自3.3.13-1.0.0版本起,StarRocks支援全文倒排索引功能。該功能對文本中的每個單詞進行分詞處理,並為每個詞建立相應的索引項目,以記錄該單詞與其所在資料檔案行號之間的映射關係。在進行全文檢索索引時,StarRocks將根據查詢的關鍵詞對倒排索引進行訪問,從而快速定位與關鍵詞匹配的資料行。
使用限制
僅支援3.3.13-1.0.0及以上版本的執行個體。
僅支援明細表和主鍵表。
僅支援為CHAR、VARCHAR和STRING類型建立倒排索引。
在存算一體執行個體中使用時,需要設定表屬性
replicated_storage=false。
建立全文倒排索引
在StarRocks控制台的參數配置頁簽,設定FE配置項
enable_experimental_gin為true,以啟用全文倒排索引。在SQL Editor頁簽中,根據建表情況選擇建立全文倒排索引。
方式一:建表時建立
以下以存算一體執行個體為例,基於列
v構建全文倒排索引並且使用英文分詞。CREATE TABLE `t` ( `k` BIGINT NOT NULL COMMENT "", `v` STRING COMMENT "", INDEX idx (v) USING GIN("parser" = "english") ) ENGINE=OLAP DUPLICATE KEY(`k`) DISTRIBUTED BY HASH(`k`) BUCKETS 1 PROPERTIES ( "replicated_storage" = "false" );方式二:建表後建立
通過
ALTER TABLE ADD INDEX添加全文倒排索引ALTER TABLE t ADD INDEX idx (v) USING GIN('parser' = 'english');通過
CREATE INDEX添加全文倒排索引CREATE INDEX idx ON t (v) USING GIN('parser' = 'english');
全文倒排索引的基本文法如下所示。
INDEX <index name>(<column name>) USING GIN(properties)涉及參數如下所示。
參數
說明
<index_name>自訂的索引名稱。
<column_name>需要建立索引的列名。
USING GIN指定索引類型為GIN(Generalized Inverted Index),即倒排索引。
properties索引的配置參數,通常以索引值對的形式提供。支援以下屬性:
parser:用於指定分詞的方式。支援的值如下:none:預設值,表示不進行任何分詞操作。english:使用CLucene的Simple Analyzer進行分詞,適用於英文文本的分詞,並且不區分大小寫。chinese:使用CLucene的CJK Analyzer進行分詞,適用中文分詞。standard:使用CLucene的Standard Analyzer進行分詞,適用於大多數分詞方式,並且不區分大小寫。
omit_term_freq_and_position:用於指定在構建倒排索引時是否忽略詞頻和詞的位置,以降低儲存使用。預設為false,設定為true時不支援匹配短語(MATCH_PHRASE)。
查看全文倒排索引
執行以下命令,查看全文倒排索引。
SHOW CREATE TABLE testdb.`t`;在輸出結果地區,右鍵並預覽Create Table列的資訊。
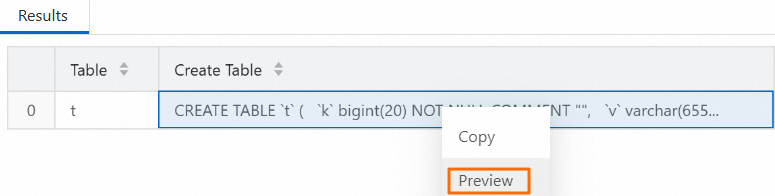
本文樣本展示以下資訊。
CREATE TABLE `t` ( `k` bigint(20) NOT NULL COMMENT "", `v` varchar(65533) NULL COMMENT "", INDEX idx (`v`) USING GIN("parser" = "english") COMMENT '' ) ENGINE=OLAP DUPLICATE KEY(`k`) DISTRIBUTED BY HASH(`k`) BUCKETS 1 PROPERTIES ( "compression" = "LZ4", "fast_schema_evolution" = "true", "replicated_storage" = "false", "replication_num" = "3" );
刪除全文倒排索引
通過
ALTER TABLE DROP INDEX刪除ALTER TABLE t DROP index idx;通過
DROP INDEX刪除DROP INDEX idx on t;
使用全文倒排索引加速查詢
在使用該功能之前,請確保已將enable_gin_filter和enable_prune_column_after_index_filter兩個參數設定為true。如果未對這兩個參數進行修改,那麼預設值均為true。
如果全文倒排索引對索引列進行分詞處理,即'parser' = 'standard|english|chinese',此時查詢條件中僅支援使用謂詞MATCH通過全文倒排索引進行資料過濾,且格式必須為<col_name> (NOT) MATCH '%keyword%'。在此,keyword必須為字串字面量,不支援使用運算式。
建立表示例
create database testdb;
CREATE TABLE testdb.`http_logs` (
`@timestamp` int(11) NULL COMMENT "",
`clientip` varchar(20) NULL COMMENT "",
`request` varchar(65533) NULL COMMENT "",
`status` int(11) NULL COMMENT "",
`size` int(11) NULL COMMENT "",
INDEX request_idx (`request`) USING GIN("parser" = "english") COMMENT ''
) ENGINE=OLAP
DUPLICATE KEY(`@timestamp`)
COMMENT "OLAP"
DISTRIBUTED BY RANDOM BUCKETS 1
PROPERTIES ("replicated_storage" = "false");
insert into testdb.http_logs values
('893964617','40.135.*.*','GET /images/hm_bg.jpg HTTP/1.0',200,24736),
('893964653','232.0.*.*','GET /images/hm_bg.jpg HTTP/1.0',200,24736),
('893964672','26.1.*.*','GET /images/hm_bg.jpg HTTP/1.0',200,24736),
('893964679','247.37.*.*','GET /french/splash_inet.html HTTP/1.0',200,3781),
('893964682','247.37.*.*','GET /images/hm_nbg.jpg HTTP/1.0',304,0),
('893964687','252.37.*.0','GET /images/hm_bg.jpg HTTP/1.0',200,24736),
('893964689','247.37.*.*','GET /images/hm_brdl.gif HTTP/1.0',304,0),
('893964689','247.37.*.*','GET /images/hm_arw.gif HTTP/1.0',304,0),
('893964692','247.37.*.*','GET /images/nav_bg_top.gif HTTP/1.0',200,929),
('893964703','247.37.*.*','GET /french/images/nav_venue_off.gif HTTP/1.0',304,0);支援的查詢方式
StarRocks提供了多種基於全文倒排索引的查詢方式,適用於不同的情境:
MATCH/MATCH_ANY
語義:只要與拆分後的任意一個詞項(
term)匹配即可。樣本
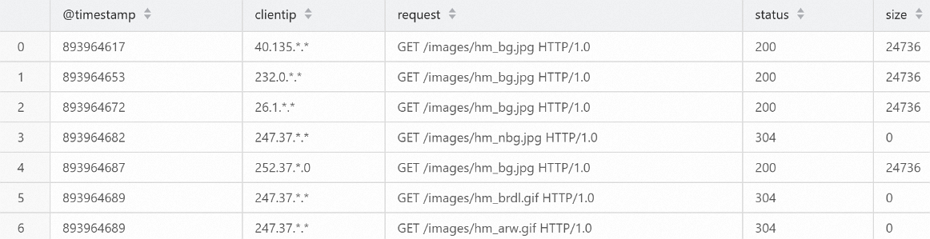
select * from testdb.http_logs where request match "images hm_bg";返回資訊如下所示。

