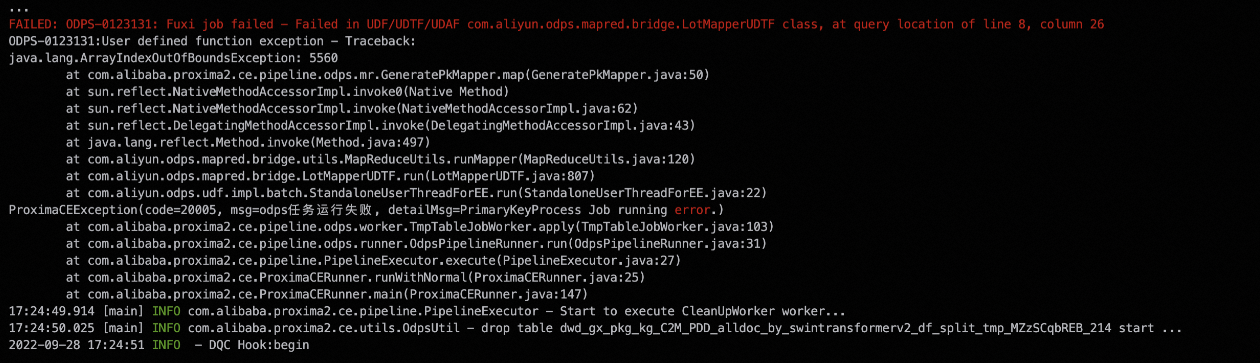
解決方案
這種情況的原因通常是內部Mapper任務
GeneratePkMapper依賴讀取的一個數組長度未擷取到正確資料,通常情況該數組長度是前序的SQL任務通過讀表擷取的,一般是因為讀表失敗導致的。逾時:由於Project所在叢集網路波動導致,一般重試幾次或者過段時間重跑即可。

Tunnel Exception:Proxima CE內部讀表時會通過Tunnel擷取表記錄,因此Tunnel失敗也會導致讀表失敗,Tunnel錯誤可以參考MaxCompute Tunnel Endpoint問題。
運行聚類分區時,遇到Timeout問題
報錯資訊
FAILED: ODPS-0010000:System internal error - Timeout when graph master wait all workers start java.io.IOException: Job failed! at com.aliyun.odps.graph.GraphJob.run(GraphJob.java:429) at com.alibaba.proxima2.ce.pipeline.odps.worker.KmeansGraphJobWorker.apply(KmeansGraphJobWorker.java:131) at com.alibaba.proxima2.ce.pipeline.odps.runner.OdpsPipelineRunner.run(OdpsPipelineRunner.java:31) at com.alibaba.proxima2.ce.pipeline.PipelineExecutor.execute(PipelineExecutor.java:27) at com.alibaba.proxima2.ce.ProximaCERunner.runWithNormal(ProximaCERunner.java:28) at com.alibaba.proxima2.ce.ProximaCERunner.main(ProximaCERunner.java:149)解決方案
聚類分區在構建索引時,首先會基於Graph引擎做資料聚類,具體是執行對應的GraphJob來完成,GraphJob會預設申請一個Worker數量,當叢集資源不足時會出現上述問題。可以在執行命令裡限定執行GraphJob的Worker數量來限制資源申請。在Proxima CE的啟動命令前設定參數:
set odps.graph.worker.num=400; -- 400 是執行個體說明,具體數量根據叢集資源設定完整命令如下:
set odps.graph.worker.num=400; jar -resources kmeans_center_resource_cl,proxima-ce-aliyun-1.0.0.jar -classpath http://schedule@{env}inside.cheetah.alibaba-inc.com/scheduler/res?id=251678818 com.alibaba.proxima2.ce com.alibaba.proxima2.ce.ProximaCERunner -doc_table doc_table_pailitao -doc_table_partition 20210707 -query_table query_table_pailitao -query_table_partition 20210707 -output_table output_table_pailitao_cluster_2000w -output_table_partition 20210707 -data_type float -dimension 512 -oss_access_id xxx -oss_access_key xxx -oss_endpoint xxx -oss_bucket xxx -owner_id 123456 -vector_separator blank -pk_type int64 -row_num 10 -column_num 10 -job_mode build:seek:recall -topk 1,50,100,200 -sharding_mode cluster -kmeans_resource_name kmeans_center_resource_cl -kmeans_cluster_num 1000;