MATCH_ALL
語義:所有拆分後的
term必須全部匹配。樣本
select * from testdb.http_logs where request match_all "images hm_bg";返回資訊如下所示。

MATCH_PHRASE
語義:短語匹配。要求所給查詢的所有解析後的詞項均需匹配,並且這些詞項的位置必須與文檔中的對應位置一致,方可成立匹配關係。
樣本
select * from testdb.http_logs where request match_phrase "GET /images";返回資訊如下所示。

MATCH_PHRASE_PREFIX
語義:首碼匹配。匹配所有以給定查詢作為首碼的欄位。
樣本
select * from testdb.http_logs where request match_phrase_prefix "GET /im";返回資訊如下所示。

MATCH_PHRASE_EDGE
語義:複雜匹配模式,支援前尾碼匹配和中間項匹配。
如果給出的查詢可以拆分為兩個或以上的詞項,則第一個詞項作為尾碼進行匹配,最後一個詞項作為首碼進行匹配,中間的所有詞項共同參與匹配。僅當所有詞項均匹配時,才能認為匹配成功。
樣本
select * from testdb.http_logs where request match_phrase_edge 'et images hm';返回資訊如下所示。
調試與驗證倒排索引
使用tokenize函數驗證分詞器行為
為了確保全文倒排索引的行為符合預期,StarRocks提供了tokenize函數,用於類比分詞器的行為並驗證分詞結果。該函數可以協助使用者檢查分詞器是否正確處理了輸入資料,從而最佳化查詢條件。
tokenize("<parser_type>", "<input_strings>");參數說明:
<parser_type>:分詞器類型,與倒排索引支援的parser一致。<input_strings>:需要分詞的字串或列名。
傳回值:返回一個數組(
ARRAY類型),數組中的每個元素是一個分詞後的單詞或term。
樣本用法
驗證分詞器行為
在建立倒排索引之前,可以通過
tokenize函數測試分詞器的行為,確保分詞結果符合預期。SELECT tokenize("english", "GET /images/hm_bg.jpg HTTP/1.0");返回結果如下所示。
["get","images","hm","bg","jpg","http","1","0"]調試查詢結果
如果查詢結果不符合預期,可以通過
tokenize函數檢查分詞器是否正確處理了輸入資料。假設表
http_logs的列request包含以下資料。GET /images/hm_bg.jpg HTTP/1.0 GET /french/splash_inet.html HTTP/1.0使用
tokenize驗證分詞結果。SELECT tokenize("english", request) FROM http_logs;返回資訊如下所示。
["get","images","hm","bg","jpg","http","1","0"] ["get","french","images","nav","venue","off","gif","http","1","0"]動態分詞處理
在查詢中直接對列內容進行分詞處理,適合臨時分析或調試情境,尤其是在未建立倒排索引時快速查看分詞結果。
SELECT `@timestamp`, tokenize("english", request) AS tokens FROM testdb.http_logs;